App installieren
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Anmerkung: This feature may not be available in some browsers.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
AMD EPYC Rome Server CPUs - Zen 2 in 7nm TSMC
- Ersteller Complicated
- Erstellt am
MagicEye04
Grand Admiral Special
- Mitglied seit
- 20.03.2006
- Beiträge
- 23.270
- Renomée
- 1.853
- Standort
- oops,wrong.planet..
- Aktuelle Projekte
- Seti,WCG,Einstein + was gerade Hilfe braucht
- Lieblingsprojekt
- Seti
- Meine Systeme
- R7-1700+GTX1070ti,R7-1700+RadeonVII, FX-8350+GTX1050ti, X4-5350+GT1030, X2-240e+RX460
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Dell Latitude E7240
- Details zu meinem Desktop
- Prozessor
- R9-3950X (@65W)
- Mainboard
- Asus Prime B550plus
- Kühlung
- TR Macho
- Speicher
- 2x16GiB Corsair LPX2666C16
- Grafikprozessor
- Radeon VII
- Display
- LG 32UD99-W 81,3cm
- SSD
- Crucial MX500-250GB, Samsung EVO280 256GB
- HDD
- Seagate 7200.14 2TB (per eSATAp)
- Optisches Laufwerk
- LG DVDRAM GH24NS90
- Soundkarte
- onboard
- Gehäuse
- Nanoxia Deep Silence1
- Netzteil
- BeQuiet StraightPower 11 550W
- Tastatur
- Cherry RS6000
- Maus
- Logitech RX600
- Betriebssystem
- Ubuntu
- Webbrowser
- Feuerfuchs
- Verschiedenes
- 4x Nanoxia Lüfter (120/140mm) , Festplatte in Bitumenbox
Eigentlich ist doch so ziemlich jeder Chip so aufgebaut, dass die feinen Strukturen nur bei den Signal-Transistoren auf der untersten Ebene zu finden sind.
Je höher man dann in der Verdrahtung kommt, desto fetter werden die Strukturen. Das Schalten der eigentlichen Signalpegel kann ja dann wie schon erwähnt, auch weiterhin mit auf Leistung getrimmten größeren Tansistoren erfolgen oder im Zweifel lagert man halt nur den PHY aus. Da ist es doch heute je nach Bedarf auch üblich, dass der mal drin ist oder auch extern.
Je höher man dann in der Verdrahtung kommt, desto fetter werden die Strukturen. Das Schalten der eigentlichen Signalpegel kann ja dann wie schon erwähnt, auch weiterhin mit auf Leistung getrimmten größeren Tansistoren erfolgen oder im Zweifel lagert man halt nur den PHY aus. Da ist es doch heute je nach Bedarf auch üblich, dass der mal drin ist oder auch extern.
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
@MagicEye04
Ich finde deinen Kommentar etwas Missverständlich.
ALLE Transistoren befinden sich auf der untersten Ebene. Darüber befinden sich die Verbindungslayer.
Da alle Transistoren prozessbedingt die gleiche Höhe haben müssen, gibt es keine "Dicken" Transistoren.
Durch varieren der Flächen eines Transistors läßt dieser sich in gewissen Grenzen auf Verbrauch, Geschwindigkeit oder Leistung optimieren.
Da auf der Trägerplatine (Mainboard) die zu überwindenden Leitungskapazitäten wesentlich höher sind als innerhalb eines ICs, werden dazu mehrere Transistoren parallel geschaltet.
Das sieht man ja auch am HBM Speicher durch Anbindung über einen Interposer. Durch den Interposer sind schmalere Leitungen mit geringerer Leitungskapazität möglich als über eine herkömmliche Trägerplatine. Dadurch kann das Speicherinterface auf dem IC für geringere Ströme designed werden ( weniger Transistoren parallel ) und fällt daher vom Flächenbedarf trotz 1024Bit Breite kleiner aus als ein DDR4 Interface.
Soweit mein Kenntnisstand. Kann natürlich sein, dass ich nicht mehr Up to Date bin.
--- Update ---
Ich halte das ganze für Machbar und sehe darin im Moment halt nur Vorteile. Naja, werdens ja in ein paar Monaten sehen.
Ich finde deinen Kommentar etwas Missverständlich.
ALLE Transistoren befinden sich auf der untersten Ebene. Darüber befinden sich die Verbindungslayer.
Da alle Transistoren prozessbedingt die gleiche Höhe haben müssen, gibt es keine "Dicken" Transistoren.
Durch varieren der Flächen eines Transistors läßt dieser sich in gewissen Grenzen auf Verbrauch, Geschwindigkeit oder Leistung optimieren.
Da auf der Trägerplatine (Mainboard) die zu überwindenden Leitungskapazitäten wesentlich höher sind als innerhalb eines ICs, werden dazu mehrere Transistoren parallel geschaltet.
Das sieht man ja auch am HBM Speicher durch Anbindung über einen Interposer. Durch den Interposer sind schmalere Leitungen mit geringerer Leitungskapazität möglich als über eine herkömmliche Trägerplatine. Dadurch kann das Speicherinterface auf dem IC für geringere Ströme designed werden ( weniger Transistoren parallel ) und fällt daher vom Flächenbedarf trotz 1024Bit Breite kleiner aus als ein DDR4 Interface.
Soweit mein Kenntnisstand. Kann natürlich sein, dass ich nicht mehr Up to Date bin.
--- Update ---
Man braucht nur noch die Infinity Fabric Anbindung an den I/O Chip. Es bleibt nur noch ein kleiner Teil auf dem Die.Infinity Fabric wird über Multi-PHY-Muxing realisiert, und das braucht man auch weiterhin, also bleibt auch PCIe auf dem eigentlich Die.
