App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD GCN4 (Polaris, Radeon 400/500) & GCN5 (Vega)
- Ersteller BoMbY
- Erstellt am
Stefan Payne
Grand Admiral Special
BTW: Was ist eigentlich aus dem von NV versprochenen Async Patch geworden? Oder haben die neuen Karten alle geblitzdingst?
Was ist eigentlich aus dem von nVidia versprochenen DX12 Treiber für die Fermi Generation geworden?!
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 985
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS PRIME X370-PRO
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Den Vulkan-Support hat nVidia ebenfalls gestrichen. Für die gleichalte Radeon HD 5xxx Serie kommt leider auch nichts mehr dergestalt.[3DC]Payne;5093626 schrieb:Was ist eigentlich aus dem von nVidia versprochenen DX12 Treiber für die Fermi Generation geworden?!
Den Vulkan-Support hat nVidia ebenfalls gestrichen. Für die gleichalte Radeon HD 5xxx Serie kommt leider auch nichts mehr dergestalt.
IMHO hat AMD "neue APIs" nur ab GCN angekündigt.
Stefan Payne
Grand Admiral Special
Genau, AMD hat gleich gesagt, dass DX12/Vulkan erst ab GCN unterstützt wird und nix mehr für die 'Terrascale' Architektur kommt.
nVidia hat hingegen den DX12 Support für Fermi angekündigt!
Und genau so werden die aktuell auf Geforce.com beworben!
Da steht ganz klar, dass DX12 unterstützt wird, von Fermi.
Und wo ist jetzt der DX12 Treiber für Fermi?!
nVidia hat hingegen den DX12 Support für Fermi angekündigt!
Und genau so werden die aktuell auf Geforce.com beworben!
Da steht ganz klar, dass DX12 unterstützt wird, von Fermi.
Und wo ist jetzt der DX12 Treiber für Fermi?!
eratte
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 11.11.2001
- Beiträge
- 21.840
- Renomée
- 2.807
- Standort
- Rheinberg / NRW
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- YoYo, Collatz
- Lieblingsprojekt
- YoYo
- Meine Systeme
- Wegen der aktuellen Lage alles aus.
- BOINC-Statistiken

- Mein Laptop
- Lenovo ThinkPad E15 Gen4 Intel / HP PAVILION 14-dk0002ng
- Details zu meinem Desktop
- Prozessor
- Ryzen R9 7950X
- Mainboard
- ASUS ROG Crosshair X670E Hero
- Kühlung
- Noctua NH-D15
- Speicher
- 2 x 32 GB G.Skill Trident Z DDR5 6000 CL30-40-40-96
- Grafikprozessor
- Sapphire Radeon RX7900XTX Gaming OC Nitro+
- Display
- 2 x ASUS XG27AQ (2560x1440@144 Hz)
- SSD
- Samsung 980 Pro 1 TB & Lexar NM790 4 TB
- Optisches Laufwerk
- USB Blu-Ray Brenner
- Soundkarte
- Onboard
- Gehäuse
- NEXT H7 Flow Schwarz
- Netzteil
- Corsair HX1000 (80+ Platinum)
- Tastatur
- ASUS ROG Strix Scope RX TKL Wireless / 2. Rechner&Server Cherry G80-3000N RGB TKL
- Maus
- ROG Gladius III Wireless / 2. Rechner&Server Sharkoon Light2 180
- Betriebssystem
- Windows 11 Pro 64
- Webbrowser
- Firefox
- Verschiedenes
- 4 x BQ Light Wings 14. 1 x NF-A14 Noctua Lüfter. Corsair HS80 Headset .
- Internetanbindung
- ▼VDSL 100 ▲VDSL 100
Was hat das jetzt gleich nochmal mit dem Threadthema zutun?
BavarianRealist
Grand Admiral Special
- Mitglied seit
- 06.02.2010
- Beiträge
- 3.358
- Renomée
- 80
Irgendwie passen die bisher bekannten Performance-Daten von Polaris nicht zu den angeblichen technischen Daten:
@Anzahl CUs:
Wenn die GPU >230mm² ist, müsste sie dann nicht weit mehr als 40CU haben? Im 14nm-Prozess sollten die Shader kaum mehr als 50% der Fläche der 28nm-Shader verbrauchen. Weil aber die sonstigen Strukturen (Busse etc.) nicht wirklich mehr werden, müsste für die Shader zusätzliche Fläche frei werden... => könnte es sein, dass Polaris weit mehr als 36 Cluster, also womöglich 44 oder 48 CU besitzt?
