App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Intel Haswell - AVX2 | FMA3 | 22nm
- Ersteller Duplex
- Erstellt am
Duplex
Admiral Special
Intel Haswell (Sockel 1150) Gerüchte + FAQ + Infos [Sammelthread]

Facts:
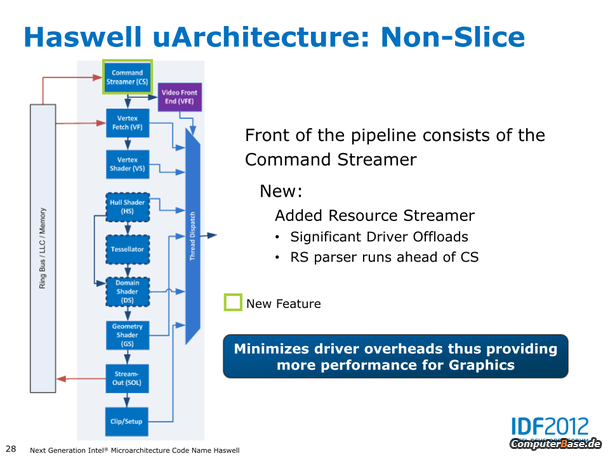
Mit Haswell steht im nächsten Jahr eine neue Intel-Prozessorengeneration für das Mainstream-Segment an.
Der Prozessor wird zwar wieder in 22 nm gefertigt, besitzt diesmal aber im Vergleich zu Ivy Bridge über eine neue Mikroarchitektur.
Im Fokus steht diesmal vor allem die Grafikeinheit, während sich beim reinen Prozessorteil hinsichtlich der Taktraten fast nichts tut.
Dort soll neben der erhöhten Anzahl an Ausführungseinheiten auch noch eine völlig neue Architektur zum Einsatz kommen.
Außerdem können die alten Mainboards (Sockel 1155, Intel Sandy und Ivy Bridge) nicht mehr eingesetzt werden, da auf einen neuen Sockel LG1150 gesetzt wird.
Voraussichtlicher Release: Q2/2013
Fertigung: 22 nm (3D-Transistoren)
TDP: 84 W
Grafikeinheit: Intel HD 4600
Sockel: LGA 1150
Chipsätze: Z87, H87 und B85 sowie Q87, Q85 und H81 ("Lynx Point"-Chipsätze)
Versionen: K = Freier Multiplikator, S = Stromspar, T = Noch mehr Stromspar/Niedrigere TDP (+Takt), ULV = Ultra Low Voltage (Stromspar + architektonische Änderung)