Wieviel würde es die Latenz erhöhen? 1T? macht kaum einen Unterschied zu den 16T CL die eh für den ersten Zugriff benötigt werden. Dürfte zudem geringer sein als der Aufwand über einen anderen Chip zu Routen wie bei EPYC. Zudem der Vorteil, dass alle 64 Cores die gleiche Latenz und den gleichen Adressraum sehen. Dazu etwas mehr L3 Cache, schon fällt die kleine Verzögerung nicht ins Gewicht.Und genauso werden die Memory Controller und DDR4-PHYs eher nicht ausgelagert, weil das die Latenz erhöht.
Dafür lohnt es sich wirklich nicht.Bleibt also nur noch der Kleinkram wie USB, Audio, Netzwerk, etc. für den eigenen I/O-Die, aber das lohnt sich kaum dafür einen eigenen Chip zu designen. Ergo: Ich glaube nicht an diese Geschichte.
Ich halte das ganze für Machbar und sehe darin im Moment halt nur Vorteile. Naja, werdens ja in ein paar Monaten sehen.
Natürlich wird AMD einen geeigneten PHY lizensieren. Da gibt es sicher noch weitere Anbieter, die ihre Designs auf TSMC 7nm optimieren. Ist ja auch Papermasters Richtlinie nicht mehr alles selbst per Hand zu machen.Edit: Abgesehen davon gibt es den DesignWare Multi-Protocol 25G PHY bereits in TSMC 7nm, und das wird vermutlich ziemlich genau das sein was bei der nächsten Generation verwendet wird.
Zuletzt bearbeitet:
Stefan Payne
Grand Admiral Special
Klar, ein eigener I/O Die macht für einen Teil sicher Sinn, aber es bleibt dabei das ein Teil des I/O ehh bleiben muss. Infinity Fabric wird über Multi-PHY-Muxing realisiert, und das braucht man auch weiterhin, also bleibt auch PCIe auf dem eigentlich Die. Und genauso werden die Memory Controller und DDR4-PHYs eher nicht ausgelagert, weil das die Latenz erhöht.
Du vergisst hier on Package Signalstärke vs. Off Package oder "Kilometerweit" über das Board.
Im ersten Fall kann man das ganze deutlich verkleinern, da man das Signal nur über ein paar mm treiben muss, nicht über mehrere "Kilometer" über das Board, daher weniger Treiberleistung.
Aktuell ist doch der ganze I/O Kram inkl Memory Controller doch auch via IF intern angebunden, oder?
Da machts dann nicht soo einen großen Unterschied, das ganze komplett auszulagern. Die Latenz würde sich nicht wirklich ändern.
Außerdem hat man sowas in der Art schon mal früher gemacht. Ist also nicht neu!
Das war entweder bei IBM Power Prozessoren oder bei SPARCs, dass du 'nen externen Memory Controller hattest...
Und diese Memory Controller hatten auch noch ihren eigenen SRAM...
Wäre daher u.U. möglich, dass AMD hier einenn L4 Cache mit der nächsten Generation einführt...
Zuletzt bearbeitet:
HalbeHälfte
Vice Admiral Special
- Mitglied seit
- 30.07.2006
- Beiträge
- 674
- Renomée
- 8
@BoMbY
Nein es spricht natürlich nichts dagegen. Trotzdem klebt so ein Teil dann mit dabei unter dem Hs und will mitgekühlt werden. Und grad der hat ja wie ihr sagt mit Stromstärken zu tun") Ich werde damit aber auch klarkommen, wenn sie den I/O z.B. später in GFs 14/12 fertigen lassen oder halt TSMC 12nm.
Ich werde damit aber auch klarkommen, wenn sie den I/O z.B. später in GFs 14/12 fertigen lassen oder halt TSMC 12nm.
Ich sehe keinen Grund dafür sich dem, teils auch viralen, PR-Bullshit zu ergeben und die Strukturdichte für ein Qualitätsmerkmal zu erklären.
@all
Intel hat sich vor einiger Zeit übrigens einer Firma einverleibt die sich mit solchen externen Interconnects beschäftigt. Die sehen das also auch auf sich zukommen.
Das andere Prob ist aber was (letztendlich) der private Anwender davon haben soll. Ich bin mir ziemlich ziemlich sicher, daß 95% der Anwender die überhaupt mehr Leistung bräuchten als bei Apples A10 Fusion, mit Leistung eines leicht aktualisierten 5775C bei 4.5Ghz restlos zufrieden wären
(eDRAM als L4 natürlich") )
)
Ich kann, ohne es kritisieren zu wollen, mit "core bore" auch nicht besonders viel anfangen. Im Gegensatz zu zig CUs der GPUs, fehlen für die CPU entsprechende Programmier- und Compileransätze. Imho.
Foren verzerren den Blick auf die Realität. Quantitativ gesehen interessiert sich keine Sau für einen 8700k & Co. Zen hat sich nun als ansprechend gezeigt, weil eben auch die pro Thread Leistung für viele stimmt.
@Payne
Nein es spricht natürlich nichts dagegen. Trotzdem klebt so ein Teil dann mit dabei unter dem Hs und will mitgekühlt werden. Und grad der hat ja wie ihr sagt mit Stromstärken zu tun
Ich werde damit aber auch klarkommen, wenn sie den I/O z.B. später in GFs 14/12 fertigen lassen oder halt TSMC 12nm. Ich sehe keinen Grund dafür sich dem, teils auch viralen, PR-Bullshit zu ergeben und die Strukturdichte für ein Qualitätsmerkmal zu erklären.
@all
Intel hat sich vor einiger Zeit übrigens einer Firma einverleibt die sich mit solchen externen Interconnects beschäftigt. Die sehen das also auch auf sich zukommen.