@TDP:
Die Effizienz von Polaris vergleiche ich eher mit der Effizienz der CUs von Bristol-Ridge: der hat 8 CUs bei 758Mhz und dabei hat die ganze APU eine TDP=15 Watt, also die GPU vermutlich eher nur die Hälfte davon. Wenn die GPU von Bristol-Ridge etwa 0,7TFlop leistet, wären das grob abgeschätzt etwa 10 Watt pro 1TFlop.
Jetzt kommt Polaris aber im weit effizientern 14nm-Finfet-Prozess. Selbst wenn Polaris inkl. Rest immer noch 10Watt/1TFlop verbraucht, wären das gerade mal eine TDP<60Watt, wenn RX480 <6TFlop leistet.
=> Da passt nicht wirklich viel zusammen. Ebenso sind bisher nur Daten einer RX480 von AMD veröffentlicht worden, die weit billiger ist, als vorher angenommen! Wozu braucht AMD für eine RX480 mit den bisher vorgestellten Daten die maximale Leistung aus dem Polaris holen? Hat man womöglich erst mal einfach die kleine Variante vorgestellt? Könnte die größere dann einfach RX485 heißen?
Ergebnis:
Dass AMD für RX480 einfach mal TDP=150W schreibt, ergibt sich erst mal nur aus der Konfiguration mit dem Zusatzstecker, der eben maximal 150 Watt zulässt. Die RX480 mit <6TFlop sollte weit weniger als 150 Watt verbrauchen, oder?
Polaris-10 sollte in seinem Maximal-Ausbau bei TDP=150W weit mehr als 6TFlop ermöglichen: womöglich hat Polaris-10 mehr als 40CU und kann auch noch weit höher als 1266Mhz takten.
=> Kommt später eine stärkere RX485 mit Polaris-10?
--- Update ---
Ergänzung:
Wenn die neuen Polaris mindestens 2,5-mal so effizient wie die Vorgänger sein sollen, dann dürfte Polaris für die Leistung einer 390X (TDP=275W) kaum über 100 Watt verbrauchen. Vergleiche ich aber mit einer Fury-X, die ebenfalls nur TDP=275Watt hat, dann müsste Polaris-10 bei TDP=150Watt eine Fury-X in der Leistung übertreffen..., ganz zu schweigen, wenn man mit einer Nano vergleicht...
Polaris-10 sollte weit mehr als 6TFlops schaffen...
@Anzahl CUs:
Wenn die GPU >230mm² ist, müsste sie dann nicht weit mehr als 40CU haben? Im 14nm-Prozess sollten die Shader kaum mehr als 50% der Fläche der 28nm-Shader verbrauchen. Weil aber die sonstigen Strukturen (Busse etc.) nicht wirklich mehr werden, müsste für die Shader zusätzliche Fläche frei werden... => könnte es sein, dass Polaris weit mehr als 36 Cluster, also womöglich 44 oder 48 CU besitzt?
@TDP:
Die Effizienz von Polaris vergleiche ich eher mit der Effizienz der CUs von Bristol-Ridge: der hat 8 CUs bei 758Mhz und dabei hat die ganze APU eine TDP=15 Watt, also die GPU vermutlich eher nur die Hälfte davon. Wenn die GPU von Bristol-Ridge etwa 0,7TFlop leistet, wären das grob abgeschätzt etwa 10 Watt pro 1TFlop.
Jetzt kommt Polaris aber im weit effizientern 14nm-Finfet-Prozess. Selbst wenn Polaris inkl. Rest immer noch 10Watt/1TFlop verbraucht, wären das gerade mal eine TDP<60Watt, wenn RX480 <6TFlop leistet.
=> Da passt nicht wirklich viel zusammen. Ebenso sind bisher nur Daten einer RX480 von AMD veröffentlicht worden, die weit billiger ist, als vorher angenommen! Wozu braucht AMD für eine RX480 mit den bisher vorgestellten Daten die maximale Leistung aus dem Polaris holen? Hat man womöglich erst mal einfach die kleine Variante vorgestellt? Könnte die größere dann einfach RX485 heißen?
Ergebnis:
Dass AMD für RX480 einfach mal TDP=150W schreibt, ergibt sich erst mal nur aus der Konfiguration mit dem Zusatzstecker, der eben maximal 150 Watt zulässt. Die RX480 mit <6TFlop sollte weit weniger als 150 Watt verbrauchen, oder?
