Über einige Details, z.B. die AVX-Erweiterung, konnten wir ja bereits in unserer alten Nachricht vom 21. Juli berichten. Desweiteren haben sich unsere Spekulationen zum Cache-Aufbau und der FPU-Breite bewahrheitet. Erstens bekommt Jaguar wirklich einen 2 MB großen, gemeinsam genutzten L2-Cache, der in vier Kacheln à 512 kB unterteilt ist:
Ein einzelner Thread hat dadurch vollen Zugriff auf 2 MB, was v.a. der Single-Thread-Leistung zu Gute kommt. Außerdem ist der L2, ähnlich wie der L3 bei den aktuellen Intel-Prozessoren, inklusive organisiert. Das bedeutet zwar, dass insgesamt 2x32x4= 256kByte der 2 MB verloren gehen, dafür verbessert sich aber die Multi-Thread-Leistung und Inter-Prozess-Kommunikation, da alle Kerne über den gemeinsamen L2 den Status und den Inhalt der restlichen CPU-Kerne abfragen können.
Zweitens bewahrheitete sich auch unsere Spekulation zur FPU. Diese wird wirklich von 64 Bit auf 128 Bit verbreitet. Für FPU-lastige Szenarien kann man also eine ähnliche Verbesserung wie vom K8 auf den K10 erwarten.
Aber schauen wir uns das gute Stück erst einmal im Vergleich zum Bobcat an:
Auf den ersten Blick kann man eigentlich erst einmal nur den größeren Bereich der FPU bemerken, der sich schlicht durch die bereits erwähnte Verdoppelung auf 128 Bit erklärt. Interessant ist die Randnotiz am Bildende, dass Jaguar aus nur 3 unterschiedlichen Transistorenzellen-Designs besteht, während Bobcat noch 7 verschiedene Sorten benutzte. Das bedeutet, dass das Design einfacher auf andere Prozesse, z.B. zu Globalfoundries portiert werden könnte.
Für weitere Details ist man dann auf die nächsten AMD-Folien zu den Architektur-Infos angewiesen:
Im Folgenden fassen wir alle Informationen zusammen:
1. Front-End
1.1 x86-Dekoder-Einheit:
Ähnlich wie die Intel-Chips seit der Conroe-Generation bekommt Jaguar auch einen Loop-Detection-Buffer spendiert, welcher die bereits dekodierten µOps von sich wiederholenden Schleifen-Instruktionen zwischenspeichert und somit die Dekodier-Einheit entlastet. Als Grund werden Stromspar-Maßnahmen angegeben, da der Dekoder in diesem Falle abgeschaltet werden kann. Aber natürlich bekommt man nebenbei auch einen Leistungsschub, da der kleine 32-Byte-Zwischenspeicher die µOps viel schneller liefern kann als der Dekoder.
1.2. Sonstiges Wie auch in den anderen Kernabschnitten wurden einige Puffer vergrößert. Im Front-End-Fall ist dabei der Instruktion-Puffer zu nennen, der sich zwischen der Fetch- und Decoder-Einheit befindet. Zusätzlich wurde auch der Prefetcher für den L1-Instruktionscache verbessert.
2. Rechenwerke
2.1 Größere OoO-Puffer Aus der "Viel-hilft-viel"-Schublade ist diese Verbesserung. AMD vergrößert beim Jaguar einige Puffer, die für die Out-of-Order-Ausführung zuständig sind. Solche Verbesserungen werden bei DIE-Shrinks immer gerne gemacht.
2.2. Integer-Divisor Wie auch schon Bulldozer (aktiviert erst im Trinity, wir berichteten) oder auch Llano (wir berichteten) bekommt auch Jaguar eine Integer-Dividier-Einheit verpasst. Praktischerweise nimmt man einfach die des Llanos.
2.3 Sonstiges Der Vollständigkeit halber wollen wir hier auch die schon in der Einleitung genannten 128-Bit-Fähigkeit der FPU-Pipelines nennen. 256 Bit AVX-Befehle werden dabei also wie schon aktuell beim Bulldozer in zwei Pakete à 128 Bit aufgeteilt.
3. Load/Store Einheit
Lade- und Speicheroperationen erfuhren ebenfalls ein paar Verbesserungen, so wurde z.B. das Load to Store Forwarding (STLF), das dem ein oder anderen eventuell besser unter Intels Bezeichnung "Memory Disambiguity" bekannt ist, verbessert. Desweiteren wurden auch hier einige Puffer vergrößert und die Logik, welche die nächste µOp aus dem OoO-Puffer bestimmt, wurde verbessert.