Das andere Prob ist aber was (letztendlich) der private Anwender davon haben soll. Ich bin mir ziemlich ziemlich sicher, daß 95% der Anwender die überhaupt mehr Leistung bräuchten als bei Apples A10 Fusion, mit Leistung eines leicht aktualisierten 5775C bei 4.5Ghz restlos zufrieden wären
(eDRAM als L4 natürlich
)Ich kann, ohne es kritisieren zu wollen, mit "core bore" auch nicht besonders viel anfangen. Im Gegensatz zu zig CUs der GPUs, fehlen für die CPU entsprechende Programmier- und Compileransätze. Imho.
Foren verzerren den Blick auf die Realität. Quantitativ gesehen interessiert sich keine Sau für einen 8700k & Co. Zen hat sich nun als ansprechend gezeigt, weil eben auch die pro Thread Leistung für viele stimmt.
@Payne
Früher hat man das imho aus der Not heraus getan. Jetzt ist sie wohl wieder daAußerdem hat man sowas in der Art schon mal früher gemacht. Ist also nicht neu!
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Man braucht nur noch die Infinity Fabric Anbindung an den I/O Chip. Es bleibt nur noch ein kleiner Teil auf dem Die.
Wenn man etwas komplett neues dafür implementiert vielleicht, aber das wird man eher nicht machen.
Natürlich wird AMD einen geeigneten PHY lizensieren. Da gibt es sicher noch weitere Anbieter, die ihre Designs auf TSMC 7nm optimieren. Ist ja auch Papermasters Richtlinie nicht mehr alles selbst per Hand zu machen.
1. https://www.amd.com/en/press-releases/amd-and-synopsys-2014sep18
2. https://www.synopsys.com/dw/doc.php/ss/amd_ss.pdf
3. Aus dem Processor Programming Reference (PPR) for AMD Family 17h Models 00h-0Fh Processors:

Entsprechendes Produkt bei Synopsys: DesignWare Enterprise 12G PHY
--- Update ---
Also wenn überhaupt würde das so für mich Sinn ergeben, mit Bridge Chiplet welches Logik inkludiert:

Vorteil: Sehr kurze Wege, und das Bridge Chiplet hat oben und unten Kontakte.
Ebenso glaube ich kaum das AMD entgegen der bisherigen Gerüchte jetzt auf einen 8-core Die gewechselt hat.
HalbeHälfte
Vice Admiral Special
- Mitglied seit
- 30.07.2006
- Beiträge
- 674
- Renomée
- 8
Ergibt wohl sehr pfiffige HeatspreaderVorteil: Sehr kurze Wege, und das Bridge Chiplet hat oben und unten Kontakte.

amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Ich versteh nicht, was du meinst. Es ist doch eine neue Implementation, ZEN2 Cores und 7nm, dazu neue angepasste PHYs.Wenn man etwas komplett neues dafür implementiert vielleicht, aber das wird man eher nicht machen.
Ich hab mal weggestrichen, was meiner Meinung nach für das 7nm Core Chiplet nicht nötig ist:

Könnte natürlich auch ein 16 Kern Chiplet werden, würde den Yield aber wiederum verschlechtern. Deshalb so klein wie möglich um minimalen Ausschuß zu haben.
Dein Vorschlag nennt sich active Interposer. Wird auch daran gearbeitet.
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Nein, das nennt sich "Bridge Chiplet" wie in dem verlinkten Patent 20180102338, da es eben nur in ein normales Package eingelassen wird, ähnlich wie Intel's EMIB, nur eben mit Kontakten auf beiden Seiten. Edit: Aber ja, die Funktionsweise ist praktisch identisch.
HalbeHälfte
Vice Admiral Special
- Mitglied seit
- 30.07.2006
- Beiträge
- 674
- Renomée
- 8
Das will aber auch nirgendwo jemand hören oder?Das andere Prob ist aber was (letztendlich) der private Anwender davon haben soll. Ich bin mir ziemlich ziemlich sicher, daß 95% der Anwender die überhaupt mehr Leistung bräuchten als bei Apples A10 Fusion, mit Leistung eines leicht aktualisierten 5775C bei 4.5Ghz restlos zufrieden wären
(eDRAM als L4 natürlich
Ich kann, ohne es kritisieren zu wollen, mit "core bore" auch nicht besonders viel anfangen. Im Gegensatz zu zig CUs der GPUs, fehlen für die CPU entsprechende Programmier- und Compileransätze. Imho.
Foren verzerren den Blick auf die Realität. Quantitativ gesehen interessiert sich keine Sau für einen 8700k & Co. Zen hat sich nun als ansprechend gezeigt, weil eben auch die pro Thread Leistung für viele stimmt.
derDruide
Grand Admiral Special
- Mitglied seit
- 09.08.2004
- Beiträge
- 2.724
- Renomée
- 433
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 3900X
- Mainboard
- Asus Strix B450-F Gaming
- Kühlung
- Noctua NH-C14
- Speicher
- 32 GB DDR4-3200 CL14 FlareX
- Grafikprozessor
- Radeon RX 590
- Display
- 31.5" Eizo FlexScan EV3285
- SSD
- Corsair MP510 2 TB, Samsung 970 Evo 512 GB
- HDD
- Seagate Ironwulf 6 TB
- Optisches Laufwerk
- Plextor PX-880SA
- Soundkarte
- Creative SoundblasterX AE-7
- Gehäuse
- Antec P280
- Netzteil
- be quiet! Straight Power E9 400W
- Maus
- Logitech Trackman Marble (Trackball)
- Betriebssystem
- openSUSE 15.2
- Webbrowser
- Firefox
- Internetanbindung
- ▼50 MBit ▲10 MBit
Es stimmt auch nur teilweise, das ist immer eine Frage des Preises. Bis zu einer gewissen Schwelle wäre es dumm, das billigste genommen zu haben und sich damit selbst ein Bein zu stellen, wenn man mehr Leistung braucht. Auch wenn das nur alle 2 Wochen so sein sollte, kann es dann richtig weh tun, und über die Laufzeit von 6-8 Jahren wäre es einfach unklug, zu geizig gewesen zu sein.