Polaris-10 sollte in seinem Maximal-Ausbau bei TDP=150W weit mehr als 6TFlop ermöglichen: womöglich hat Polaris-10 mehr als 40CU und kann auch noch weit höher als 1266Mhz takten.
=> Kommt später eine stärkere RX485 mit Polaris-10?
--- Update ---
Ergänzung:
Wenn die neuen Polaris mindestens 2,5-mal so effizient wie die Vorgänger sein sollen, dann dürfte Polaris für die Leistung einer 390X (TDP=275W) kaum über 100 Watt verbrauchen. Vergleiche ich aber mit einer Fury-X, die ebenfalls nur TDP=275Watt hat, dann müsste Polaris-10 bei TDP=150Watt eine Fury-X in der Leistung übertreffen..., ganz zu schweigen, wenn man mit einer Nano vergleicht...
Polaris-10 sollte weit mehr als 6TFlops schaffen...
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Ich jedenfalls hoffe immer noch auf eine RX490 mit 40+ CUs ~1500 MHz und GDDR5X, deutlich mehr Leistung als Hawaii, und von mir aus auch über 200 Watt TDP. Ich glaube nicht, dass Vega vorgezogen wurde, noch dass Vega zur RX490 werden soll - wenn überhaupt wird Vega wieder etwas wie Fury. Oder Vega 10 und 11 (oder wie auch immer) werden Mitte nächsten Jahres zu RX 580 und RX 590 - sonst hätten die ja nichts außer Rebrands nächstes Jahr.
Wenn die neuen Polaris mindestens 2,5-mal so effizient wie die Vorgänger sein sollen, dann dürfte Polaris für die Leistung einer 390X (TDP=275W) kaum über 100 Watt verbrauchen. Vergleiche ich aber mit einer Fury-X, die ebenfalls nur TDP=275Watt hat, dann müsste Polaris-10 bei TDP=150Watt eine Fury-X in der Leistung übertreffen..., ganz zu schweigen, wenn man mit einer Nano vergleicht...
Ich kam auf ähnliche Werte 90-100W bei ~390(X) Leistung. Damit stimmt die angegebene "up to 2,8x P/W" und auch die bessere Effizienz als 1080.
Da die 2.8x eine "up to" Angabe ist, wird sicher nicht die Nano gemeint sein und Hawaii sollte als Referenz passen.
Hawaii Leistung ist auch mindestens zu erwarten, wenn man Shader und Takt vergleicht.
Ist zwar eine Milchmädchenrechnung, aber:
2304 Shader @ 1266MHz = 2777 Shader @ 1050MHz --> zwischen 390 und 390X
Die Frage ist, was die Änderungen an der Architektur noch bringen. Hier weiß man ja so gut wie gar nichts, außer dass alles neu ist.
Eine Interessante Theorie aus dem 3D-Center:
AMD baut eine Stromsparende Ref. Karte und die Partner dürfen Max. OC Modelle bringen. Würde sich mit den angekündigten Devil Karten inkl. Wakü von Powercolor decken, die ja eigentlich immer nur die OC Karten waren.
Spinnerei: Vielleicht gibt es mit 150W ja eine Dual Karte, die da gegen die 1080 angetreten ist.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
Schau dir nochmal das Architekturschema an:Irgendwie passen die bisher bekannten Performance-Daten von Polaris nicht zu den angeblichen technischen Daten:
@Anzahl CUs:
Wenn die GPU >230mm² ist, müsste sie dann nicht weit mehr als 40CU haben? Im 14nm-Prozess sollten die Shader kaum mehr als 50% der Fläche der 28nm-Shader verbrauchen. Weil aber die sonstigen Strukturen (Busse etc.) nicht wirklich mehr werden, müsste für die Shader zusätzliche Fläche frei werden... => könnte es sein, dass Polaris weit mehr als 36 Cluster, also womöglich 44 oder 48 CU besitzt?