Änderungen und Verbesserungen:
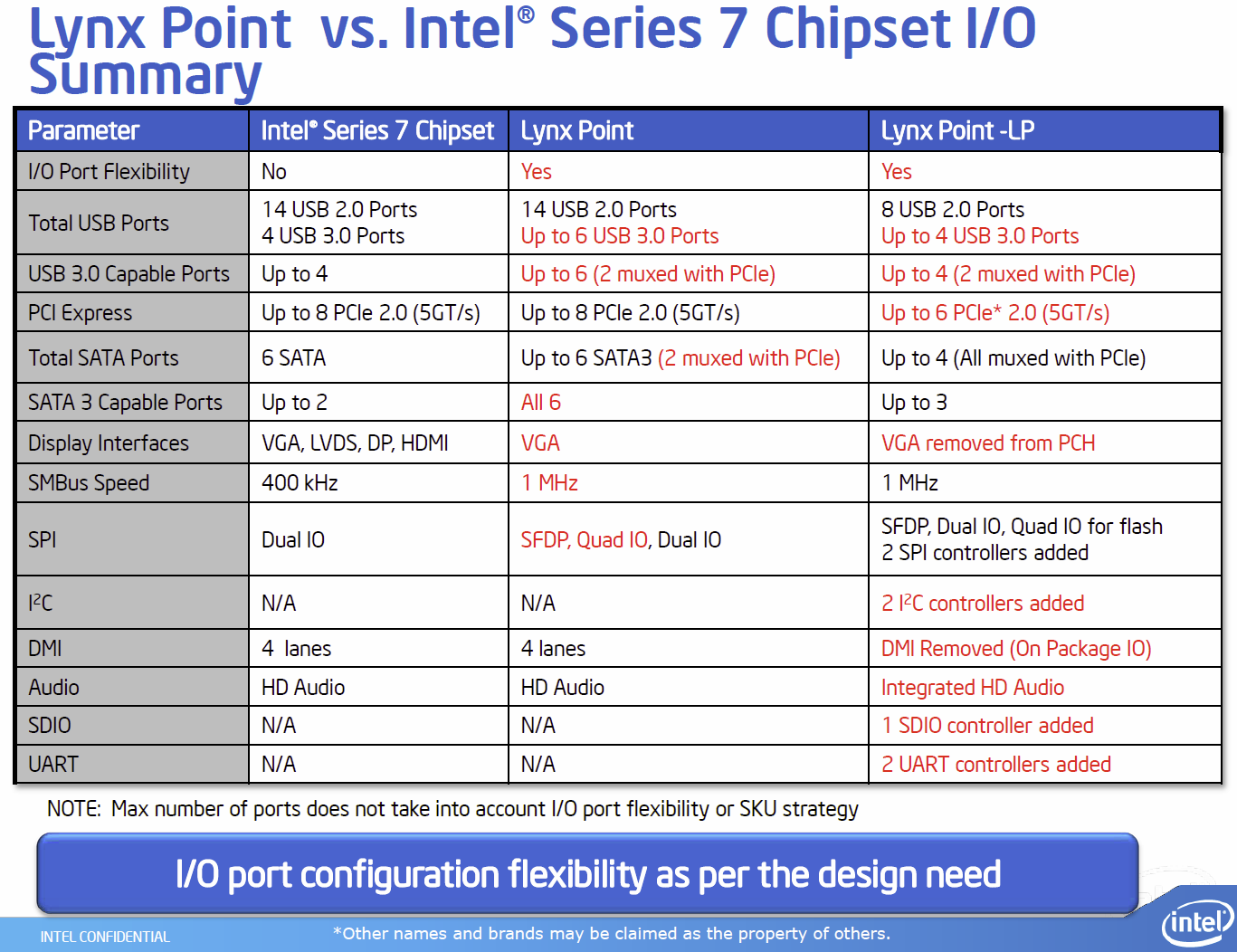
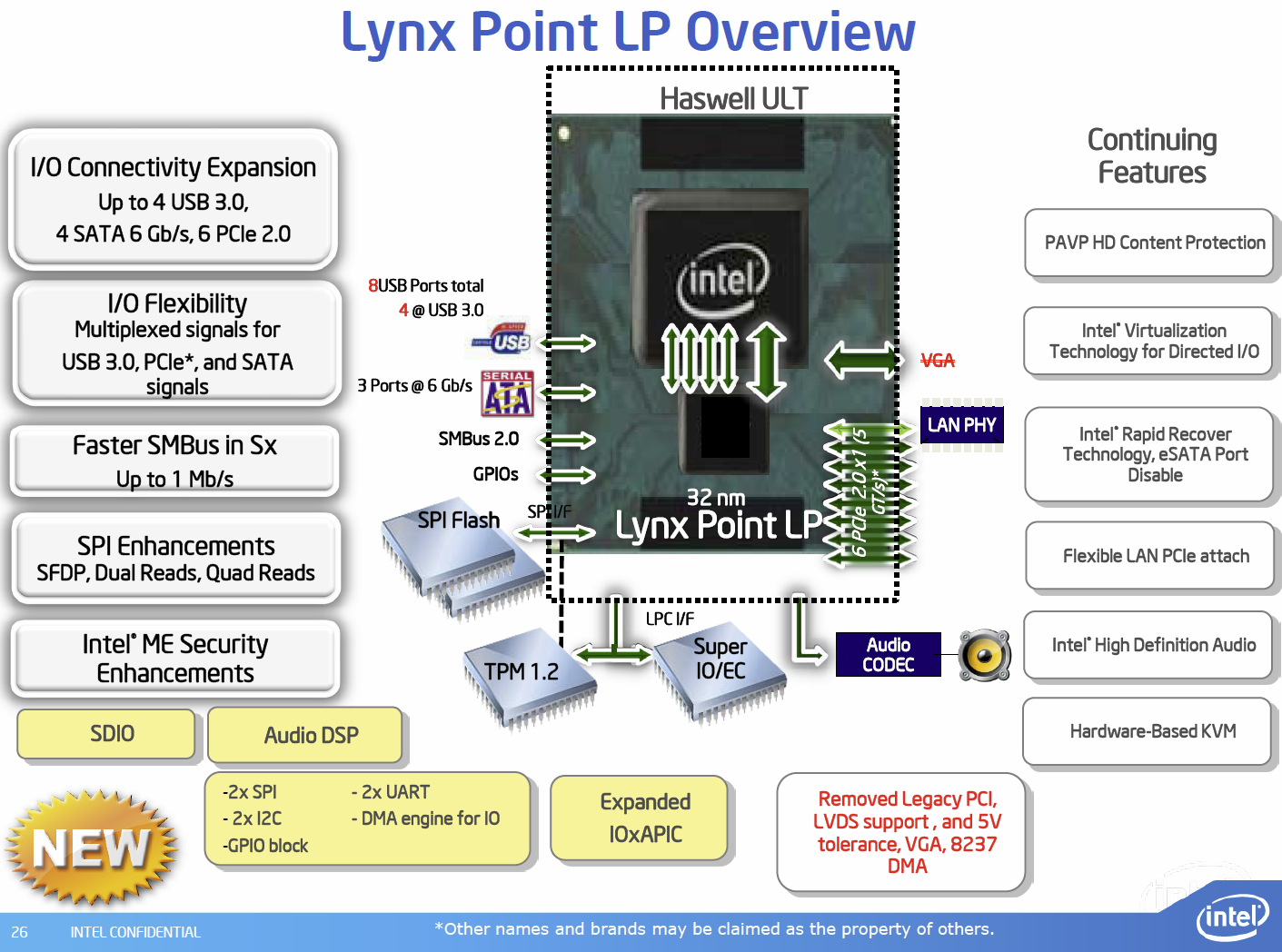
Chipset:
- "Lynx Point"-Chipsätze: Z87, H87 und B85 sowie Q87, Q85 und H81
- Fertigung in 32nm statt 65nm, also stromsparender
- 4 native USB-3.-0-Anschlüsse
- Bis zu 6 native SATA-6GB/s-Ports
- Mehr Details im Sammelthread: http://www.hardwareluxx.de/communit...cs-bilder-z87-h87-h81-q87-q85-b85-902183.html



Core + System-Agent:
- 22nm aber neue Mikroarchitektur
- Multi-Chip-Packages (MCP) vereint Chipsatz und Prozessor auf einem Träger, sowie On Package Interface (OPI), das als eine angepasste Version des DMI den Chipsatz mit dem Prozessor verbindet
- Bei erreichen des TJmax throttelt Chipset nun auch, auch wenn CPU diesen erreicht
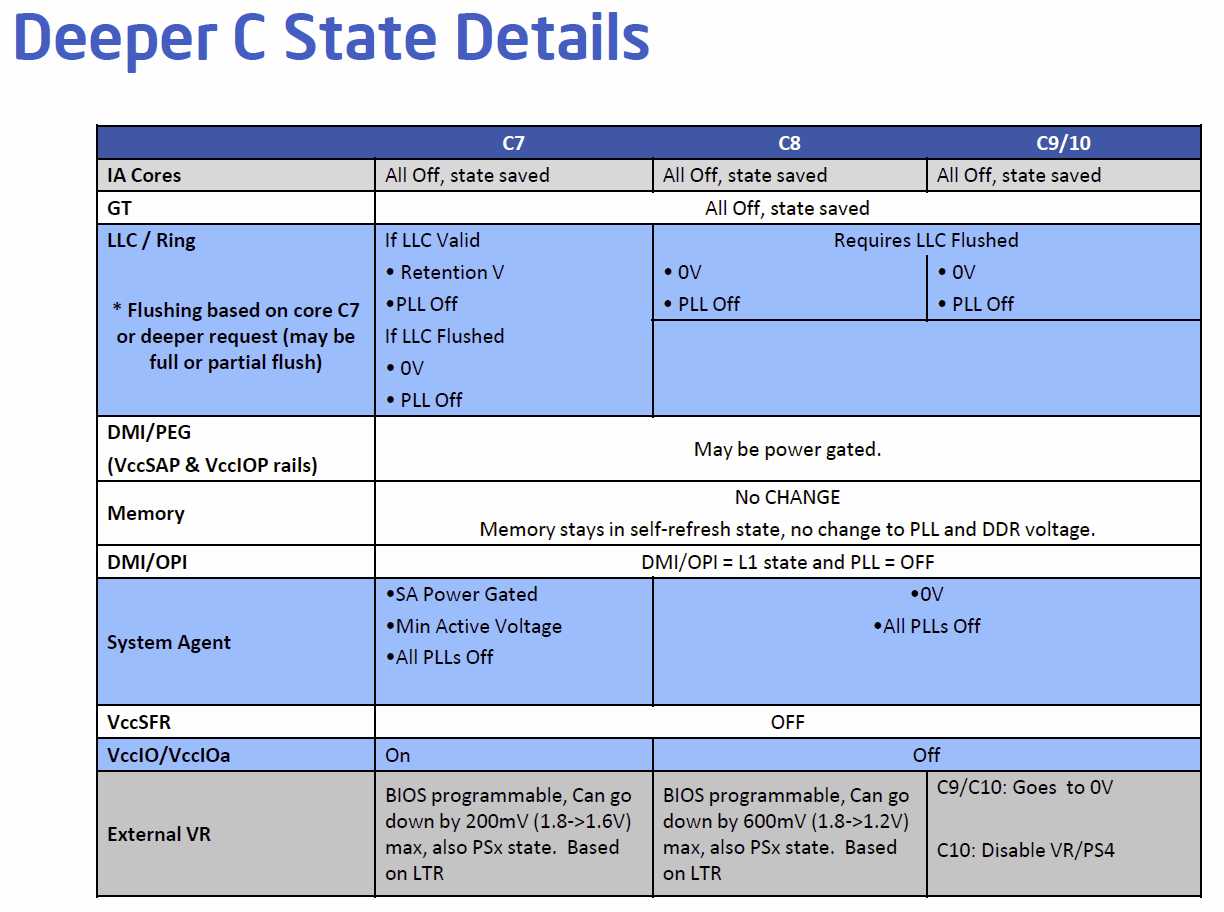
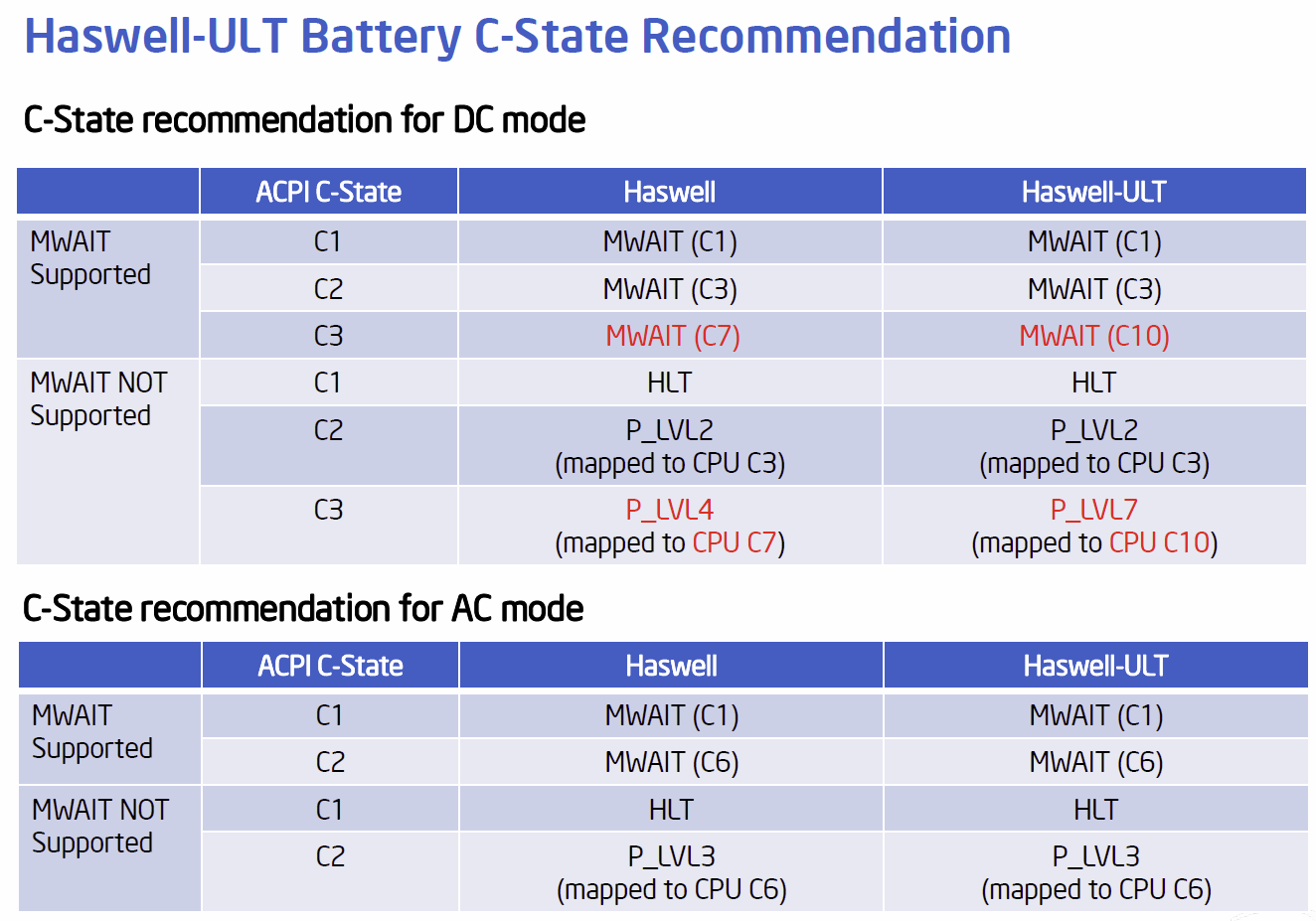
- Neue Stromsparmodi: Für Haswell: C0, C2E, C7 und für Haswell-UT: Zusätzlich C8, C9 und C10
- BCLK („Baseclock“) kann auch auf 24 abesenkt werden, ermöglicht niedrigere Taktraten im Idle und somit die Verbesserung der Effizienz bei Teillast und Idle
- Architektonische Änderungen: ULT Prozessoren besizten kein PCI-Express(-3.0)-Support, kein Overclocking usw.
- Vielleicht bei den Modellen für Enthusiasten BLCK Straps