Irgendwann kommt natürlich eine Schwelle, wo die Leistung ihren Preis nicht mehr wert ist. Dann springen Seiten wie ComputerBase ein, und erklären ihren Lesern, dass nur das Maximum in Frage kommt und alle unbedingt eine 2080Ti für 5K brauchen.
Irgendwann kommt natürlich eine Schwelle, wo die Leistung ihren Preis nicht mehr wert ist. Dann springen Seiten wie ComputerBase ein, und erklären ihren Lesern, dass nur das Maximum in Frage kommt und alle unbedingt eine 2080Ti für 5K brauchen.
Zuletzt bearbeitet:
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Der Link stammt von MacroWelle aus dem Zen-Thread:
https://www.phoronix.com/scan.php?page=news_item&px=AMD-Platform-QoS-RFC-Patches
https://www.phoronix.com/scan.php?page=news_item&px=AMD-Platform-QoS-RFC-Patches
Welche Größenordnung an Performance-Optimierungen im Betrieb kann man mit diesem Feature erwarten?This afternoon AMD sent out their first Linux kernel patches for what might end up being a new feature for the "EPYC 2" / Zen 2 processors.
Hitting the Linux kernel mailing list a few minutes ago was a set of experimental / request-for-comments patches on "AMD QoS support".This series adds support for AMD64 architectural extensions for Platform Quality of Service. These extensions are intended to provide for the monitoring of the usage of certain system resources by one or more processors and for the separate allocation and enforcement of limits on the use of certain system resources by one or more processors.The initial QoS functionality is for L3 cache allocation enforcement, L3 cache occupancy monitoring, L3 code-data prioritization, and memory bandwidth enforcement/allocation. This AMD QoS sounds like -- and implied as much by the Linux code -- akin to Intel RDT (Resource Director Technology).
The monitoring and enforcement are not necessarily applied across the entire system, but in general apply to a QOS domain which corresponds to some shared system resource.
Zuletzt bearbeitet:
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.371
- Renomée
- 9.696
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken

- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Der Link stammt von MacroWelle aus dem Zen-Thread:
https://www.phoronix.com/scan.php?page=news_item&px=AMD-Platform-QoS-RFC-Patches
Welche Größenordnung an Performance-Optimierungen im Betrieb kann man mit diesem Feature erwarten?
Danke für den Hinweis, ich habe da mal eine News draus gemacht. Bei Intel habe ich was zur Cache Allocation Technology gefunden,
die bei verschiedenen Anwendungen auf einem Server ohne Intels RDT eine um den Faktor 4 höhere Response Time zeigen. Aber wird auch Cherry Picking sein.

amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Und genauso werden die Memory Controller und DDR4-PHYs eher nicht ausgelagert, weil das die Latenz erhöht. ... Ergo: Ich glaube nicht an diese Geschichte.
Hallo, bin beim rumstöbern auf dieses AMD Exascale pdf von 2017 gestoßen:
http://www.computermachines.org/joe/publications/pdfs/hpca2017_exascale_apu.pdf
Seite 3:
The chiplet ap-
proach differs from conventional multi-chip module (MCM) designs
in that each individual chiplet is not a complete
SOC. For example, the CPU chiplet contains CPU cores
and caches, but lacks memory interfaces and external I/O
Das Bild eines Exascale Chips mit active Interposer GPU mit HBM on top ist natürlich noch ein paar Jahre in die Zukunft, aber man sieht schon mal in welche Richtung es geht. Mal gespannt, wann die erste GPU oder APU mit HBM on top kommt.
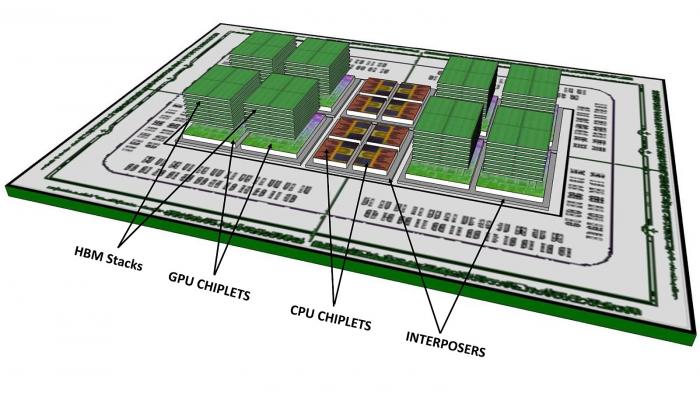
ROME könnte schon mal der erste Versuch sein die Chiplet Idee für CPU umzusetzen, noch ohne active Interposer dafür mit diskretem I/O 14nm Chip.
cyrusNGC_224
Grand Admiral Special
- Mitglied seit
- 01.05.2014
- Beiträge
- 5.924
- Renomée
- 117
- Aktuelle Projekte
- POGS, Asteroids, Milkyway, SETI, Einstein, Enigma, Constellation, Cosmology
- Lieblingsprojekt
- POGS, Asteroids, Milkyway
- Meine Systeme
- X6 PII 1090T, A10-7850K, 6x Athlon 5350, i7-3632QM, C2D 6400, AMD X4 PII 810, 6x Odroid U3
- BOINC-Statistiken

An die Grafik kann ich mich sogar erinnern. Wäre demzufolge wirklich nicht derart überraschend.
