App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Ryzen hat keine 16MB L3-Cache ;-)
- Ersteller Flodul
- Erstellt am
So sieht das aus:
Wieso sollte ich das? Die Threads würden jeweils ihr eigenes Working-Set beanspruchen wenn ich den Test mehrfach parallel laufen ließe und es würde Cache-Thrashing stattfinden, d.h. die Threads würden sich ihre Inhalte gegenseitig aus dem Cache werfen.
Und wenn ich jeweils nur eine Instanz auf jeweils unterschiedlichen Kernen laufen ließe, dann wär das Ergebnis das selbe.
Dreh und wende es wie Du willst; die IF ist einfach Käse.
Code:
Logical Processor to Cache Map:
**-------------- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**-------------- Instruction Cache 0, Level 1, 64 KB, Assoc 4, LineSize 64
**-------------- Unified Cache 0, Level 2, 512 KB, Assoc 8, LineSize 64
********-------- Unified Cache 1, Level 3, 8 MB, Assoc 16, LineSize 64
--**------------ Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**------------ Instruction Cache 1, Level 1, 64 KB, Assoc 4, LineSize 64
--**------------ Unified Cache 2, Level 2, 512 KB, Assoc 8, LineSize 64
----**---------- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**---------- Instruction Cache 2, Level 1, 64 KB, Assoc 4, LineSize 64
----**---------- Unified Cache 3, Level 2, 512 KB, Assoc 8, LineSize 64
------**-------- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**-------- Instruction Cache 3, Level 1, 64 KB, Assoc 4, LineSize 64
------**-------- Unified Cache 4, Level 2, 512 KB, Assoc 8, LineSize 64
--------**------ Data Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**------ Instruction Cache 4, Level 1, 64 KB, Assoc 4, LineSize 64
--------**------ Unified Cache 5, Level 2, 512 KB, Assoc 8, LineSize 64
--------******** Unified Cache 6, Level 3, 8 MB, Assoc 16, LineSize 64
----------**---- Data Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------**---- Instruction Cache 5, Level 1, 64 KB, Assoc 4, LineSize 64
----------**---- Unified Cache 7, Level 2, 512 KB, Assoc 8, LineSize 64
------------**-- Data Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
------------**-- Instruction Cache 6, Level 1, 64 KB, Assoc 4, LineSize 64
------------**-- Unified Cache 8, Level 2, 512 KB, Assoc 8, LineSize 64
--------------** Data Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
--------------** Instruction Cache 7, Level 1, 64 KB, Assoc 4, LineSize 64
--------------** Unified Cache 9, Level 2, 512 KB, Assoc 8, LineSize 64Nichts desto trotz ist der L3 eines CCX in zwei "slice a 4MB" aufgeteilt.
Was passiert wenn du mehrere Instansen laufen lässt z.B. auf Core 0,2,4,6,8 ?
Wieso sollte ich das? Die Threads würden jeweils ihr eigenes Working-Set beanspruchen wenn ich den Test mehrfach parallel laufen ließe und es würde Cache-Thrashing stattfinden, d.h. die Threads würden sich ihre Inhalte gegenseitig aus dem Cache werfen.
Und wenn ich jeweils nur eine Instanz auf jeweils unterschiedlichen Kernen laufen ließe, dann wär das Ergebnis das selbe.
Dreh und wende es wie Du willst; die IF ist einfach Käse.
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@Flodul
Oge, ich ging von einem pointer aus, was du auch schon geschrieben hast.
Es werden praktisch keine Daten mehr kopiert sondern der "Zeiger" verlinkt in den entsprechenden Adressbereich.
Hier gibt es weitere Infos vom IF: https://www.hardwareluxx.de/index.p...ric-anbindung-der-epyc-serverprozessoren.html
Aber das sind mir schon bekannte Infos, oder siehst du dort noch was neues?
MfG
Oge, ich ging von einem pointer aus, was du auch schon geschrieben hast.
Es werden praktisch keine Daten mehr kopiert sondern der "Zeiger" verlinkt in den entsprechenden Adressbereich.
Hier gibt es weitere Infos vom IF: https://www.hardwareluxx.de/index.p...ric-anbindung-der-epyc-serverprozessoren.html
Aber das sind mir schon bekannte Infos, oder siehst du dort noch was neues?
MfG
Hier gibt es weitere Infos vom IF: https://www.hardwareluxx.de/index.p...ric-anbindung-der-epyc-serverprozessoren.html
Aber das sind mir schon bekannte Infos, oder siehst du dort noch was neues?
MfG
Ach, die Architektur ist mir egal. Mich interessieren Messwerte.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
lol, sind die wenigstens aktuell kalibriert, deine Messmittel?Ach, die Architektur ist mir egal. Mich interessieren Messwerte.
Das kann ich aber durchaus nachvollziehen!
")
Wie wäre es mit zwei Instanzen? (0-4 & 5-7)
P.S. Der L3 SnoopFilter (Bereich im L3 Cache) verhindert Cache-Thrashing: http://www.realworldtech.com/bulldozer/3/
lol, sind die wenigstens aktuell kalibriert, deine Messmittel?