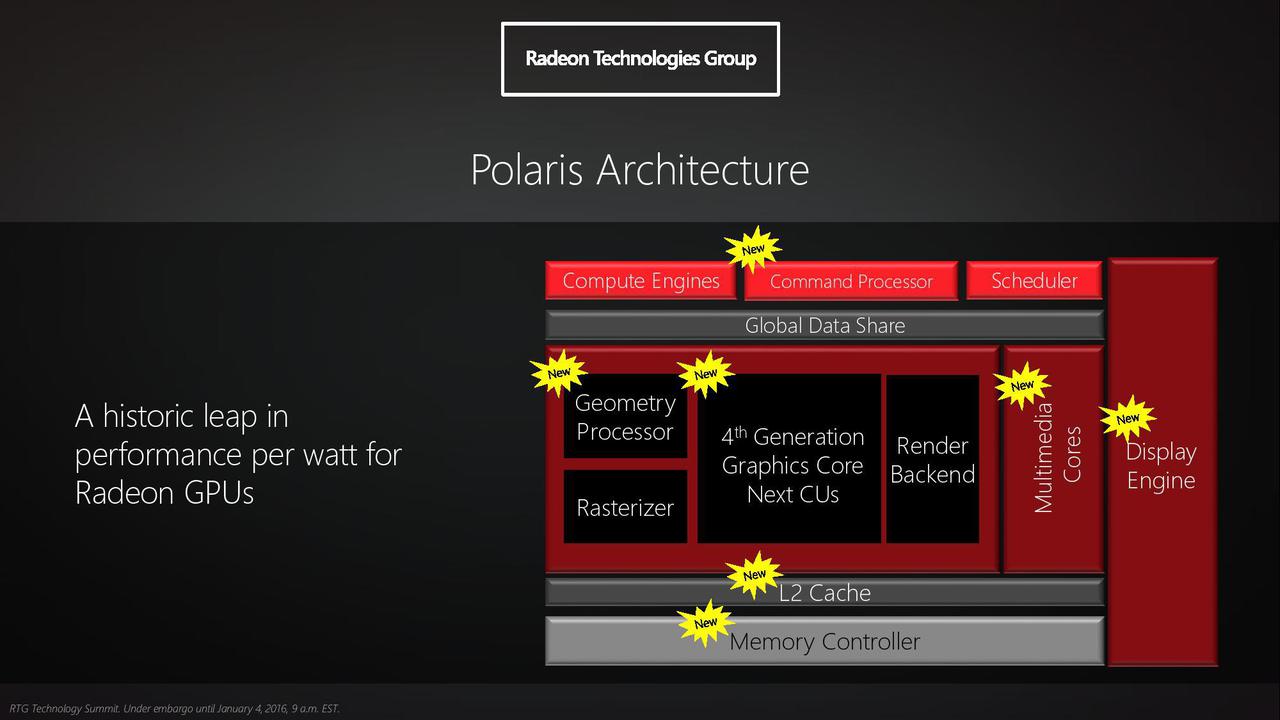
7 Elemente einschließlich L2 Cache haben eine Architekturveränderung erfahren, wobei in den meisten Fällen davon auszugehen ist, dass es mehr Transistoren werden, statt weniger.
Flächendichte ist auch so eine Sache: in diesem Frühstadium des neuen 14nm Prozesses kann es sein dass die Transistoren pro mm² nicht im gleichen Verhältnis gegenüber den letzten Designs auf dem 28nm Prozess skalieren wie die SRAM-Chips, die von den Marketingabteilungen der Foundries üblicherweise für den Vergleich herangezogen werden.
Da GCN 1.4 auf Effizienz getrimmt sein soll, kann es auch gut sein, dass die neuen CUs sogar je signifikant mehr Transistoren belegen als eine CU der alten Generationen. "Effizienz" mit Priorität Energieeffizienz vorrangig vor Flächeneffizienz. Je feinkörniger man einzelne Einheiten abschalten können möchte, z.B. eine einzelne CU durch Power-Gating, desto höher der Transistoraufwand.
Der Vergleich mit Bristol Ridge hinkt, da GCN 1.4 vs GCN 1.3, anderer Prozess, anderer Sweetspot (Knie in der Effizienzkurve), bzw. überhaupt Betonung auf diesen Sweetspot (Mobilgeräte).
Letzter Punkt: Ich kann mir auch gut vorstellen, dass selbst die Relation Grafikleistung vs Rohleistung (TFlops) signifikant verschoben wird in Richtung mehr Grafikleistung in der Praxis bei bestehender Rohleistung auf dem Papier.