- Speicherunterstützung mit bis zu DDR3-1600







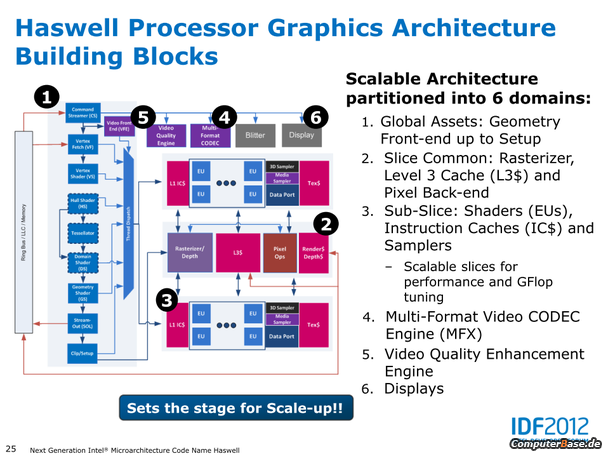
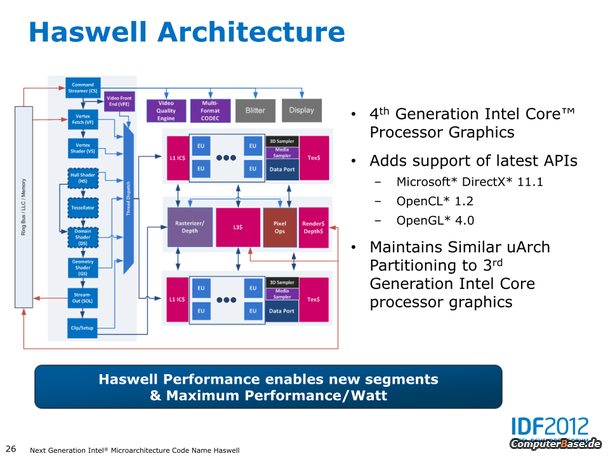
iGPU (HD 4600):
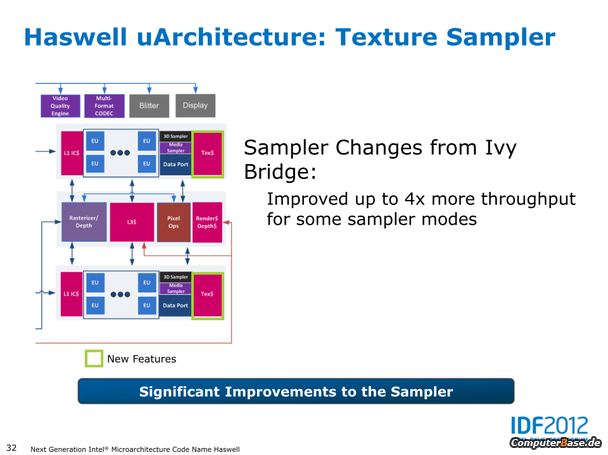
- Unterstützung von DirectX 11.1, OpenCL 1.2 sowie OpenGL 4.0
- Vermutliche Unterstützung der 4K-Auflösung (4.096 Pixel in der Breite)
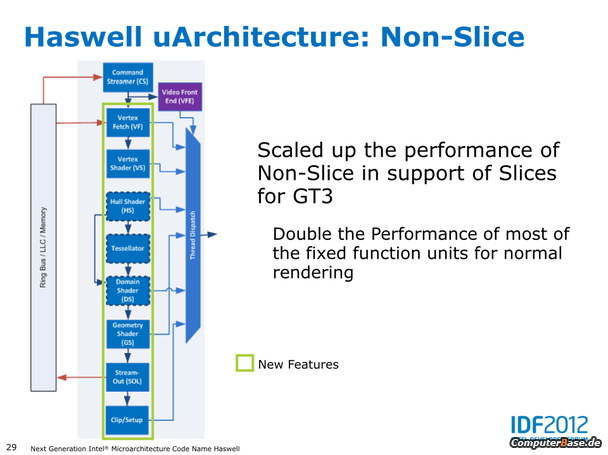
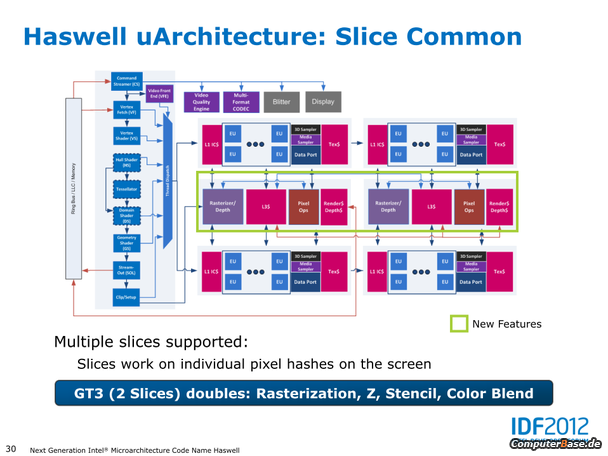
- Die iGPUs werden intern wie bisher auch als GT1 (6-10 EUs) und GT2 (26-30 EUs) benannt, hinzu kommt bei Haswell als neue Lösung erstmals GT3 (40 EUs)
- Die neue iGPU aller (!) Haswell Desktop Prozessoren wird vermutlich die HD 4600 sein – die bisher als GT2 gehandelte Einheit mit 20 EUs
- Statt bisher 16 Execution Units nun also 20 oder sogar 40, wobei die GT3-Lösung mit 40 EUs nach bisherigen Erkenntnissen nur im mobilen Segment genutzt werden soll
- Erweiterte Codec-Unterstützung für De- und Enkodierung von Videos, sowie eine eigenständige Video Quality Engine (VQE)
- Weitergeführte Leistungssteigerungen sowie Energiesparmaßnahmen













Haswell Prozessoren für den Desktop:

Haswell offizielle Testberichte
Facts:
Mit Haswell steht im nächsten Jahr eine neue Intel-Prozessorengeneration für das Mainstream-Segment an.