Complicated
Grand Admiral Special
- Mitglied seit
- 08.10.2010
- Beiträge
- 4.949
- Renomée
- 441
- Mein Laptop
- Lenovo T15, Lenovo S540
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 3700X
- Mainboard
- MSI X570-A PRO
- Kühlung
- Scythe Kama Angle - passiv
- Speicher
- 32 GB (4x 8 GB) G.Skill TridentZ Neo DDR4-3600 CL16-19-19-39
- Grafikprozessor
- Sapphire Radeon RX 5700 Pulse 8GB PCIe 4.0
- Display
- 27", Lenovo, 2560x1440
- SSD
- 1 TB Gigabyte AORUS M.2 PCIe 4.0 x4 NVMe 1.3
- HDD
- 2 TB WD Caviar Green EADS, NAS QNAP
- Optisches Laufwerk
- Samsung SH-223L
- Gehäuse
- Lian Li PC-B25BF
- Netzteil
- Corsair RM550X ATX Modular (80+Gold) 550 Watt
- Betriebssystem
- Win 10 Pro.
Erstmalig kam dieses Konzept 2007 auf bei AMD. Zuletzt auch 2015 aktualisiert ohne den I/O Part allerdings noch mal zu erwähnen:
https://www.planet3dnow.de/vbulleti...terposer-Strategie-Zen-Fiji-HBM-und-Logic-ICs
https://www.planet3dnow.de/vbulleti...terposer-Strategie-Zen-Fiji-HBM-und-Logic-ICs
amdfanuwe
Grand Admiral Special
- Mitglied seit
- 24.06.2010
- Beiträge
- 2.372
- Renomée
- 34
- Details zu meinem Desktop
- Prozessor
- 4200+
- Mainboard
- M3A-H/HDMI
- Kühlung
- ein ziemlich dicker
- Speicher
- 2GB
- Grafikprozessor
- onboard
- Display
- Samsung 20"
- HDD
- WD 1,5TB
- Netzteil
- Extern 100W
- Betriebssystem
- XP, AndLinux
- Webbrowser
- Firefox
- Verschiedenes
- Kaum hörbar
Hallo, bin beim rumstöbern auf dieses AMD Exascale pdf von 2017 gestoßen:
http://www.computermachines.org/joe/publications/pdfs/hpca2017_exascale_apu.pdf
Seite 3:
Das Bild eines Exascale Chips mit active Interposer GPU mit HBM on top ist natürlich noch ein paar Jahre in die Zukunft, aber man sieht schon mal in welche Richtung es geht. Mal gespannt, wann die erste GPU oder APU mit HBM on top kommt.
ROME könnte schon mal der erste Versuch sein die Chiplet Idee für CPU umzusetzen, noch ohne active Interposer dafür mit diskretem I/O 14nm Chip.
Ich hab mir mal das pdf näher angeschaut und ein paar Daten rausgeschrieben:
---------------------------
ExaflopAPU 2022/23
TDP 200W
Speicherkanäle 8
Chiplets
8 * CPU 4 Core
8 * GPU 32 CU, 2TF DP, 1GHz, 32GB HBM (1Stack) 4GBit/s
Interposer
CPU: 4Chiplets * 4Core = 16Core
GPU: 2Chiplets * 32CU = 64CU, 4TF DP, 64GB HBM
2*4Chiplet*4Core CPU
4*2Chiplet*32CU GPU
Exaflop Chip
32 Core, 256CU, 16TF DP, 256GB HBM, 200W, 8 MC
------------------------
Dabei hab ich mich gefragt: Wie weit ist AMD damit schon?
Die Chiplets: CPU 4 Core entspricht einem CCX. Im Document wird aus Yield Gründen diese minimale Größe vorgeschlagen Zudem wird argumentiert, dass durch selection und zusammenstellen der besten Chips ein performanterer gesamt Chip erstellt werden kann als durch monolitische Chips. Sieht man auch bei Threadripper und EPYC bei denen AMD das Konzept schon getestet hat.
4 dieser Chiplets kommen auf einen Interposer, also 4 CCX = 16 Cores pro Interposer.
ROME
Ich hatte oben schon mal versucht zu rechnen, mich aber bei einigen Dingen vertan, also nochmal rechnen.
Für ZEN 14nm habe ich folgende Daten:
Core 7mm²
Cache L3 8MB, 16mm²
CCX 4 Core, inklusive 8MB L3, 44mm²
Für ZEN2 7nm nehme ich einfach die Hälfte an, bei etwas größerem ZEN2 Core und doppeltem L3 Cache (Laut Gerüchten soll 64 Core Rome 256MB L3 Cache haben, also 4MB/Core -> 16MB/CCX)
Core 4mm²
Cache L3 16MB 16mm²
CCX 4 Core inklusive 16MB L3, 32mm²
Chiplet 7nm 16MBCache/CCX
______________ mm² +Uncore _TDP sweetSpot
_4Core, 1CCX ___32___ ~50___ 10W
_8Core, 2CCX ___64___ ~90___ 20W
16Core, 4CCX __128__ ~160___ 40W
Für ROME würde ich ein 4 Core Chiplet ausschließen wegen dem Aufwand die vielen kleinen Chips nochmals auf einen Interposer zu setzen und dem prozentual größerem Uncore Bereich auf dem Chip.
Der 16 Core Chiplet scheint mit gutem Yield bei ~160mm² noch machbar in 7nm. Würde auch zu den Gerüchten eines 16Core Chips für Rome passen und würde den Interposer einsparen. Nachteilig wäre hingegen die schlechte Weiterverwendbarkeit für andere kleinere Chips und die Selektionsfähigkeit. Läuft nur ein Core nicht performant, kann der ganze Chip nicht für High End eingesetzt werden. Also nur wenige wirklich gute Chips verfügbar.