Zuletzt bearbeitet:
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Die sonstigen Structuren lassen sich nicht unbeding shrinken. Die Pads und Leistungstransitoren für I/O werden den gleichen Platzbedarf haben wie in 28nm. Zudem werden eventuell noch neue Einheiten und andere architektonische Maßnahmen weitere Transistoren brauchen.@Anzahl CUs:
Weil aber die sonstigen Strukturen (Busse etc.) nicht wirklich mehr werden, müsste für die Shader zusätzliche Fläche frei werden... => könnte es sein, dass Polaris weit mehr als 36 Cluster, also womöglich 44 oder 48 CU besitzt?
Selbst ein reiner Hawai (438 mm²) shrink würde schon größer als 219mm² werden bei 1:2.
Ich rechne mit max 40 Cluster.
Vielleicht sehen wir die ja bei Apple, wie es bei Tonga auch der Fall war.
Zudem kann AMD die kleinere Variante besser Liefern und für später schon mal die guten Sammeln.
NOFX
Grand Admiral Special
- Mitglied seit
- 02.09.2002
- Beiträge
- 4.532
- Renomée
- 287
- Standort
- Brühl
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600 @Stock
- Mainboard
- ASUS B350M-A
- Kühlung
- Boxed-Kühler
- Speicher
- 2x 8 G.Skill RipJaws 4 rot DDR4-2800 DIMM
- Grafikprozessor
- PowerColor Radeon RX 480 Red Dragon 8GB
- Display
- LG 34UM-68 (FreeSync)
- SSD
- PowerColor Radeon RX 480 Red Dragon 8GB
- HDD
- 1x 1,5TB Seagate S-ATA
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- onBoard
- Gehäuse
- Thermaltake Versa H15
- Netzteil
- Cougar SX 460
- Betriebssystem
- Windows 10 Pro x64
- Webbrowser
- Google Chrome
Theoretisch sollte bei 14 nm nur noch 25 % der Fläche verbraucht werden.
Von daher sind bei >200 mm² in 14 nm vs. >400 mm² eigentlich deutlich mehr Transistoren zu erwarten (bis zu 2x - wie gesagt theoretisch).
Von daher sind bei >200 mm² in 14 nm vs. >400 mm² eigentlich deutlich mehr Transistoren zu erwarten (bis zu 2x - wie gesagt theoretisch).
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.336
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Da der Prozess noch am Anfang ist würde ich das auch nicht überbewerten, siehe Tahiti vs. Tonga.
Der Tahiti hat lt. Wikipedia eine Fläche von 365 mm² bei 4,31 Mrd Transistoren.
Der Tonga hat lt. Wikipedia eine Fläche von 359 mm² bei 5 Mrd Transistoren.
Man könnte also sagen das die Packungsdichte im laufe der Zeit deutlich zugenommen hatte.
Der Tahiti hat lt. Wikipedia eine Fläche von 365 mm² bei 4,31 Mrd Transistoren.
Der Tonga hat lt. Wikipedia eine Fläche von 359 mm² bei 5 Mrd Transistoren.
Man könnte also sagen das die Packungsdichte im laufe der Zeit deutlich zugenommen hatte.
Ich jedenfalls hoffe immer noch auf eine RX490 mit 40+ CUs ~1500 MHz und GDDR5X, deutlich mehr Leistung als Hawaii, und von mir aus auch über 200 Watt TDP. Ich glaube nicht, dass Vega vorgezogen wurde, noch dass Vega zur RX490 werden soll - wenn überhaupt wird Vega wieder etwas wie Fury. Oder Vega 10 und 11 (oder wie auch immer) werden Mitte nächsten Jahres zu RX 580 und RX 590 - sonst hätten die ja nichts außer Rebrands nächstes Jahr.
40+ niemals, 40 vielleicht.
1500 mhz niemals, etvl als luftgekühlte oc-rekorde
gddr5x niemals, amd setzt auf gddr5 und hbm2. 3 optionen kosten zu viel
vega wird bestimmt rx5 + fury 2, die 40 cu p10 wird dann rx 580.
Theoretisch sollte bei 14 nm nur noch 25 % der Fläche verbraucht werden.
Von daher sind bei >200 mm² in 14 nm vs. >400 mm² eigentlich deutlich mehr Transistoren zu erwarten (bis zu 2x - wie gesagt theoretisch).
Werden die nm nicht nur in eine Dimension (Gatelänge) angegeben, wodurch es 50% bzw. die gleiche Transistoranzahl auf der halben Fläche ergibt.
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.336
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Damit wird lediglich eine bestimmte Strukturgröße angegeben.