Der Prozessor wird zwar wieder in 22 nm gefertigt, besitzt diesmal aber im Vergleich zu Ivy Bridge über eine neue Mikroarchitektur.
Im Fokus steht diesmal vor allem die Grafikeinheit, während sich beim reinen Prozessorteil hinsichtlich der Taktraten fast nichts tut.
Dort soll neben der erhöhten Anzahl an Ausführungseinheiten auch noch eine völlig neue Architektur zum Einsatz kommen.
Außerdem können die alten Mainboards (Sockel 1155, Intel Sandy und Ivy Bridge) nicht mehr eingesetzt werden, da auf einen neuen Sockel LG1150 gesetzt wird.
Voraussichtlicher Release: Q2/2013
Fertigung: 22 nm (3D-Transistoren)
TDP: 84 W
Grafikeinheit: Intel HD 4600
Sockel: LGA 1150
Chipsätze: Z87, H87 und B85 sowie Q87, Q85 und H81 ("Lynx Point"-Chipsätze)
Versionen: K = Freier Multiplikator, S = Stromspar, T = Noch mehr Stromspar/Niedrigere TDP (+Takt), ULV = Ultra Low Voltage (Stromspar + architektonische Änderung)
Änderungen und Verbesserungen:
Chipset:
- "Lynx Point"-Chipsätze: Z87, H87 und B85 sowie Q87, Q85 und H81
- Fertigung in 32nm statt 65nm, also stromsparender
- 4 native USB-3.-0-Anschlüsse
- Bis zu 6 native SATA-6GB/s-Ports
- Mehr Details im Sammelthread: http://www.hardwareluxx.de/communit...cs-bilder-z87-h87-h81-q87-q85-b85-902183.html

Core + System-Agent:
- 22nm aber neue Mikroarchitektur
- Multi-Chip-Packages (MCP) vereint Chipsatz und Prozessor auf einem Träger, sowie On Package Interface (OPI), das als eine angepasste Version des DMI den Chipsatz mit dem Prozessor verbindet
- Bei erreichen des TJmax throttelt Chipset nun auch, auch wenn CPU diesen erreicht
- Neue Stromsparmodi: Für Haswell: C0, C2E, C7 und für Haswell-UT: Zusätzlich C8, C9 und C10
- BCLK („Baseclock“) kann auch auf 24 abesenkt werden, ermöglicht niedrigere Taktraten im Idle und somit die Verbesserung der Effizienz bei Teillast und Idle
- Architektonische Änderungen: ULT Prozessoren besizten kein PCI-Express(-3.0)-Support, kein Overclocking usw.
- Vielleicht bei den Modellen für Enthusiasten BLCK Straps
- Speicherunterstützung mit bis zu DDR3-1600




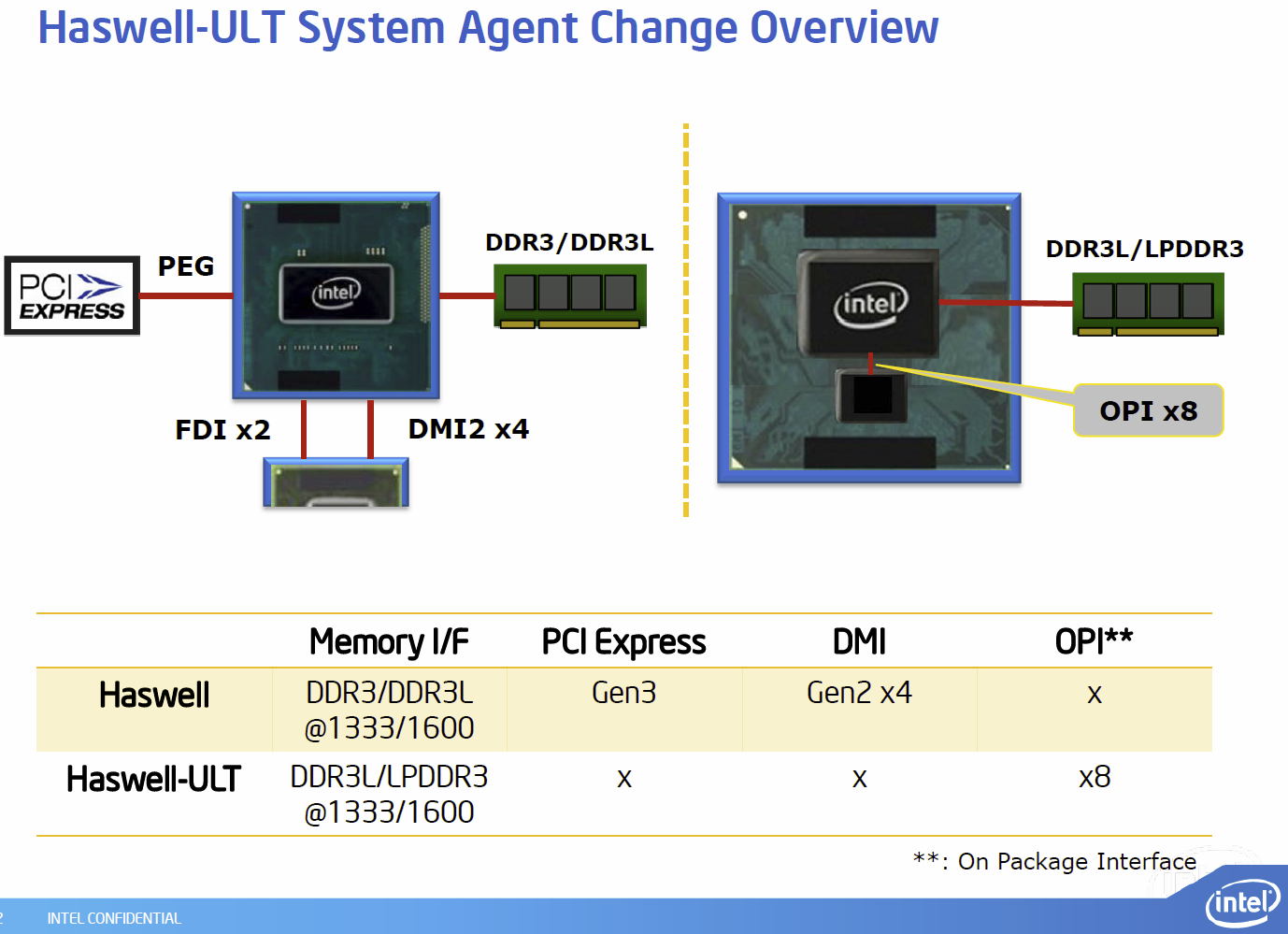
iGPU (HD 4600):
- Unterstützung von DirectX 11.1, OpenCL 1.2 sowie OpenGL 4.0
- Vermutliche Unterstützung der 4K-Auflösung (4.096 Pixel in der Breite)
- Die iGPUs werden intern wie bisher auch als GT1 (6-10 EUs) und GT2 (26-30 EUs) benannt, hinzu kommt bei Haswell als neue Lösung erstmals GT3 (40 EUs)
- Die neue iGPU aller (!) Haswell Desktop Prozessoren wird vermutlich die HD 4600 sein – die bisher als GT2 gehandelte Einheit mit 20 EUs
- Statt bisher 16 Execution Units nun also 20 oder sogar 40, wobei die GT3-Lösung mit 40 EUs nach bisherigen Erkenntnissen nur im mobilen Segment genutzt werden soll
- Erweiterte Codec-Unterstützung für De- und Enkodierung von Videos, sowie eine eigenständige Video Quality Engine (VQE)
- Weitergeführte Leistungssteigerungen sowie Energiesparmaßnahmen
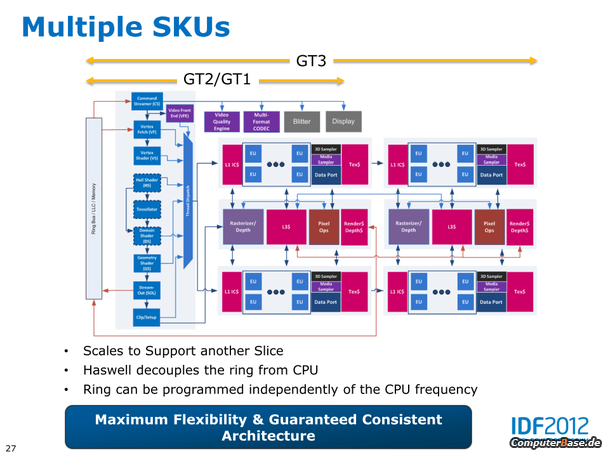