Der Mess-Thread läuft mit ziemlich hoher Priorität. Da dürften nur noch Interrupts und DPCs dazwischenfunken. Deren Effekt ist vernachlässigbar.
Wie wäre es mit zwei Instanzen? (0-4 & 5-7)
Sehe ich keinen Sinn drin.
P.S. Der L3 SnoopFilter (Bereich im L3 Cache) verhindert Cache-Thrashing: http://www.realworldtech.com/bulldozer/3/
Ein Snoop-Filter hat mit Cache-Thrashing genau garnichts zu tun. Er limitiert nur den Scope eines Snoops.
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Ok, dann darfst du dich weiterhin über deine schlechte Ergebnisse aufregen...Der Mess-Thread läuft mit ziemlich hoher Priorität. Da dürften nur noch Interrupts und DPCs dazwischenfunken. Deren Effekt ist vernachlässigbar.
Sehe ich keinen Sinn drin.
Ein Snoop-Filter hat mit Cache-Thrashing genau garnichts zu tun. Er limitiert nur den Scope eines Snoops.

Geht es dir nur um die Single Thread Latenz?
Geht es dir nur um die Single Thread Latenz?
Latenz ist immer single-threaded weil es um die Zeit geht bis die Daten im Kern verwertbar sind.
Alle Benchmarks wie z.B. die in Sandra messen single-threaded.
Man könnte multi-threaded nur zwei Dinge beobachten: das Pipelining der Caches, d.h. wenn N Workingsets kleiner als die Größe einer geteilten Cache-Ebene sind, dass man dann nicht die N-fache Latenz hat, sondern eine zwischen der N-fachen und der einfachen. Und, dass beim Überschreiten der Größe dieser N Working-Sets die Threads sich gegenseitig thrashen und die Peformance unter Umständen auf das Niveau des RAMs einbricht. Aber beide Dinge wären ein anderes Thema.
Ich hab übrigens noch einen Benchmark geschrieben der misst wie lange es dauert, damit eine Cachezeile vom L1-Cache eines Kernes in einen anderen kommt, was relevant ist wenn Threads Daten austauschen. In einem CCX geht das so mit ca 150 Takten. Zwischen den CCXen liegt die Performance bei ca. 550 Takten; das zeigt mal wieder, dass die IF Murks ist. Das zeigt sich z.B. in dem Benchmark der weiter oben angeführten französischen Seite, wo eine 4+0-Konfiguration in Battlefield 1 25% schneller ist als eine 2+2-Konfiguration.
Der Ryzen ist sicher keine schlechte CPU, aber hat eine Schwäche im Cache-Design.
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Tu dich mal mit helle53 zusammen, der hat auch schon Cache Hirarchien untersucht... http://abload.de/img/corepairingatlohn_idluturo.jpgLatenz ist immer single-threaded weil es um die Zeit geht bis die Daten im Kern verwertbar sind.
Alle Benchmarks wie z.B. die in Sandra messen single-threaded.
Man könnte multi-threaded nur zwei Dinge beobachten: das Pipelining der Caches, d.h. wenn N Workingsets kleiner als die Größe einer geteilten Cache-Ebene sind, dass man dann nicht die N-fache Latenz hat, sondern eine zwischen der N-fachen und der einfachen. Und, dass beim Überschreiten der Größe dieser N Working-Sets die Threads sich gegenseitig thrashen und die Peformance unter Umständen auf das Niveau des RAMs einbricht. Aber beide Dinge wären ein anderes Thema.
Ich hab übrigens noch einen Benchmark geschrieben der misst wie lange es dauert, damit eine Cachezeile vom L1-Cache eines Kernes in einen anderen kommt, was relevant ist wenn Threads Daten austauschen. In einem CCX geht das so mit ca 150 Takten. Zwischen den CCXen liegt die Performance bei ca. 550 Takten; das zeigt mal wieder, dass die IF Murks ist.
Das Programm ist von ihm.
Nutzt du eigentlich die UEFI Energieoptionen sowie die vom OS?
Oder alle Energieoptionen disabled?
Nutzt du eigentlich die UEFI Energieoptionen sowie die vom OS?
Oder alle Energieoptionen disbaled?
Nix disabled, aber die Latenz von vier Takten beim L1-Cache zeigt mir, dass der Kern schon bei der kleinsten Blockgröße am Anfang des Tests auf Maximal-Takt hochgedreht hat.
Ich kann dir schon architekturbedingt nicht weiter helfen, da kein AMD64 vorhanden. Als Freund des experimentellen Nachweises halte ich eine solche Messung trotzdem für interessant. Man kann ja nicht einfach hergehen und eine Messgröße im groben Raster (1,2,4,8,16,32) abtasten, und steif und fest behaupten, dass es sich bei 5 MB so verhalten muss, wie bei den gemessenen 8 MB. Wir haben die Dinger nicht mitentwickelt und wissen, wie es drinnen funktioniert, sondern versuchen durch solche nützlichen Tests wie dem von dir zu verstehen, was man bei der Programmierung beachten muss.Das wäre größtenteils unsinnig bei Set-assoziativen Caches mit einer Set Größe die eine Zweierpotenz ist.Zitat von miriquidi
Ich fände es aber auch gut, nicht nur 1,2,4,8 MByte zu nutzen, sondern auch Zwischenwerte.