Kommen wir zu meinem Favoriten, dem 8Core Chiplet. Handliche Größe, für AM4 CPU/APU und Embedded weiterverwendbar und wie man bei Threadripper sieht auch ohne Interposer einsetzbar.
Mit den Rome Chiplets hat AMD jedenfalls schonmal die CPU Komponenten für die ExaflopAPU. 32 Core bei <100W sind damit machbar und AMD kann nun am active Interposer arbeiten.
GPU
Bei den Daten für ein GPU Chiplet: GPU 32 CU, 2TF DP, 1GHz, 32GB HBM (1Stack) 4GBit/s
mußte ich an VEGA Mobile denken. Geschätzt wurden dort 28/32CUs bei 1,1 - 1,3 GHz, 1HBM Stack auf passive Interposer.
Hat AMD damit schon die GPU Komponente für den Exaflop Chip?
Oder doch eher VEGA20 7nm? Zwar doppelt so groß, könnte damit aber direkt 2 GPU Chiplets des Exaflops Konzeptes ersetzen.
Etwas runtergetaktet dürfte VEGA20 7nm mit 100W immer noch 4TFlops DP liefern
Fazit
AMD dürfte mit VEGA20 und den ROME Chiplets in der Lage sein eine 200W APU zu bauen die über 32 Cores und 4TF DP / 8TF SP verfügt.
Der Verbrauch ist noch zu hoch, da wird man noch auf 5nm oder gar 3nm warten müssen um die Komponenten im Verbrauch zu halbieren.
40W 32 Core CPU + 4 * 40W GPU 4TF DP liegen somit gut im Zeitrahmen für 2022/23.
Wenn ich sehe, dass jetzt 6 Vega GPUs + 32 Kern Prozessor in ein Serverrack gepackt werden und AMD das in ein paar Jahren auf einer ServerCPU anbietet...
Muß sich halt zeigen, ob die ExaflopAPU ihren Anwendungsbereich findet oder ob in ein paar Jahren dann nicht doch lieber 128 Kerne mit 6 dicken entsprechend leistungsfähigen AIB GPUs (was AMD natürich dann auch liefern kann) weiterhin in ein Rack gesteckt werden .
Jedenfalls arbeitet AMD an der ExaflopAPU und die arbeit daran beschert uns mit Ryzen, Threadripper, EPYC sowie den GPUs interessante Produkte mit denen AMD auch gut verdient. AMD hat mit VEGA20 und den Rome Chiplets jedenfalls schon mal die nächsten Komponenten um das ExascaleAPU Projekt weiter zu verfolgen und die nächsten Komponenten wie aktive interposer zu testen ohne gewaltige Summen in die Entwicklung zu stecken.
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Ich glaube jedenfalls es wird dieses mal wieder ein paar Überraschungen geben. Ich denke z.B. der Matisse-Die für den Desktop wird dieses mal auch eine iGPU enthalten, und der wird eher nicht für Server verwendet werden, könnte aber eventuell deshalb auch nur mit 8c/16t kommen. Ich denke auch nicht das der Starship-Die mit 12c/24t geändert wurde, und ich denke das wird es erstmal für die Epyc-Generation und Threatripper sein, mit 1 bis 4 Die pro Package wie gehabt. Der neuere 16c/32t Die ohne Codenamen bisher ist vermutlich schon Zen3 mit AVX512 und wird später (eventuell Anfang 2020) kommen.
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.371
- Renomée
- 9.696
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Be reddit hat jemand auf ein paar AMD Patente in dem Zusammenhang hingewiesen:
[FONT=&]ACCELERATION OF CACHE-TO-CACHE DATA TRANSFERS FOR PRODUCER-CONSUMER COMMUNICATION,[/FONT]
[FONT=&]https://patentscope.wipo.int/search/en/detail.jsf?docId=US225111651
[/FONT]
[FONT=&]LOCALITY-AWARE AND SHARING-AWARE CACHE COHERENCE FOR COLLECTIONS OF PROCESSORS[/FONT]
[FONT=&]https://patentscope.wipo.int/search/en/detail.jsf?docId=US225111645
[/FONT]
[FONT=&]ALLOCATION OF MEMORY BUFFERS IN COMPUTING SYSTEM WITH MULTIPLE MEMORY CHANNELS[/FONT]
[FONT=&]https://patentscope.wipo.int/search/en/detail.jsf?docId=US225111665
[/FONT]
Das wird erstmal nicht Ziel sein. Wenn dann wird über kurz oder lang eh Navi in die APUs wandern.
Wünschenswert wäre, wenn AMD es schafft Vega 20 und Rome im Bereich der Supercomputer mehr zu verzahnen, gerade auch mal um an NVIDIAs Margen zu knabbern.
https://www.top500.org/lists/2018/06/highlights/
[FONT=&]ACCELERATION OF CACHE-TO-CACHE DATA TRANSFERS FOR PRODUCER-CONSUMER COMMUNICATION,[/FONT]
[FONT=&]https://patentscope.wipo.int/search/en/detail.jsf?docId=US225111651
[/FONT]
[FONT=&]LOCALITY-AWARE AND SHARING-AWARE CACHE COHERENCE FOR COLLECTIONS OF PROCESSORS[/FONT]
[FONT=&]https://patentscope.wipo.int/search/en/detail.jsf?docId=US225111645
[/FONT]
[FONT=&]ALLOCATION OF MEMORY BUFFERS IN COMPUTING SYSTEM WITH MULTIPLE MEMORY CHANNELS[/FONT]
[FONT=&]https://patentscope.wipo.int/search/en/detail.jsf?docId=US225111665
[/FONT]
Fazit
AMD dürfte mit VEGA20 und den ROME Chiplets in der Lage sein eine 200W APU zu bauen die über 32 Cores und 4TF DP / 8TF SP verfügt.