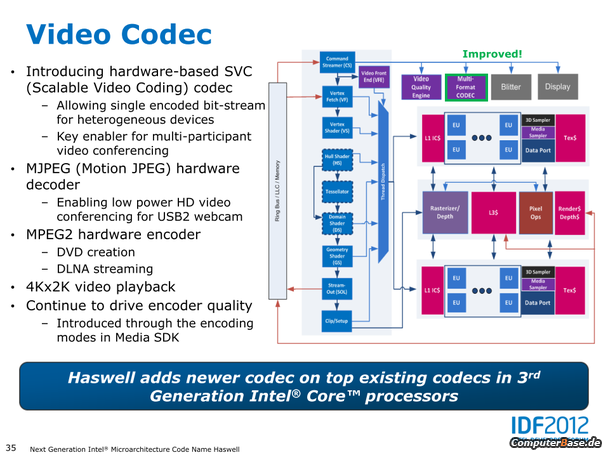
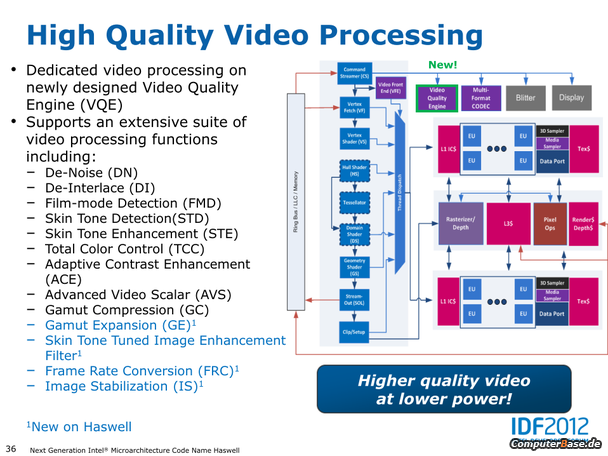


Haswell Prozessoren für den Desktop:
Haswell offizielle Testberichte
Code:
[url]http://ht4u.net/reviews/2013/intel_core_i7_4770_4670_haswell_cpus_test/[/url]
[url]http://www.pcgameshardware.de/Haswell-Codename-255592/Tests/Haswell-Test-Core-i7-4770K-Core-i5-4670K-Core-i5-4570-1071762/[/url]
[url]http://www.computerbase.de/artikel/prozessoren/2013/intel-haswell-prozessor-fuer-desktop-pcs-im-test/[/url]
[url]http://www.computerbase.de/artikel/prozessoren/2013/intel-haswell-prozessoren-fuer-notebooks-im-test/[/url]
[url]http://www.computerbase.de/artikel/grafikkarten/2013/intel-haswell-grafik-fuer-desktop-pcs-im-test/[/url]
[url]http://www.hartware.de/review_1612.html[/url]
[url]http://www.ocaholic.ch/modules/smartsection/item.php?itemid=1005&lang=german[/url]
[url]http://www.technic3d.com/review/cpu-s/1543-intel-core-i7-4770k/1.htm[/url]
[url]http://www.tomshardware.de/core-i7-4770k-haswell-review,testberichte-241295.html[/url]
[url]http://www.anandtech.com/show/7003/the-haswell-review-intel-core-i74770k-i54560k-tested[/url]
[url]http://www.anandtech.com/show/6993/intel-iris-pro-5200-graphics-review-core-i74950hq-tested[/url]
[url]http://www.hardwarecanucks.com/forum/hardware-canucks-reviews/61451-intel-haswell-i7-4770k-i5-4670k-review.html[/url]
[url]http://www.hardocp.com/article/2013/06/01/intel_haswell_i74770k_ipc_overclocking_review#.Uau7apxjEas[/url]
[url]http://www.techpowerup.com/reviews/Intel/Core_i7-4770K_Haswell/[/url]
[url]http://www.techspot.com/review/679-intel-haswell-core-i7-4770k/[/url]
[url]http://www.xbitlabs.com/articles/cpu/display/core-i7-4770k.html[/url]
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Gerüchte:
http://semiaccurate.com/forums/showthread.php?t=4218&page=5Franklin Zhou, a retired chip architect and now a fellow systems integrator for our Taipei farms mentioned an interesting theory on the upcoming Haswell microarchtecture. The giveaway was Intel's statement that the microarchitecture uses an "entirely new cache scheme" which would indicate that the decoders will be at the far front of the data pipe and that the L0 cache will be one huge cache (most likely in the megabytes), completely removing the need for any code cache. The L0 cache will store predecoded and fused instructions of fixed length. The TLB will be entirely different since the fixed length instructions does not have a 1:1 equivalent addressing to physical memory.
What does it all mean? Well for one, the x86 decoder latency is vastly reduced since medium and even large loops can run inside the L0 cache. It also means that if the L0 cache is designed well enough, that is, if the hit ratio is well above 99%, then the arch need only a few decoders (maybe just 4) to satisfy the needs of an equivalent of two or more cores without any performance hit, saving chip real estate (expect the decoders to have long pipes).