Lediglich der Zwischenschritt von 8,5MB wäre interessant.
Beim alten Sockel F Opteron ergänzten sich die Caches übrigens auch nicht. Wenn aber zwei Kerne auf unterschiedlichen Knoten schreibend auf den gleichen Speicherbereich (bzw. eng benachbart) zugreifen, kann es schon sein, dass jeder Kern vor jeder Schreibaktion erst einmal beim andern NUMA-Knoten fragen muss, ob der bei Ihm vorliegende Cache-Zustand noch der aktuelle ist, oder ob dort üben was geändert worden ist. Da kann man die lustigsten Sachen erleben (bzw. unlustig).
Beim Übergang vom K10 X4 zum K10 X6 kamen dann die Snoop-Filter, die zwar Single-Threaded etwas Geschwindigkeit gekostet haben (weil weniger L3 Cache), Multithreaded im Quadsockel-System aber manchmal echt viel gebracht haben.
Ich kann dir schon architekturbedingt nicht weiter helfen, da kein AMD64 vorhanden. Als Freund des experimentellen Nachweises halte ich eine solche Messung trotzdem für interessant. Man kann ja nicht einfach hergehen und eine Messgröße im groben Raster (1,2,4,8,16,32) abtasten, und steif und fest behaupten, dass es sich bei 5 MB so verhalten muss, wie bei den gemessenen 8 MB. ...
Tut's auch nicht, aber die Grenzen auf denen ich getestet habe liegen auf den Grenzen in denen Caches partitioniert sind. Cache-Sets sind nun mal immer eine Zweier-Potenz groß um performant zu sein.
Beim alten Sockel F Opteron ergänzten sich die Caches übrigens auch nicht. Wenn aber zwei Kerne auf unterschiedlichen Knoten schreibend auf den gleichen Speicherbereich (bzw. eng benachbart) zugreifen, kann es schon sein, dass jeder Kern vor jeder Schreibaktion erst einmal beim andern NUMA-Knoten fragen muss, ob der bei Ihm vorliegende Cache-Zustand noch der aktuelle ist, oder ob dort üben was geändert worden ist. ...
Erstens ist das eine völlig andere Thematik.
Und zweitens fragt ein Cache nicht einen anderen ob etwas geändert wurde. Wenn etwas geändert wurde, dann hat die Cachezeile an dem Kern wo das geändert wurde in den Zustand modified gewechselt und der Cache ist der einzige der dieses Datenwort enthält. Also wird in deinem Szenario von einer CPU gefragt welche CPU denn eine aktuellere Kopie des Speicherblocks hat als er im RAM steht.
Hmmm...also erstmal vorab. Ich bin kein Programmierer und kein Hardwarearchitekt. Das folgende ist also ggf. Laienhafte Spekulation - falls ich daneben liege kein Problem. Aber nur mal meine Gedanken als Denkanstoß:
Betrachten wir erstmal diese Liste:
So wie es hier ausgegeben wird würde ich die Cachesituation so interpretieren als das 4-Kerne jeweils ein 8MB-Segment zusammen haben.
Also Core0-4 L3-1 mit 8MB ("lokalisiert" an Kern1). Die anderen Kerne aus Block 0-4 greifen dann wohl über Core1 auf den Cache zu ?
Der Ryzen besteht aus 2x4 Kernen vom Layout her. Ergo würde das Sinn ergeben dass jeder 4-Kern block 8MB L3 cache hat. Dieser Block wird irgendwie mit "shared Access" arbeiten wobei ggf. die "Steuerung" des ganzen der Kern1 macht ?
=> Es sind eigentlich 2x8 MB-Blöcke und der Interconnect des ganzen läuft über die IF.
Erwarten würde ich daher dass er bei >8MB dramatisch langsamer wird...
1. Aus der obigen Liste würde ich daher erwarten dass bei >32kb was passiert weil der Instruction cache zu ist.
Als nächstes würde ich erwarten dass der L2 cache bis 512kB arbeitet..:
Der nächste schritt wäre wenn nun der L3 dran ist, welche ja 8MB pro CCX ist...
Die Sonderbarkeit könnte aber das "Interleaving" innerhalb eines CCX sein ? Evtl. sind das nochmal 2x4MB Blöcke ? die zwischen jeweils 2 Kernen sitzen?
Kern1 --- Cache Block1----Kern2
|**********************|
Kern3----Cache Block2----Kern4
(Die *zeichen sind Abstandshalter zur Darstellung und haben KEINE sonstige Bedeutung)
Die -Zeichen und |Zeichen sind die Verbindungen die Daten-Transportieren.
Evtl gibt es auch noch eine "Brücke direkt zwischen den Caches, würde aber vielleicht erklären warum es genau doppelt so lange dauert um 4MB zu addressieren...mit 1 Fetch kann nur aus 1 Block parallel gelesen werden...um in den zweiten Block zu kommen brauchts 1 extra Runde ?
Weiter ist ja dann der 2.8MB L3 cache auf dem anderen CCX zu finden...das würde ich so verstehen dass man da dann über die IF zugreift und diese läuft mit dem RAM-Takt.