Der Verbrauch ist noch zu hoch, da wird man noch auf 5nm oder gar 3nm warten müssen um die Komponenten im Verbrauch zu halbieren.
40W 32 Core CPU + 4 * 40W GPU 4TF DP liegen somit gut im Zeitrahmen für 2022/23.
Das wird erstmal nicht Ziel sein. Wenn dann wird über kurz oder lang eh Navi in die APUs wandern.
Wünschenswert wäre, wenn AMD es schafft Vega 20 und Rome im Bereich der Supercomputer mehr zu verzahnen, gerade auch mal um an NVIDIAs Margen zu knabbern.
https://www.top500.org/lists/2018/06/highlights/
- Accelerators are used in 110 TOP500 systems, a slight increase from the 101 accelerated systems in the November 2017 lists. NVIDIA GPUs are present in 98 of these systems, including five of the top 10: Summit, Sierra, ABCI, Piz Daint, and Titan. Seven systems are equipped with Xeon Phi coprocessors; PEZY accelerators are used in four systems; and the Matrix-2000 coprocessor is used in a single machine, the upgraded Tianhe-2A. An additional 20 systems use Xeon Phi as the main processing unit.
Zuletzt bearbeitet:
HalbeHälfte
Vice Admiral Special
- Mitglied seit
- 30.07.2006
- Beiträge
- 674
- Renomée
- 8
Ich möchte drauf aufmerksam machen , daß wir uns die Shrink-Elation zukünftig wohl in die Haare schmieren können. Jetzt hat TSMC einmal Glück mit den 7nm gehabt, wobei man auch da eher kaum irgendwo Strukturen findet die 7nm klein sind. Das Glück sehe ich bei TSMC wie bei dem Rest zukünftig nicht fortlaufend gegeben.
Das Voranpeitschen ist in dem Selbstversprechen der Fertiger begründet, in selbst auferlegten Perioden zum nächsten Shrink überzugehen. Da gibt es gar eine internatonale Roadmap der Fertiger (ITRS). Wobei das einzige was man seit einiger Zeit voranpeitscht sind nur die Marketingnamen der Prozesse...
Das soll jetzt nicht als deutliche Kritik verstanden werden. Mir selbst geht das schnell genug voran Man kann auch aus optimierten "14nm" (16/14) mittlerweile relativ preiswerte leistungsfähige Chips anbieten die in allereli Geräten wundersames (bisher) leisten können. Z.B. passiv gekühlte, handwarme 8fach 10Gb Switche, handflächen große VDSL2+ Router, ähnlich große und kühle Settop-Boxen mit der Leistung irgendeines i3, DSPs für TVs die Scaling neu definieren usw. usw. Alles gut.
Man kann auch aus optimierten "14nm" (16/14) mittlerweile relativ preiswerte leistungsfähige Chips anbieten die in allereli Geräten wundersames (bisher) leisten können. Z.B. passiv gekühlte, handwarme 8fach 10Gb Switche, handflächen große VDSL2+ Router, ähnlich große und kühle Settop-Boxen mit der Leistung irgendeines i3, DSPs für TVs die Scaling neu definieren usw. usw. Alles gut.
Ähnliches gilt später wie teilweise jetzt schon den 12LP & Co. Prozessen.
Allerdings steigen die Kosten für Masken und Maschinen wie auch die der Produktionslinien selbst, mittlerweile exorbitant. Daß wir 5nm so schnell wie hier vermutet in der Produktion sehen werden, das glaube ich erst, wenn ich es sehe
, daß wir uns die Shrink-Elation zukünftig wohl in die Haare schmieren können. Jetzt hat TSMC einmal Glück mit den 7nm gehabt, wobei man auch da eher kaum irgendwo Strukturen findet die 7nm klein sind. Das Glück sehe ich bei TSMC wie bei dem Rest zukünftig nicht fortlaufend gegeben.Das Voranpeitschen ist in dem Selbstversprechen der Fertiger begründet, in selbst auferlegten Perioden zum nächsten Shrink überzugehen. Da gibt es gar eine internatonale Roadmap der Fertiger (ITRS). Wobei das einzige was man seit einiger Zeit voranpeitscht sind nur die Marketingnamen der Prozesse...
Das soll jetzt nicht als deutliche Kritik verstanden werden. Mir selbst geht das schnell genug voran
Man kann auch aus optimierten "14nm" (16/14) mittlerweile relativ preiswerte leistungsfähige Chips anbieten die in allereli Geräten wundersames (bisher) leisten können. Z.B. passiv gekühlte, handwarme 8fach 10Gb Switche, handflächen große VDSL2+ Router, ähnlich große und kühle Settop-Boxen mit der Leistung irgendeines i3, DSPs für TVs die Scaling neu definieren usw. usw. Alles gut.Ähnliches gilt später wie teilweise jetzt schon den 12LP & Co. Prozessen.
Allerdings steigen die Kosten für Masken und Maschinen wie auch die der Produktionslinien selbst, mittlerweile exorbitant. Daß wir 5nm so schnell wie hier vermutet in der Produktion sehen werden, das glaube ich erst, wenn ich es sehe
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Naja, mal abwarten. Ich denke die große Zukunft liegt in komplett anderen Materialien. Aber vielleicht ist mit so Sachen wie GAA noch was herauszuholen.