The L0 cache could be multi-banked and multi-ported (for each bank) so that several simultaneous accesses are possible. This means that there will be several schedulers feeding several short decoders and execution units. There could also be several small caches (2K perhaps) feeding off the L0, one for each "core", that way, the schedulers won't starve the L0 cache read bandwidth. There will be no clear distinction as to how many units will make a single "core", instead there will be banks of EUs that together will be able to simultaneously process up to eight threads by default. Notice I said "up to", that's because the scheme allows for "dynamic threading" where the system can process a smaller number of threads to increase the IPC per thread.
Funny thing is that this theoretical arch sounds so similar to CMT but taken a level higher. I would like to think of it as a "fat CMT"...
Na dann freuen wir uns alle auf neue lange Diskussionen was ein echter Core ist, und wer mehr Cores hat
 )
)LoRDxRaVeN
Grand Admiral Special
- Mitglied seit
- 20.01.2009
- Beiträge
- 4.169
- Renomée
- 64
- Standort
- Oberösterreich - Studium in Wien
- Mein Laptop
- Lenovo Thinkpad Edge 11
- Details zu meinem Desktop
- Prozessor
- Phenom II X4 955 C3
- Mainboard
- Gigabyte GA-MA790X-DS4
- Kühlung
- Xigmatek Thor's Hammer + Enermax Twister Lüfter
- Speicher
- 4 x 1GB DDR2-800 Samsung
- Grafikprozessor
- Sapphire HD4870 512MB mit Referenzkühler
- Display
- 22'' Samung SyncMaster 2233BW 1680x1050
- HDD
- Hitachi Deskstar 250GB, Western Digital Caviar Green EADS 1TB
- Optisches Laufwerk
- Plextor PX-130A, Plextor Px-716SA
- Soundkarte
- onboard
- Gehäuse
- Aspire
- Netzteil
- Enermax PRO82+ II 425W ATX 2.3
- Betriebssystem
- Windows 7 Professional Studentenversion
- Webbrowser
- Firefox siebenunddreißigsttausend
- Schau Dir das System auf sysprofile.de an
Hört sich zum Teil nach dem sagenumwogenen Reverse-Hyperthreading an - wenn die Sache dynamisch von Statten geht ")
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Naja, im Grunde ist die FPU in Bulldozer ja schon sowas wie "Reverse-Hyperthreading".
Die L0 Geschichte klingt aber recht seltsam. Ziemlich viel Aufwand für einen Codecache, der eine weitere Stufe fürs Decoding bedeutet (Predecoding) und hohe Latenzen aufgrund der Grösse besitzt? Das würde sich ja maximal lohnen, wenn man ständig den gleichen Code verarbeitet (Multithreading: yep, Multitasking: nope) oder grosse Schleifen hat, die nicht in bisherige uOp-Caches passen. Und auch nur dann, wenn man die Fetch- und Decoder-Latenzen verringern kann. Klingt für mich irgendwie nach Murks. Ein uOp-Cache ist vergleichsweise simpel und fängt das wichtigste schon recht gut ab, Schleifen, die viel Performance fressen.
Das hört sich in der Tat sehr nach CMT an, nur halt nicht wie in Bulldozer mit 2 Threads, sondern mit 8 Threads. Auch wenn "banks of" nicht direkt danach klingt, interessant wäre mal ein Design, wo wirklich alle EUs eines "Kerns" einem Thread zur Verfügung gestellt werden können. Halt so wie die FPU in Bulldozer, nur zusätzlich auch die Integer Einheiten. Klingt auf jeden Fall spannend.There will be no clear distinction as to how many units will make a single "core", instead there will be banks of EUs that together will be able to simultaneously process up to eight threads by default.
Sollten die (short) Decoder nicht die Scheduler füttern und nicht umgekehrt?This means that there will be several schedulers feeding several short decoders and execution units.
Die L0 Geschichte klingt aber recht seltsam. Ziemlich viel Aufwand für einen Codecache, der eine weitere Stufe fürs Decoding bedeutet (Predecoding) und hohe Latenzen aufgrund der Grösse besitzt? Das würde sich ja maximal lohnen, wenn man ständig den gleichen Code verarbeitet (Multithreading: yep, Multitasking: nope) oder grosse Schleifen hat, die nicht in bisherige uOp-Caches passen. Und auch nur dann, wenn man die Fetch- und Decoder-Latenzen verringern kann. Klingt für mich irgendwie nach Murks. Ein uOp-Cache ist vergleichsweise simpel und fängt das wichtigste schon recht gut ab, Schleifen, die viel Performance fressen.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
?? Nö, das ist SMT pur, 2 Threads laufen auf einem Unit.Naja, im Grunde ist die FPU in Bulldozer ja schon sowas wie "Reverse-Hyperthreading".
Solange man keinen 256b AVX Befehl explizit angibt, wandelt da keine Logik 2x128b automatisch in 256b um. Wäre sowieso ne blöde Idee, da langsamer.
Ge0rgy
Grand Admiral Special
- Mitglied seit
- 14.07.2006
- Beiträge
- 4.322
- Renomée
- 82
- Mein Laptop
- Lenovo Thinkpad X60s
- Details zu meinem Desktop
- Prozessor
- Phenom II 955 BE
- Mainboard
- DFI LanParty DK 790FXB-M3H5
- Kühlung
- Noctua NH-U12P
- Speicher
- 4GB OCZ Platinum DDR1600 7-7-7 @ 1333 6-6-6
- Grafikprozessor
- Radeon 4850 1GB
- HDD
- Western Digital Caviar Black 1TB
- Netzteil
- Enermax Modu 525W
- Betriebssystem
- Linux, Vista x64
- Webbrowser
- Firefox 3.5
Klingt dennoch lustig...
Hatte der P4 nicht was ähnliches?
Also eine art Trace-Cache der vordekodierte Befehle speicherte?
Hatte der P4 nicht was ähnliches?
Also eine art Trace-Cache der vordekodierte Befehle speicherte?
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Nö, das sind Units (2x FMAC + 2x Packed Integer), die für 2 Threads dimensioniert wurden, bei Bedarf aber einem Thread zur Verfügung gestellt werden können. Halt das Prinzip von "Reverse-Hyperthreading" oder "Anti-Hyperthreading".?? Nö, das ist SMT pur, 2 Threads laufen auf einem Unit.
Wieso sollte man auch?Solange man keinen 256b AVX Befehl explizit angibt, wandelt da keine Logik 2x128b automatisch in 256b um.
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Nö, das ist SMT pur. Wenn Auf nem Intel nur 1 Thread läuf hat er doch auch alles zur Verfügung. 3x INT, 3xFPU und und und. Simples, normales SMT.Nö, das sind Units (2x FMAC + 2x Packed Integer), die für 2 Threads dimensioniert wurden, bei Bedarf aber einem Thread zur Verfügung gestellt werden können. Halt das Prinzip von "Reverse-Hyperthreading" oder "Anti-Hyperthreading".
ReveresHTh war damals ne Technik µOps an nen anderen Kern auszulagern. Was nun ein Kern ist, ist beim Bulldozer bekanntlich die große Frage. Wenns nun 2 eigene, getrennte FPUs gäbe, dann würde ich Deine Sichtweise teilen. Die gibts aber nicht, es gibt nur eine FPU mit einem einzigen Scheduler, von daher seh ich das als SMT an. Ob da nun 2 FMACs hinter dem Scheduler kommen, oder nur eine, oder 4, ist wurst, es ist eine FPU Unit. AMD siehts ja auch genauso, das rote ist SMT:

gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Nö, wie ich schon sagte, das ist vom Prinzip her "Reverse-Hyperthreading", wenn die Dimensionierung für mehr als einen Thread ausgelegt ist, aber dennoch alle EUs einem Thread zur Verfügung gestellt werden können. Und genau so wurde ja das Cluster-Design in Bulldozer konzipiert, speziell eben die Flex FPU. Wie Intel seine Architekturen geplant hat, kann ich dir nicht sagen. Fakt ist aber, sie hatten mit der Core Architektur die aktuellen EUs ja schon vor Hyperthreading. Und da lief lediglich ein Thread pro Kern. Was du als Kern bezeichnet, ist letztendlich aber völlig belanglos. Das hängt einfach vom Design ab. Ebenso die Scheduler. Ob die getrennt sind wie bei den Stars Int Pipes oder ein Unified Scheduler wie bei einem Bulldozer Int Cluster, ist einfach nur ein Detail der Implementierung. SMT hat jedenfalls eine andere Aufgabe, nämlich mit zusätzlichen Threads die vorhandenen EUs besser auszulasten. Und davon findet man definitiv nichts in Bulldozer.Nö, das ist SMT pur. Wenn Auf nem Intel nur 1 Thread läuf hat er doch auch alles zur Verfügung. 3x INT, 3xFPU und und und. Simples, normales SMT.