Mal sehen wie ihr experten das seht.
Betrachten wir erstmal diese Liste:
****Rest gekürzt - der rest ist identisch mit Core5-7.Logical Processor to Cache Map:
**-------------- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**-------------- Instruction Cache 0, Level 1, 64 KB, Assoc 4, LineSize 64
**-------------- Unified Cache 0, Level 2, 512 KB, Assoc 8, LineSize 64
********-------- Unified Cache 1, Level 3, 8 MB, Assoc 16, LineSize 64
--**------------ Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**------------ Instruction Cache 1, Level 1, 64 KB, Assoc 4, LineSize 64
--**------------ Unified Cache 2, Level 2, 512 KB, Assoc 8, LineSize 64
----**---------- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**---------- Instruction Cache 2, Level 1, 64 KB, Assoc 4, LineSize 64
----**---------- Unified Cache 3, Level 2, 512 KB, Assoc 8, LineSize 64
------**-------- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**-------- Instruction Cache 3, Level 1, 64 KB, Assoc 4, LineSize 64
------**-------- Unified Cache 4, Level 2, 512 KB, Assoc 8, LineSize 64
--------**------ Data Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**------ Instruction Cache 4, Level 1, 64 KB, Assoc 4, LineSize 64
So wie es hier ausgegeben wird würde ich die Cachesituation so interpretieren als das 4-Kerne jeweils ein 8MB-Segment zusammen haben.
Also Core0-4 L3-1 mit 8MB ("lokalisiert" an Kern1). Die anderen Kerne aus Block 0-4 greifen dann wohl über Core1 auf den Cache zu ?
Der Ryzen besteht aus 2x4 Kernen vom Layout her. Ergo würde das Sinn ergeben dass jeder 4-Kern block 8MB L3 cache hat. Dieser Block wird irgendwie mit "shared Access" arbeiten wobei ggf. die "Steuerung" des ganzen der Kern1 macht ?
=> Es sind eigentlich 2x8 MB-Blöcke und der Interconnect des ganzen läuft über die IF.
Erwarten würde ich daher dass er bei >8MB dramatisch langsamer wird...
1. Aus der obigen Liste würde ich daher erwarten dass bei >32kb was passiert weil der Instruction cache zu ist.
--------------- Check alle <32KB sind gleich schnell (L1 Cache)4kB 3.9375
8kB 3.9375
16kB 3.79688
32kB 3.86719
Als nächstes würde ich erwarten dass der L2 cache bis 512kB arbeitet..:
---------------- Check...Latenz =4x L1 ?64kB 16.5586
128kB 16.5586
256kB 15.0205
512kB 15.6401
Der nächste schritt wäre wenn nun der L3 dran ist, welche ja 8MB pro CCX ist...
--------------Check...50% langsamer als der L21MB 24.8687
2MB 24.8027
4MB 24.7785
8MB 49.2426 (hier die erste Sonderbarkeit, ansich sollte die Latenz im selben CCX konstant bleiben)
Die Sonderbarkeit könnte aber das "Interleaving" innerhalb eines CCX sein ? Evtl. sind das nochmal 2x4MB Blöcke ? die zwischen jeweils 2 Kernen sitzen?
Kern1 --- Cache Block1----Kern2
|**********************|
Kern3----Cache Block2----Kern4
(Die *zeichen sind Abstandshalter zur Darstellung und haben KEINE sonstige Bedeutung)
Die -Zeichen und |Zeichen sind die Verbindungen die Daten-Transportieren.
Evtl gibt es auch noch eine "Brücke direkt zwischen den Caches, würde aber vielleicht erklären warum es genau doppelt so lange dauert um 4MB zu addressieren...mit 1 Fetch kann nur aus 1 Block parallel gelesen werden...um in den zweiten Block zu kommen brauchts 1 extra Runde ?
Weiter ist ja dann der 2.8MB L3 cache auf dem anderen CCX zu finden...das würde ich so verstehen dass man da dann über die IF zugreift und diese läuft mit dem RAM-Takt.
-----Check...cross-CCX-Latenz = RAM-Latenz16MB 166.989 (hier die zweite, die Latenz geht hoch auf das Niveau des RAMs)
32MB 166.498
Mal sehen wie ihr experten das seht.
Zuletzt bearbeitet:
bschicht86
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 14.12.2006
- Beiträge
- 4.249
- Renomée
- 228
- BOINC-Statistiken

- Details zu meinem Desktop
- Prozessor
- 2950X
- Mainboard
- X399 Taichi
- Kühlung
- Heatkiller IV Pure Chopper
- Speicher
- 64GB 3466 CL16
- Grafikprozessor
- 2x Vega 64 @Heatkiller
- Display
- Asus VG248QE
- SSD
- PM981, SM951, ein paar MX500 (~5,3TB)
- HDD
- -
- Optisches Laufwerk
- 1x BH16NS55 mit UHD-BD-Mod
- Soundkarte
- Audigy X-Fi Titanium Fatal1ty Pro
- Gehäuse
- Chieftec
- Netzteil
- Antec HCP-850 Platinum
- Betriebssystem
- Win7 x64, Win10 x64
- Webbrowser
- Firefox
- Verschiedenes
- LS120 mit umgebastelten USB -> IDE (Format wie die gängigen SATA -> IDE)
Ich bin zwar kein Experte, aber ich würd wohl auch wie andere gern den Bereich zwischen 4 und 8 MB genauer aufschlüsseln wollen, z.b. wenn möglich in 512k-Sequenzen. Dann wär man sicher, ob es nicht 2x4MB (untereinander immer noch schnell angebunden) oder doch andere "Anomailen" (Als unwarscheinliches Bsp HT3.0 mit der 1MB-Reservierung)
Wenn dagegen das mit den 2x4 MB pro 2 Kerne zutrifft, dann wär es für AMD durchaus einfach, irgendwann 6-Kern-CCX aufzulegen, wie z.B. für den geplanten 48-Kern-Naples.