HalbeHälfte
Vice Admiral Special
- Mitglied seit
- 30.07.2006
- Beiträge
- 674
- Renomée
- 8
Da würde ich eher sagen, in teilweise anderen, und nicht komplett anderen, Materialien Soweit stimmts aber. Nur machen diese imho bisher die Strukturen belastbarer, verursachen aber nicht weniger Aufwand bei weiteren Shrinks (?) Imho, Verlinkungen auf Fachartikel dazu wären an der Stelle daher passend
edit:
Ja ok. Die "große Zukunft" ist natürlich gut dehnbar Ich bin aber langsam der Meinung, bei 5nm ist nahezu Ende. Die erwähnte Roadmap geht übrigens auch nur bis 2020 und 5nm. Das kann gut sein, daß man dann irgendetwas "5nm" nennt... Mehr scheint bisher aber keiner versprechen zu wollen.
Soweit stimmts aber. Nur machen diese imho bisher die Strukturen belastbarer, verursachen aber nicht weniger Aufwand bei weiteren Shrinks (?) Imho, Verlinkungen auf Fachartikel dazu wären an der Stelle daher passend edit:
Ja ok. Die "große Zukunft" ist natürlich gut dehnbar
Ich bin aber langsam der Meinung, bei 5nm ist nahezu Ende. Die erwähnte Roadmap geht übrigens auch nur bis 2020 und 5nm. Das kann gut sein, daß man dann irgendetwas "5nm" nennt... Mehr scheint bisher aber keiner versprechen zu wollen.
Zuletzt bearbeitet:
BoMbY
Grand Admiral Special
- Mitglied seit
- 22.11.2001
- Beiträge
- 7.468
- Renomée
- 293
- Standort
- Aachen
- Details zu meinem Desktop
- Prozessor
- Ryzen 3700X
- Mainboard
- Gigabyte X570 Aorus Elite
- Kühlung
- Noctua NH-U12A
- Speicher
- 2x16 GB, G.Skill F4-3200C14D-32GVK @ 3600 16-16-16-32-48-1T
- Grafikprozessor
- RX 5700 XTX
- Display
- Samsung CHG70, 32", 2560x1440@144Hz, FreeSync2
- SSD
- AORUS NVMe Gen4 SSD 2TB, Samsung 960 EVO 1TB, Samsung 840 EVO 1TB, Samsung 850 EVO 512GB
- Optisches Laufwerk
- Sony BD-5300S-0B (eSATA)
- Gehäuse
- Phanteks Evolv ATX
- Netzteil
- Enermax Platimax D.F. 750W
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox
Kohlenstoff hat glaube ich gute Aussichten Silizium abzulösen, daran dachte ich zum Beispiel. Aber klar, selbst SiC scheint prinzipiell gute Eigenschaften zu haben, ist aber schwer zu verarbeiten.
Pinnacle Ridge
Vice Admiral Special
- Mitglied seit
- 04.03.2017
- Beiträge
- 528
- Renomée
- 7
Sollten die Masken nicht mit EUV erheblich billiger werden, weil man weniger braucht?
Die ausbeite sollte auch steigen, weil weniger Belichtungsschritte nötig sind?
Nach HinFET geht es mit Gaa-FET weiter, danach erreicht man mit Kohlenstoff vielleicht irgendwann viel viel höhere Taktraten als heute.
Wir alle werden ein Ende des Vortschrittes bei der Chipfertigung nicht mehr erleben!
Die ausbeite sollte auch steigen, weil weniger Belichtungsschritte nötig sind?
Nach HinFET geht es mit Gaa-FET weiter, danach erreicht man mit Kohlenstoff vielleicht irgendwann viel viel höhere Taktraten als heute.
Wir alle werden ein Ende des Vortschrittes bei der Chipfertigung nicht mehr erleben!
- Mitglied seit
- 16.10.2000
- Beiträge
- 24.371
- Renomée
- 9.696
- Standort
- East Fishkill, Minga, Xanten
- Aktuelle Projekte
- Je nach Gusto
- Meine Systeme
- Ryzen 9 5900X, Ryzen 7 3700X
- BOINC-Statistiken
- Folding@Home-Statistiken
- Mein Laptop
- Samsung P35 (16 Jahre alt ;) )
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 9 5900X
- Mainboard
- ASRock B550
- Speicher
- 2x 16 GB DDR4 3200
- Grafikprozessor
- GeForce GTX 1650
- Display
- 27 Zoll Acer + 24 Zoll DELL
- SSD
- Samsung 980 Pro 256 GB
- HDD
- diverse
- Soundkarte
- Onboard
- Gehäuse
- Fractal Design R5
- Netzteil
- be quiet! Straight Power 10 CM 500W
- Tastatur
- Logitech Cordless Desktop
- Maus
- Logitech G502
- Betriebssystem
- Windows 10
- Webbrowser
- Firefox, Vivaldi
- Internetanbindung
- ▼250 MBit ▲40 MBit
Wir alle werden ein Ende des Fortschrittes bei der Chipfertigung nicht mehr erleben!
Die Zyklen werden wohl länger werden und was wir ja jetzt schon sehen, dass man die einzelnen Fertigungsprozesse über Jahre in verschiedenen Iterationen immer mehr verbessert.
Pinnacle Ridge
Vice Admiral Special
- Mitglied seit
- 04.03.2017
- Beiträge
- 528
- Renomée
- 7
Verbesserungen sind es halt trotzdem.dass man die einzelnen Fertigungsprozesse über Jahre in verschiedenen Iterationen immer mehr verbessert.
Manche tun oft so, also würde sich jahrelang nichts ändern.
Ähnliche Themen
- Antworten
- 0
- Aufrufe
- 393
- Antworten
- 4
- Aufrufe
- 1K
- Antworten
- 0
- Aufrufe
- 561