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Für mich ist das eindeutig die FPU. Erst mit 2 Threads wird die richtig ausgelastet.SMT hat jedenfalls eine andere Aufgabe, nämlich mit zusätzlichen Threads die vorhandenen EUs besser auszulasten. Und davon findet man definitiv nichts in Bulldozer.
Aber nun gut, haben wir halt wieder andere Ansichten. Ich hab Dir ne AMD Folie gezeigt, auf der gross und deutlich SMT steht, Du aber schön ignorierst, was soll man da noch weiter sagen.

Bleib gerne bei Deiner Meinung, ich bleib bei der von AMD
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Dann widersprichst du aber den Ingenieuren. Und die werden es wohl besser wissen. Ich kann mich noch dunkel an deren Worte erinnern (Chuck Moore Analyst Day 2009?), als man sagte, dass die FPU für 2 Threads dimensioniert wäre und die Ressourcen für einen Thread eigentlich überdimensioniert wären. Das passt jedenfalls nicht zum Prinzip von SMT.Für mich ist das eindeutig die FPU. Erst mit 2 Threads wird die richtig ausgelastet.
Was soll ich denn mit so einer dahingeworfenen Folie anfangen? Ich sehe jedenfalls keinen Bezug. Und was erwartest du denn? Dass AMD auf die Folie "Reverse-Hyperthreading" schreibt?Aber nun gut, haben wir halt wieder andere Ansichten. Ich hab Dir ne AMD Folie gezeigt, auf der gross und deutlich SMT steht, Du aber schön ignorierst, was soll man da noch weiter sagen.
![:]](https://www.planet3dnow.de/vbulletin/images/smilies/rolleyes.gif "Augen rollen (sarkastisch) :]") Wenn es nach dir ginge, hätten alle bisherigen AMD Prozessoren SMT oder wie? Schliesslich haben die auch alle einen L2. So wie ich das sehe, geht's da lediglich darum, wie die Threadverarbeitung in den einzelnen Stufen ausschaut und wie das mit gängigen Multithreading Konzepten vergleichbar ist. Und natürlich werden von mehreren Threads gemeinsam genutzte Ressourcen auch bei einer SMT Implementierung verwendet. Das heisst doch aber nicht, dass Bulldozer das SMT Konzept verfolgt. Du betrachtest das Thema einfach vom falschen Standpunkt aus. Ein Thread oder mehrere Threads, die Zugriff auf die gleichen Ressourcen haben, schliesst sich doch nicht aus. Wir betrachteten aber lediglich einen Thread. Und so wie die Flex FPU dann arbeitet, entspricht das eben dem Prinzip von "Reverse-Hyperthreading", weil die Ressourcen für mehr als einen Thread ausgelegt sind.
Wenn es nach dir ginge, hätten alle bisherigen AMD Prozessoren SMT oder wie? Schliesslich haben die auch alle einen L2. So wie ich das sehe, geht's da lediglich darum, wie die Threadverarbeitung in den einzelnen Stufen ausschaut und wie das mit gängigen Multithreading Konzepten vergleichbar ist. Und natürlich werden von mehreren Threads gemeinsam genutzte Ressourcen auch bei einer SMT Implementierung verwendet. Das heisst doch aber nicht, dass Bulldozer das SMT Konzept verfolgt. Du betrachtest das Thema einfach vom falschen Standpunkt aus. Ein Thread oder mehrere Threads, die Zugriff auf die gleichen Ressourcen haben, schliesst sich doch nicht aus. Wir betrachteten aber lediglich einen Thread. Und so wie die Flex FPU dann arbeitet, entspricht das eben dem Prinzip von "Reverse-Hyperthreading", weil die Ressourcen für mehr als einen Thread ausgelegt sind.Dresdenboy
Redaktion
☆☆☆☆☆☆
Was ist denn das Prinzip? Es geht doch eher um geeignete Kompromisse.Dann widersprichst du aber den Ingenieuren. Und die werden es wohl besser wissen. Ich kann mich noch dunkel an deren Worte erinnern (Chuck Moore Analyst Day 2009?), als man sagte, dass die FPU für 2 Threads dimensioniert wäre und die Ressourcen für einen Thread eigentlich überdimensioniert wären. Das passt jedenfalls nicht zum Prinzip von SMT.
Mal unabhängig davon ist die FPU mit mehreren Zyklen Latenz bei allen Befehlen eine gute Kandidatin dafür, per SMT die Befehle eines zweiten Threads hineinzumischen.
gruffi
Grand Admiral Special
- Mitglied seit
- 08.03.2008
- Beiträge
- 5.393
- Renomée
- 65
- Standort
- vorhanden
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 1600
- Mainboard
- MSI B350M PRO-VDH
- Kühlung
- Wraith Spire
- Speicher
- 2x 8 GB DDR4-2400 CL16
- Grafikprozessor
- XFX Radeon R7 260X
- Display
- LG W2361
- SSD
- Crucial CT250BX100SSD1
- HDD
- Toshiba DT01ACA200
- Optisches Laufwerk
- LG Blu-Ray-Brenner BH16NS40
- Soundkarte
- Realtek HD Audio
- Gehäuse
- Sharkoon MA-I1000
- Netzteil
- be quiet! Pure Power 9 350W
- Betriebssystem
- Windows 10 Professional 64-bit
- Webbrowser
- Mozilla Firefox
- Verschiedenes
- https://valid.x86.fr/mb4f0j
Ich denke, du wirfst hier zwei Sachen durcheinander. SMT mag bei Cache helfen, Latenzen zu verstecken, nicht aber bei Befehlslatenzen. Befehlslatenzen definieren sich ja hauptsächlich dadurch, wie lange eine Instruktion braucht, bis sie von den EUs verarbeitet wurde. Genau dann bringt dir SMT rein gar nichts, egal wie gross die Latenz ist. SMT bringt erst dann etwas, wenn EUs frei sind. Oder anders formuliert, je niedriger die Befehlslatenzen, umso besser für SMT, weil die EUs dann schneller wieder frei sind und von anderen Threads genutzt werden können. Hohe Befehlslatenzen sind eher kontraproduktiv für SMT.Mal unabhängig davon ist die FPU mit mehreren Zyklen Latenz bei allen Befehlen eine gute Kandidatin dafür, per SMT die Befehle eines zweiten Threads hineinzumischen.
Duplex
Admiral Special
Duplex
Admiral Special
Laut Wiki hat Haswell "1MB L2 cache per core and up to a 32MB L3 cache for the Extreme Edition and Xeon."
400% mehr L2 Cache & 60% mehr L3 Cache als Sandy Bridge-E
Der L2 Cache wird im vergleich zum "Core2" Cache Design aber richtig aufgepumpt, bisher hat Intel seit Core2 bis Sandy Bridge immer die gleiche L2 Größe gehabt, das war immer sehr schnell.