Wenn dagegen das mit den 2x4 MB pro 2 Kerne zutrifft, dann wär es für AMD durchaus einfach, irgendwann 6-Kern-CCX aufzulegen, wie z.B. für den geplanten 48-Kern-Naples.
So wie es hier ausgegeben wird würde ich die Cachesituation so interpretieren als das 4-Kerne jeweils ein 8MB-Segment zusammen haben.Also Core0-4 L3-1 mit 8MB ("lokalisiert" an Kern1). Die anderen Kerne aus Block 0-4 greifen dann wohl über Core1 auf den Cache zu ?
Genau.
Erwarten würde ich daher dass er bei >8MB dramatisch langsamer wird...
Ist ja auch so; guck dir die Werte an.
1. Aus der obigen Liste würde ich daher erwarten dass bei >32kb was passiert weil der Instruction cache zu ist.
I-Cache ist sowieso schwierig zu messen, erst recht mit sowas wie einem uOp-Cache.
Als nächstes würde ich erwarten dass der L2 cache bis 512kB arbeitet..:
---------------- Check...Latenz =4x L1 ?
Nur weil der x fach so groß ist heißt das nicht, dass der die x-fache Latenz hat.
Die Sonderbarkeit könnte aber das "Interleaving" innerhalb eines CCX sein ? Evtl. sind das nochmal 2x4MB Blöcke ? die zwischen jeweils 2 Kernen sitzen?
Wenn die interleaved wären, dann wäre die Latenz von 4MB auf 8MB konstant.
Ich nehme an, dass das Pesudo-LRU-Replacement zwischen den beiden Hälften so ist, dass erst die Kern-nähere Hälfte benutzt wird und dann die entferntere, und deswegen die Latenz von 4MB auf 8MB so ansteigt.
Evtl gibt es auch noch eine "Brücke direkt zwischen den Caches, würde aber vielleicht erklären warum es genau doppelt so lange dauert um 4MB zu addressieren...mit 1 Fetch kann nur aus 1 Block parallel gelesen werden...um in den zweiten Block zu kommen brauchts 1 extra Runde ?
Mein Benchmark macht Pointer-Chasing, da wird überhauptnichts parallel gelesen; ansonsten wär die Latenz nicht messbar.
Weiter ist ja dann der 2.8MB L3 cache auf dem anderen CCX zu finden...das würde ich so verstehen dass man da dann über die IF zugreift und diese läuft mit dem RAM-Takt.
-----Check...cross-CCX-Latenz = RAM-Latenz
Ich habe einen anderen Benchmark geschrieben der misst wie lange es dauert damit eine Cachezeile von einem Kern in einem CCX zu einem anderen Kern in einem anderen CCX zu übertragen. Das dauert so ca. 550 Takte. Das ist so schlecht, dass man annehmen könnte, AMD hat das so gemacht, dass eine Cachezeile per-se erstmal von einem CCX ins RAM zurückgeschrieben und wieder von einem anderen CCX von dort gelesen wird. Könnte sein, muss aber nicht.
Zuletzt bearbeitet:
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Lesen und schreiben beim RAM geht doch schon seit dem FX Zeitgleich, nennt sich unganged Dual Channel (2x 72Bit mit ECC).Ich habe einen anderen Benchmark geschrieben der misst wie lange es dauert damit eine Cachezeile von einem Kern in einem CCX zu einem anderen Kern in einem anderen CCX zu übertragen. Das dauert so ca. 550 Takte. Das ist so schlecht, dass man annehmen könnte, AMD hat das so gemacht, dass eine Cachezeile per-se erstmal von einem CCX ins RAM zurückgeschrieben und wieder von einem anderen CCX von dort gelesen wird. Könnte sein, muss aber nicht.
Von AMD gab es bezüglich Fabric noch die Unterteilung in Control Fabric und Data Fabric:


Ja - dann stimmt ja im wesentlichen alles was ich gesagt habe mit deinen Resultaten gut überein.
Bleibt eigentlich nur die "anomalie" bei 4MB.
Ich glaub nicht dass die Entfernung hier eine wesentliche Rolle spielt - die Abstände sind da viel zu kurz und wenn der Kommunikationsweg direkt ist dann spielt das für die Latenz nicht so eine Rolle ob das nun 5mm oder 6mm Distanz sind.