Wie dicht die Transistoren dabei zusammen hocken ist dafür irrelevant, daher auch die zum Teil sehr unterschiedlichen Packungsdichten.
Wie dicht die Transistoren dabei zusammen hocken ist dafür irrelevant, daher auch die zum Teil sehr unterschiedlichen Packungsdichten.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
40+ niemals, 40 vielleicht.
1500 mhz niemals, etvl als luftgekühlte oc-rekorde
gddr5x niemals, amd setzt auf gddr5 und hbm2. 3 optionen kosten zu viel
1. GDDR5X ist nur ein minimales Upgrade für den MC, und es ist abwärtskompatibel zu GDDR5.
2. Welche Frequenzen mit dem 14nm FinFET von GloFo bei GCN erreichbar sind ist pure Spekulation. Der Energieverbrauch steigt natürlich exponentiell mit der Frequenz.
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.982
- Renomée
- 232
Der Energieverbrauch steigt natürlich exponentiell mit der Frequenz.
Ich will hier jetzt nicht die immer wieder beliebte Diskussion über die Leistungsaufnahme in Abhängigkeit der für ohmsche Widerstände, Spulen und Kondensatoren gültige Formelsammlung aus der Oberstufe wiederbeleben, aber...
Bist Du Dir da sicher?
MfG
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Ich will hier jetzt nicht die immer wieder beliebte Diskussion über die Leistungsaufnahme in Abhängigkeit der für ohmsche Widerstände, Spulen und Kondensatoren gültige Formelsammlung aus der Oberstufe wiederbeleben, aber...
Bist Du Dir da sicher?
MfG
Naja, alle Kurven die ich bisher gesehen habe sehen praktisch so aus - natürlich spielt auch der höhere Spannung und die Temperatur eine Rolle. Jedenfalls wollte ich nur damit ausdrücken, dass auch das Power Target bei AMD der Grund für die derzeit bekannten Frequenzen sein kann, und es ist ziemlich sicher, dass mehr Output auch mehr Input braucht. Abgesehen davon dürfte bei Polaris durch "per CU Powergating" wenigstens bei deaktivierten CUs auch kein/kaum Strom mehr benötigt werden.
Zuletzt bearbeitet:
sompe
Grand Admiral Special
- Mitglied seit
- 09.02.2009
- Beiträge
- 14.336
- Renomée
- 1.973
- Mein Laptop
- Dell G5 15 SE 5505 Eclipse Black
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 3950X
- Mainboard
- MSI MPG X570 GAMING PRO CARBON WIFI
- Kühlung
- Wasserkühlung
- Speicher
- 4x 16 GB G.Skill Trident Z RGB, DDR4-3200, CL14
- Grafikprozessor
- AMD Radeon RX 6900 XT
- Display
- 1x 32" LG 32UD89-W + 1x 24" Dell Ultrasharp 2405FPW
- SSD
- Samsung SSD 980 PRO 1TB, Crucial MX500 500GB, Intel 600p 512GB, Intel 600p 1TB
- HDD
- Western Digital WD Red 2 & 3TB
- Optisches Laufwerk
- LG GGC-H20L
- Soundkarte
- onboard
- Gehäuse
- Thermaltake Armor
- Netzteil
- be quiet! Dark Power Pro 11 1000W
- Betriebssystem
- Windows 10 Professional, Windows 7 Professional 64 Bit, Ubuntu 20.04 LTS
- Webbrowser
- Firefox
Sicher das dabei nicht ander Spannung geschraubt wurde und diese Spannungserhöhung dafür verantwortlich bzw. die Temperatur dabei mit gestiegen war?
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.249
- Renomée
- 228
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Ich will hier jetzt nicht die immer wieder beliebte Diskussion über die Leistungsaufnahme in Abhängigkeit der für ohmsche Widerstände, Spulen und Kondensatoren gültige Formelsammlung aus der Oberstufe wiederbeleben, aber...
Bist Du Dir da sicher?