Der einzige Nachteil könnte die Latenzen betreffen, aber Faktor4 Steigerung ist schon heftig") da muss sich Intel etwas gutes ausgedacht haben
da muss sich Intel etwas gutes ausgedacht haben
http://en.wikipedia.org/wiki/Haswell_(microarchitecture)
400% mehr L2 Cache & 60% mehr L3 Cache als Sandy Bridge-E
Der L2 Cache wird im vergleich zum "Core2" Cache Design aber richtig aufgepumpt, bisher hat Intel seit Core2 bis Sandy Bridge immer die gleiche L2 Größe gehabt, das war immer sehr schnell.
Der einzige Nachteil könnte die Latenzen betreffen, aber Faktor4 Steigerung ist schon heftig
da muss sich Intel etwas gutes ausgedacht haben http://en.wikipedia.org/wiki/Haswell_(microarchitecture)
Zuletzt bearbeitet:
Opteron
Redaktion
☆☆☆☆☆☆
- Mitglied seit
- 13.08.2002
- Beiträge
- 23.645
- Renomée
- 2.254
Schau mal in der Änder-Historie des Bulldozer-Wikieintrags nach, wieviel Cache der Chip schon Mal hatte. Wiki als Quelle bei solchen hochspekulativen Sachen, wie unfertige Chips im Planungsstadium ist Blödsinn hoch 3.
Da ist das Gerüchte mit dem Transactional Memory 10x glaubhafter.
Da ist das Gerüchte mit dem Transactional Memory 10x glaubhafter.
Lepus
Fleet Captain Special
- Mitglied seit
- 14.08.2009
- Beiträge
- 289
- Renomée
- 1
- Standort
- München
- Mein Laptop
- Alienware M17x R4
- Details zu meinem Laptop
- Prozessor
- Intel Core i7-3820M Single Thread @ max 4,1GHz
- Speicher
- 2x4GB Mushkin 1600MHz (ULV)
- Grafikprozessor
- Dell AMD HD 7970M
- Display
- 17,3" FHD
- HDD
- Crucial m4 256Gb mSata
- Optisches Laufwerk
- HL-DT-ST DVDRW/BR-ROM
- Soundkarte
- Creative Sound Blaster Recon 3Di / HM77
- Gehäuse
- Alienware M17x R4
- Netzteil
- Dell 240W
- Betriebssystem
- Windows 8
- Webbrowser
- Opera
Duplex
Admiral Special
Die L2 Größe mit 1MB pro Core glaube ich auch nicht wirklich, bisher hat man immer auf schnellen 256KB L2 gesetzt, warum sollte man den durch einen neuen ersetzen?Wiki als Quelle bei solchen hochspekulativen Sachen, wie unfertige Chips im Planungsstadium ist Blödsinn hoch 3.
Da ist das Gerüchte mit dem Transactional Memory 10x glaubhafter.
FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
"New Cache Design" heißt so viel wie "Überraschung"Die L2 Größe mit 1MB pro Core glaube ich auch nicht wirklich, bisher hat man immer auf schnellen 256KB L2 gesetzt, warum sollte man den durch einen neuen ersetzen?
EDIT:
Ich tippe übrigens auf so etwas wie "Bulldozer done right", jedoch etwas bodenständiger, siehe Nehalem.
Zuletzt bearbeitet:
Dresdenboy
Redaktion
☆☆☆☆☆☆
Transactional Memory wird auf beiden Seiten schon fleißig patentiert.
Das neue Cache-Design (für Gather-Operationen) wird vielleicht auf viele parallele, aber nicht so breite Bankzugriffe optimiert. Damit aber auch ausreichend Daten dafür da sind, sollten die schnelleren Caches größer sein, damit beim Gathering nicht ein paar Zugriffe quer ins langsame DRAM feuern.
.
EDIT :
.
Aber ein "Bulldozer done right" erfordert ersteinmal einen "Bulldozer done wrong" Der jetzige BD1 ist aber nicht "falsch", sondern hat eher nur zu wenig von dem, was AMD schon angedacht hat. Hier kann man die Probleme im Management, in knappen Ressourcen, in Sackgassen usw. suchen.
Das neue Cache-Design (für Gather-Operationen) wird vielleicht auf viele parallele, aber nicht so breite Bankzugriffe optimiert. Damit aber auch ausreichend Daten dafür da sind, sollten die schnelleren Caches größer sein, damit beim Gathering nicht ein paar Zugriffe quer ins langsame DRAM feuern.
.
EDIT :
.
So etwas wie Cluster kann ich mir auch vorstellen. Intel's Gonzalez arbeitet auch an flexiblen Ressourcenzuordnungen (z.B. 2 Cluster für einen Thread).Ich tippe übrigens auf so etwas wie "Bulldozer done right", jedoch etwas bodenständiger, siehe Nehalem.
Aber ein "Bulldozer done right" erfordert ersteinmal einen "Bulldozer done wrong"
Der jetzige BD1 ist aber nicht "falsch", sondern hat eher nur zu wenig von dem, was AMD schon angedacht hat. Hier kann man die Probleme im Management, in knappen Ressourcen, in Sackgassen usw. suchen.FredD
Gesperrt
- Mitglied seit
- 25.01.2011
- Beiträge
- 2.472
- Renomée
- 43
"Bulldozer done better" wäre wohl die logisch bessere Formulierung.Aber ein "Bulldozer done right" erfordert ersteinmal einen "Bulldozer done wrong"
Laut den Folien bleibt Haswell jedoch weiterhin bei 'Intel Hyperthreading', was aber nicht heißt, dass CMT nicht doch irgendwann den Weg auf Intel-Silizium findet.
Dresdenboy
Redaktion
☆☆☆☆☆☆
Das gute an so einem Marketingnamen ist, dass Intel schmerzfrei ein anderes Konzept dahinterlegen kann. Und wenn man sich eine dynamische Clusterzuteilung (nicht befehlsweise, aber z. B. für einen kleinen Befehlsstrang) vorstellt, kann man grob auch SMT darin erkennen, nur gälte "simultaneous" dann für die Befehlsstränge.Laut den Folien bleibt Haswell jedoch weiterhin bei 'Intel Hyperthreading', was aber nicht heißt, dass CMT nicht doch irgendwann den Weg auf Intel-Silizium findet.
Duplex
Admiral Special
Neues GPU Design & 25% mehr EUs als Ivy Bridge
http://vr-zone.com/articles/haswell...-small-step-forward-/14399.html#ixzz1iUkKTN8O
Das wichtigste bleibt leider noch unbekannt (IPC Verbesserungen gegenüber Sandy Bridge)
http://vr-zone.com/articles/haswell...-small-step-forward-/14399.html#ixzz1iUkKTN8O
Das wichtigste bleibt leider noch unbekannt (IPC Verbesserungen gegenüber Sandy Bridge)
memory_stick
Lieutnant
soweit es denn verbesserungen werden...
Soweit es nach den Gerüchten aussieht, soll Intel doch auf eine Art CMT-Design umsteigen, oder bin ich falsch informiert?
Dies beduetet für mich, dass man (analog zu AMD mit BD) auch bei Intel nicht zwingend von einer "IPC" (welche IPC?) Verbesserung ausgehen kann... Eine Stagnation zu SB ist genauso zu erwarten.
mfg memory_stick
Soweit es nach den Gerüchten aussieht, soll Intel doch auf eine Art CMT-Design umsteigen, oder bin ich falsch informiert?
Dies beduetet für mich, dass man (analog zu AMD mit BD) auch bei Intel nicht zwingend von einer "IPC" (welche IPC?) Verbesserung ausgehen kann... Eine Stagnation zu SB ist genauso zu erwarten.
mfg memory_stick
Ähnliche Themen
- Antworten
- 121
- Aufrufe
- 10K
- Antworten
- 32
- Aufrufe
- 3K
- Antworten
- 102
- Aufrufe
- 11K
- Antworten
- 743
- Aufrufe
- 52K