Meiner laienhaften Einschätzung nach muss es dann eher so sein dass die Kommunikation hier erst einen "umweg" machen muss über einen anderen Schalter. Was eigentlich nur Sinn macht wenn quasi Jeder Kern (oder zumindest jedes Kern-Paar) hier einen "eigenen" L3-Cache hat. Der dann wieder hierarchisch mit allen anderen Kernen des CCX, und dann weiter hierarchisch Cross-CCX genutzt wird.
Inwiefern das die Performance nun einbremst kann ich schwer beurteilen. Vermutlich ist aber so ein Ansatz bei Multi-Threading bzw. All-Core Nutzung dann wieder im Vorteil da die Daten Lokal auf dem jeweiligen Kerncache gelagert werden ?
Wieviel Takte dauert es denn eine Cachezeile innerhalb eines CCX zu übertragen ? Oder sind das genau die Zahlen oben ?
Bleibt eigentlich nur die "anomalie" bei 4MB.
Ich nehme an, dass das Pesudo-LRU-Replacement zwischen den beiden Hälften so ist, dass erst die Kern-nähere Hälfte benutzt wird und dann die entferntere, und deswegen die Latenz von 4MB auf 8MB so ansteigt.
Ich glaub nicht dass die Entfernung hier eine wesentliche Rolle spielt - die Abstände sind da viel zu kurz und wenn der Kommunikationsweg direkt ist dann spielt das für die Latenz nicht so eine Rolle ob das nun 5mm oder 6mm Distanz sind.
Meiner laienhaften Einschätzung nach muss es dann eher so sein dass die Kommunikation hier erst einen "umweg" machen muss über einen anderen Schalter. Was eigentlich nur Sinn macht wenn quasi Jeder Kern (oder zumindest jedes Kern-Paar) hier einen "eigenen" L3-Cache hat. Der dann wieder hierarchisch mit allen anderen Kernen des CCX, und dann weiter hierarchisch Cross-CCX genutzt wird.
Inwiefern das die Performance nun einbremst kann ich schwer beurteilen. Vermutlich ist aber so ein Ansatz bei Multi-Threading bzw. All-Core Nutzung dann wieder im Vorteil da die Daten Lokal auf dem jeweiligen Kerncache gelagert werden ?
Ich habe einen anderen Benchmark geschrieben der misst wie lange es dauert damit eine Cachezeile von einem Kern in einem CCX zu einem anderen Kern in einem anderen CCX zu übertragen. Das dauert so ca. 550 Takte.
Wieviel Takte dauert es denn eine Cachezeile innerhalb eines CCX zu übertragen ? Oder sind das genau die Zahlen oben ?
Sind die Ergebnisse eigentlich mit jenen der CPUID-Software "Cache latency" [1] vergleichbar?
[1] - http://download.cpuid.com/misc/latency.zip
[1] - http://download.cpuid.com/misc/latency.zip
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 985
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS PRIME X370-PRO
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Sieh selbst (zwei Durchläufe):
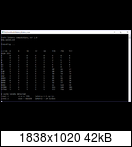
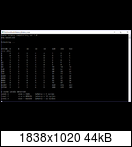


Lesen und schreiben beim RAM geht doch schon seit dem FX Zeitgleich, nennt sich unganged Dual Channel (2x 72Bit mit ECC).
Die Datenleitungen sind nur einmal da. Aber sicher kann ein nächster Lese-/Schreib-vorgang initiiert werden während der Burst eines vorangegangenen läuft. Das hat nichts mit FX zu tun, sondern ist generell so seit es SDRAM gibt.
--- Update ---
Wieviel Takte dauert es denn eine Cachezeile innerhalb eines CCX zu übertragen ? Oder sind das genau die Zahlen oben ?
Ca. 150 Takt, also fast ein Viertel.
--- Update ---
Sind die Ergebnisse eigentlich mit jenen der CPUID-Software "Cache latency" [1] vergleichbar?
[1] - http://download.cpuid.com/misc/latency.zip
Von L1 und L2 ja, von L3 nicht. Und dieses Tool misst noch einen nicht vorhandenen L4-Cache; seltsames Ding.
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
Hoppela, den unganged Mode gibt es schon seit dem Phenom 1 aber beim FX ist er auch noch aktuell.Die Datenleitungen sind nur einmal da. Aber sicher kann ein nächster Lese-/Schreib-vorgang initiiert werden während der Burst eines vorangegangenen läuft. Das hat nichts mit FX zu tun, sondern ist generell so seit es SDRAM gibt.

128Bit IMC der in 2x 64Bit aufgeteilt wird so das zwei Instanzen zeitgleich lesen und schreiben können.
Natürlich nur wenn die Ergebnise nicht aufeinander abhängig sind...
Kein Kommentar zu der verlinkten Grafik der Infinity Fabric?
Sieh selbst (zwei Durchläufe):
1. Testlauf:
L1 = 32KB, Latenz 4 Zyklen
L2 = 8192KB, Latenz 24 Zyklen =6xL1
2. Testlauf:
L1 = 32KB, Latenz 3 Zyklen
L2 = 4096KB, Latenz 18 Zyklen =6xL1
L3 = 8192KB, Latenz 52 Zyklen =14xL1 bzw ~3xL2 ?