MfG
Ich denke, wichtiger Nebenfaktor ist, dass mit der Frequenz auch höhere Spannung gebraucht wird. Und höhere Spannung sorgt eher dafür, dass die Verlustleistung exponentiell steigt.
hoschi_tux
Grand Admiral Special
- Mitglied seit
- 08.03.2007
- Beiträge
- 4.760
- Renomée
- 286
- Standort
- Ilmenau
- Aktuelle Projekte
- Einstein@Home, Predictor@Home, QMC@Home, Rectilinear Crossing No., Seti@Home, Simap, Spinhenge, POEM
- Lieblingsprojekt
- Seti/Spinhenge
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen R9 5900X
- Mainboard
- ASUS TUF B450m Pro-Gaming
- Kühlung
- Noctua NH-U12P
- Speicher
- 2x 16GB Crucial Ballistix Sport LT DDR4-3200, CL16-18-18
- Grafikprozessor
- AMD Radeon RX 6900XT (Ref)
- Display
- LG W2600HP, 26", 1920x1200
- HDD
- Crucial M550 128GB, Crucial M550 512GB, Crucial MX500 2TB, WD7500BPKT
- Soundkarte
- onboard
- Gehäuse
- Cooler Master Silencio 352M
- Netzteil
- Antec TruePower Classic 550W
- Betriebssystem
- Gentoo 64Bit, Win 7 64Bit
- Webbrowser
- Firefox
Die Verlustleistung steigt linear mit der Frequenz und quadratisch mit der Spannung.
Leckströme sind eher Kandidaten für exponentiellen Anstieg.
Leckströme sind eher Kandidaten für exponentiellen Anstieg.
Woerns
Grand Admiral Special
- Mitglied seit
- 05.02.2003
- Beiträge
- 2.982
- Renomée
- 232
Exponentiell ist leider ein konkreter mathematischer Begriff, und der trifft hier leider nicht zu. Bei festgehaltener Spannung geht die Verlustleistung nämlich linear mit dem Takt. Darüber hinaus kann man physikalische Gesetzmäßigkeiten nur in sehr engen Grenzen anwenden, weil das Wesen einer zeitgemäßen Architektur darin besteht, dass in recht kurzen Zeiträumen Spannungen rauf- und runtergeschaltet oder ganze Bereiche aktiviert und deaktiviert werden. Aber lassen wir das.
MfG
MfG
NOFX
Grand Admiral Special
- Mitglied seit
- 02.09.2002
- Beiträge
- 4.532
- Renomée
- 287
- Standort
- Brühl
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- Spinhenge
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600 @Stock
- Mainboard
- ASUS B350M-A
- Kühlung
- Boxed-Kühler
- Speicher
- 2x 8 G.Skill RipJaws 4 rot DDR4-2800 DIMM
- Grafikprozessor
- PowerColor Radeon RX 480 Red Dragon 8GB
- Display
- LG 34UM-68 (FreeSync)
- SSD
- PowerColor Radeon RX 480 Red Dragon 8GB
- HDD
- 1x 1,5TB Seagate S-ATA
- Optisches Laufwerk
- DVD-Brenner
- Soundkarte
- onBoard
- Gehäuse
- Thermaltake Versa H15
- Netzteil
- Cougar SX 460
- Betriebssystem
- Windows 10 Pro x64
- Webbrowser
- Google Chrome
Es wird nur die eine Dimension angegeben, auf die Fläche gerechnet ist es dann aber - annähernd - quadratisch.Werden die nm nicht nur in eine Dimension (Gatelänge) angegeben, wodurch es 50% bzw. die gleiche Transistoranzahl auf der halben Fläche ergibt.
Das die 14 nm nicht wirklich 14 nm entsprechen ist klar, aber mehr als eine Verdopplung der Transistorenzahl sollte auch jetzt schon drin sein.
Ich verweise mal auf diesen beiden Artikel:
- Platzbedarf
- Ein wenig Wissen über FETs
Generell gilt das bei höheren Frequenzen die Spannungen am Gate höher sein müssen damit ein FET schneller schalten kann.
- Platzbedarf
- Ein wenig Wissen über FETs
Generell gilt das bei höheren Frequenzen die Spannungen am Gate höher sein müssen damit ein FET schneller schalten kann.
IT-Extremist
Gesperrt
- Mitglied seit
- 09.12.2015
- Beiträge
- 225
- Renomée
- 1
Begründung?40+ niemals
Begründung?1500 mhz niemals
GDDR5X ist nicht so aufwändig, da könnte schon noch etwas kommen.gddr5x niemals, amd setzt auf gddr5 und hbm2. 3 optionen kosten zu viel
Ähnliche Themen
- Antworten
- 1
- Aufrufe
- 290
- Antworten
- 1
- Aufrufe
- 645
- Antworten
- 0
- Aufrufe
- 559
- Antworten
- 0
- Aufrufe
- 557
- Antworten
- 0
- Aufrufe
- 540