Adressierbarkeit Ein kleines Detail mit eventuell großer Wirkung versteckt sich auf dieser eher unscheinbaren Folie:
Neben den bereits bekannten Details zu den unterstützten Befehlssatzerweiterungen sieht man, dass Jaguars Speicherkontroller 40 Bit adressieren. Bisher war das Limit bei 36 Bit, was für einen Prozessor der Jaguar Klasse eigentlich locker ausreicht, da die 36 Bit 64 GB bedeuten. Mit 40 Bit zieht man nun mit dem alten K8 gleich, der ebenfalls 1 Terabyte adressieren konnte. Aktuelle CPUs seit dem K10 adressieren aber bereits 48 Bit. Trotzdem dürfte damit klar sein, dass AMD den Jaguar-Kern mit an Sicherheit grenzender Wahrscheinlichkeit auch im Server-Bereich positionieren wird. 64 GB wären für Tablets, Notebooks, HTPCs und kleine Office-Rechner schließlich auch weiterhin noch genug.
Pipeline-Vergleich
Die Pipeline hat sich im Vergleich zum Bobcat fast nicht geändert, zuerst die Bobcat-Pipeline aus unserem Bobcat-Artikel:
Und nun die Jaguar-Pipeline:
Wie man sieht gibt es zwei Neuerungen. Erstens gibt es eine zusätzliche Stufe am Ende der Dekodier-Einheit und dann zweitens eine weitere Stufe zum Registerlesen in der FPU. Letzteres ist vermutlich der 128-Bit-Verbreiterung geschuldet. Erster sicherlich aufgrund der Abfrage des Loop-Buffers nötig. Offiziell sind beide Pipelinestufen einer höheren Frequenz geschuldet. Das stimmt natürlich auch, denn wenn man beide Verbesserungen in bereits vorhandene Stufen zwängen hätte müssen, wäre das Design sicherlich nicht ausbalanciert gewesen. Im Endeffekt sind die beiden Zusatzstufen aber schlicht die Ursache der Mikroarchitektur-Verbesserungen und sicherlich kein anfängliches Designziel.
Die L1D-Latenz bleibt weiterhin bei 3 Takten.
Resultat
Lohn der ganzen Mühen ist am Ende eine um >15% gestiegene IPC (1,10 statt 0,95):
Damit bewegt man sich in K10-Regionen, allerdings wird ein Dual- bzw. Quadprozessor mit Jaguar-Kernen deutlich weniger Strom verbrauchen als man es von seinem Phenom II gewohnt ist. Genaue Informationen hierzu, oder zu den Taktraten, gibt es aber nicht. Zu Letzterem gibt es nur die grobe Info, dass sich 10% höhere Takte ggü. Bobcat bewerkstelligen ließen. Aktuell würde das für Jaguars Dual-Core-Version somit um die 1,9 Ghz bedeuten, da der aktuell schnellste Bobcat, der E2-1800, mit 1,7 Ghz läuft.
Fazit
Jaguar sieht nach einem runden, gelungenen Design aus. Viele Puffer wurden vergrößert, die FPU-Resourcen verdoppelt, AVX-Unterstützung nachgerüstet, ein schon lange bei Intel üblicher Loop-Cache eingebaut, das Cache-Design überholt und erstmals wird es auch eine Quad-Core-Version geben. Sollte es seitens TSMC keine Produktionsprobleme geben, sollte der Erfolg garantiert sein. Solange Intel seinen Atom-Nachfolger nicht auf dem Markt bringt, könnten die auf Jaguar basierenden APUs den blauen x86-Riesen eventuell sogar dazu zwingen, Sandy- oder Ivy-Bridge ULV-Typen zu verbilligten Konditionen anzubieten, um überhaupt ein Konkurrenzprodukt aufweisen zu können.
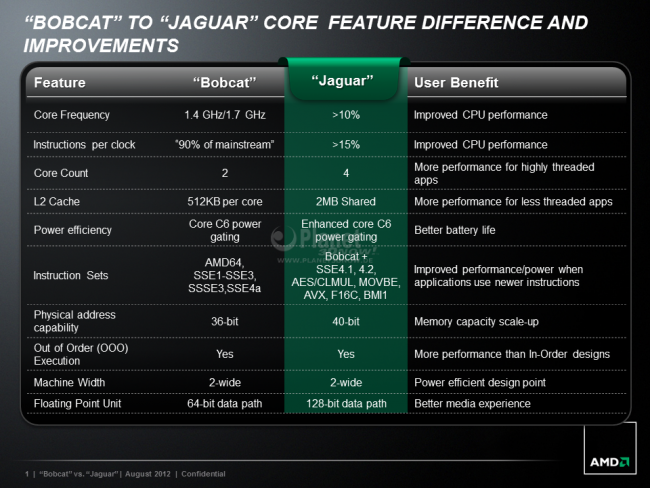
Update 30.08.2012: Gerade erreichte uns noch diese zusammenfassende Folie, die einen schnellen Überblick aller Verbesserungen ermöglicht und uns nun als Abschluss dienen soll:
Den vollständigen Foliensatz zum Jaguar kann man in unserer Galerie finden.








Diesen Artikel bookmarken oder senden an ...