Wie kann es sein dass so ein Tool einmal 2 Caches und einmal 3 Caches findet ?
Btw. die Cachegrößen korrelieren doch sehr gut mit den Werten hier von Flodul ?
Floduls Test findet ja:
L1 = 32KB, Latenz ~4 Zyklen
L2 = 512KB, Latenz ~16 Zyklen = x4 L1
L3' = 4096KB, Latenz ~24 Zyklen = x6 L1
L3'' = 8192KB, Latenz ~48 Zyklen = x12 L1
L4 = System RAM bzw. Infinity Fabric >8192KB, Latenz = 167 Zyklen ~ 42x L1
EDIT keine Ahnung wie man hier die gefundenen 550 Zyklen reininterpretieren kann für den Cross-CCX Code.
Zuletzt bearbeitet:
Hoppela, den unganged Mode gibt es schon seit dem Phenom 1 aber beim FX ist er auch noch aktuell.
Es geht mir nicht um die unganged Mode, sondern darum, dass SDRAM pipelined arbeiten kann.
EDIT keine Ahnung wie man hier die gefundenen 550 Zyklen reininterpretieren kann für den Cross-CCX Code.
Es geht mir nicht um die Latenz eines Transfers vom Speicher in einen Kern, sondern von einem Kern in einem CCX zu einem anderen Kern in einem anderen CCX. Das ist extrem tricky zu messen, und es würde mich wundern wenn es vor mir jemand gemessen hat.
Zuletzt bearbeitet:
@SPINA: Vielen Dank für die zwei Durchläufe. Das Ergebnis ist in der Tat interessant. Vergleicht man die eigentlichen Messergebnisse beider Testläufe miteinander, so fällt insbesondere in der Zeile 8192 eine deutliche Diskrepanz auf.
Durchlauf 1: 8192 x 128,256,512: 025, 121, 058 (<- unlogisch)
Durchlauf 2: 8192 x 128,256,512: 035, 047, 074
Ich nehme an, der Rechner hatte während des Tests absolut nichts zu tun (Browser aus, Internet aus, ...)?
Sofern die unterschiedlichen Ergebnisse reproduzierbar sind, könnte man versuchen das latency-Programm auf bestimmten Kernen starten zu lassen. Wie das geht, steht hier im Eröffnungspost:
http://stackoverflow.com/questions/2976600/start-affinity-equivalent-in-net
Mal so am Rande noch ein Gedanke bezüglich AMD Ryzen vs. Intel Core-i... :
Was vergleichen wir hier eigentlich? Bei den Core-i Prozessoren gibt es zwei "Arten" von L3-Cache-Designs. Die Doppelkern und Vierkernprozessoren haben meines Wissens einen kleinen L3-Cache, der auf schnelles Ansprechen optimiert ist. Dafür ist der nicht wirklich skalierbar, bei 8 MB ist Schluss.
Die großen Core-i ab 6 Kernen haben separierte L3-Cache-Segmente, die per Ringbus vernetzt sind. Die sind langsamer, insbesondere bei den richtig fetten Dies, aber recht gut skalierbar (auf Kosten der Latenz).
AMD kann sich scheinbar keine zwei Dies für Ryzen leisten, statt dessen werden aus einem mittelgroßen Die durch Abschalten von Kernen normale Desktop-Prozessoren und durch das Zusammenschalten von mehreren Dies richtige Server-CPUs gefertigt. Die Cache-Architektur richtet sich scheinbar nach dem Maximalausbau mit vier Dies pro Sockel und zwei Sockeln.
Da ist es wenig verwunderlich, wenn diese sehr universell einsetzbare Cache-Struktur hinter den auf die jeweiligen Prozessor maßgeschneiderter Strukturen bei Intel zurück fällt.
Durchlauf 1: 8192 x 128,256,512: 025, 121, 058 (<- unlogisch)
Durchlauf 2: 8192 x 128,256,512: 035, 047, 074
Ich nehme an, der Rechner hatte während des Tests absolut nichts zu tun (Browser aus, Internet aus, ...)?
Sofern die unterschiedlichen Ergebnisse reproduzierbar sind, könnte man versuchen das latency-Programm auf bestimmten Kernen starten zu lassen. Wie das geht, steht hier im Eröffnungspost:
http://stackoverflow.com/questions/2976600/start-affinity-equivalent-in-net
Mal so am Rande noch ein Gedanke bezüglich AMD Ryzen vs. Intel Core-i... :
Was vergleichen wir hier eigentlich? Bei den Core-i Prozessoren gibt es zwei "Arten" von L3-Cache-Designs. Die Doppelkern und Vierkernprozessoren haben meines Wissens einen kleinen L3-Cache, der auf schnelles Ansprechen optimiert ist. Dafür ist der nicht wirklich skalierbar, bei 8 MB ist Schluss.
Die großen Core-i ab 6 Kernen haben separierte L3-Cache-Segmente, die per Ringbus vernetzt sind. Die sind langsamer, insbesondere bei den richtig fetten Dies, aber recht gut skalierbar (auf Kosten der Latenz).
AMD kann sich scheinbar keine zwei Dies für Ryzen leisten, statt dessen werden aus einem mittelgroßen Die durch Abschalten von Kernen normale Desktop-Prozessoren und durch das Zusammenschalten von mehreren Dies richtige Server-CPUs gefertigt. Die Cache-Architektur richtet sich scheinbar nach dem Maximalausbau mit vier Dies pro Sockel und zwei Sockeln.
Da ist es wenig verwunderlich, wenn diese sehr universell einsetzbare Cache-Struktur hinter den auf die jeweiligen Prozessor maßgeschneiderter Strukturen bei Intel zurück fällt.
SPINA
Grand Admiral Special
- Mitglied seit
- 07.12.2003
- Beiträge
- 18.122
- Renomée
- 985
- Mein Laptop
- Lenovo IdeaPad Gaming 3 (15ARH05-82EY003NGE)
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- ASUS PRIME X370-PRO
- Kühlung
- AMD Wraith Prism
- Speicher
- 2x Micron 32GB PC4-25600E (MTA18ASF4G72AZ-3G2R)
- Grafikprozessor
- Sapphire Pulse Radeon RX 7600 8GB
- Display
- LG Electronics 27UD58P-B
- SSD
- Samsung 980 PRO (MZ-V8P1T0CW)
- HDD
- 2x Samsung 870 QVO (MZ-77Q2T0BW)
- Optisches Laufwerk
- HL Data Storage BH16NS55
- Gehäuse
- Lian Li PC-7NB
- Netzteil
- Seasonic PRIME Gold 650W
- Betriebssystem
- Debian 12.x (x86-64)
- Verschiedenes
- ASUS TPM-M R2.0
Es liefen nur die notwendigen Systemprozesse im Hintergrund. Allerdings waren Stromsparmechanismen in Kraft, die das Ergebnis durchaus verfälscht haben können. Zwar war das Profil "Höchstleistung" als Energiesparplan ausgewählt, aber ich habe das Profil so angepasst, dass Cool'n'Quiet nicht außer Kraft gesetzt wird. Jedenfalls fiel das Ergebnis inkonsistent und nicht reproduzierbar aus. Die zwei Durchläufe waren eine Auswahl.Ich nehme an, der Rechner hatte während des Tests absolut nichts zu tun (Browser aus, Internet aus, ...)?
WindHund
Grand Admiral Special
- Mitglied seit
- 30.01.2008
- Beiträge
- 12.224
- Renomée
- 535
- Standort
- Im wilden Süden (0711)
- Mitglied der Planet 3DNow! Kavallerie!
- Aktuelle Projekte
- NumberFields@home
- Lieblingsprojekt
- none, try all
- Meine Systeme
- RYZEN R9 3900XT @ ASRock Taichi X570 & ASUS RX Vega64
- BOINC-Statistiken
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5950X
- Mainboard
- ASRock 570X Taichi P5.05 Certified
- Kühlung
- AlphaCool Eisblock XPX, 366x40mm Radiator 6l Brutto m³
- Speicher
- 2x 16 GiB DDR4-3600 CL26 Kingston (Dual Rank, unbuffered ECC)
- Grafikprozessor
- 1x ASRock Radeon RX 6950XT Formula OC 16GByte GDDR6 VRAM
- Display
- SAMSUNG Neo QLED QN92BA 43" up to 4K@144Hz FreeSync PP HDR10+
- SSD
- WD_Black SN850 PCI-Express 4.0 NVME
- HDD
- 3 Stück
- Optisches Laufwerk
- 1x HL-DT-ST BD-RE BH10LS30 SATA2
- Soundkarte
- HD Audio (onboard)
- Gehäuse
- SF-2000 Big Tower
- Netzteil
- Corsair RM1000X (80+ Gold)
- Tastatur
- Habe ich
- Maus
- Han I
- Betriebssystem
- Windows 10 x64 Professional (up to date!)
- Webbrowser
- @Chrome.Google & Edge Chrome
@SPINA
Das Latency von CPUID ist relativ alt, dennoch hat es sich bewährt über die Jahre.
Bei SIV64X ist es auch implementiert, dort lassen sich auch die Kerne/Module auswählen: http://abload.de/img/siv64x_cache_lattek8ok9.jpg
Zudem findet sich dort noch ein interessanter Test: "Memory Areas" nach dem klicken auf "Speed" wird ein Datentransfer durch Virtual Maschines erzeugt.
Bei mir sind in 15 Sekunden 28 GByte voll und werden gehalten: http://abload.de/img/siv64x_mem_areaswarir.jpg
Das Latency von CPUID ist relativ alt, dennoch hat es sich bewährt über die Jahre.
Bei SIV64X ist es auch implementiert, dort lassen sich auch die Kerne/Module auswählen: http://abload.de/img/siv64x_cache_lattek8ok9.jpg
Zudem findet sich dort noch ein interessanter Test: "Memory Areas" nach dem klicken auf "Speed" wird ein Datentransfer durch Virtual Maschines erzeugt.
Bei mir sind in 15 Sekunden 28 GByte voll und werden gehalten: http://abload.de/img/siv64x_mem_areaswarir.jpg
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 789
- Antworten
- 0
- Aufrufe
- 912
- Antworten
- 0
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 52K