Ansätze der Optimierung per Hardware (Fortsetzung)
Symmetric
Multi-Processing (Fortsetzung)
Ein weiteres Problem stellt die Kohärenz der Inhalte der unterschiedlichen
Cache-Hierarchien dar. Cache-Kohärenz bedeutet die Wahrung der Gültigkeit
der Inhalte der Caches. Wird beispielsweise ein Wert aus dem Arbeitsspeicher
von beiden Prozessoren in den jeweils eigenen Cache geladen und von einem anschließend
verändert wieder zurückgeschrieben, muss der zweite Prozessor von
diesem Vorgang Wissen haben, um seine eigenen Caches entsprechend zu aktualisieren.
SMP-Systeme haben
hierfür ein sog. Cache-Kohärenz Protokoll, welches für die Korrektheit
der Daten sorgt.
Das Protokoll mit der höchsten Verbreitung ist das sog. MESI-Protokoll.
Jeder der Buchstaben steht hierbei für einen bestimmten Zustand einer Cache-Line,
die einzelnen Zustände sind wie folgt definiert:
Modified:
Der Inhalt im Arbeitsspeicher wurde seit dem spiegeln in den lokalen Prozessorcache
modifiziert und stimmt somit nicht mehr überein
Exclusive:
Der Inhalt im Arbeitsspeicher stimmt noch mit dem gespiegelten Inhalt
im Cache überein. Die Cache-Line befindet sich nur im Cache eines einzelnen
Prozessors.
Shared: Wie
Exclusive, nur mit der Unterscheidung dass sich die Cache-Line in mehreren
Caches befindet. Bei Aktualisierung der ursprünglichen Daten im Arbeitsspeicher
werden alle Caches auf den neuesten Stand gebracht.
Invalid:
Der Inhalt im Prozessorcache ist ungültig, ein Zugriff erzeugt einen Cache-Miss.
Die Daten müssen neu aus dem Arbeitsspeicher geladen werden.
Die Erhaltung der
Korrektheit der Daten (auf fachchinesisch Kohärenz genannt) kostet jedoch
ein klein wenig Performance, was je nach Umsetzung des Protokolls unterschiedlich
gravierend ausfallen kann.
Eine Erweiterung des MESI-Protokolls stellt das noch nicht so verbreitete MOESI-Protokoll
dar. Es ist im Grunde genommen zum MESI-Protokoll 100%ig kompatibel, kennt jedoch
noch einen zusätzlichen Status:
Owner: Zeigt
an in welchem Cache welches Prozessors sich die Daten befinden. Somit können
andere Prozessoren bei Bedarf diese Daten aus dem Cache anfordern und sparen
sich den dazu im Vergleich sehr langsamen Hauptspeicherzugriff.
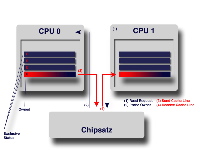
Hierbei passiert folgendes: Stellt CPU1 einen Read-Request auf einen bestimmten
Speicherbereich (1) wird dieser in der Regel direkt aus
dem Arbeitsspeicher in den Cache der CPU geladen. Merkt die Chipsatzlogik
jedoch, dass eine weitere sich im System befindliche CPU genau diesen Speicherbereich
bereits im Cache hat, so wird der Read-Request vom langesamen Arbeitsspeicher
auf den schnellen Cache der betreffenden CPU umgeleitet. (2)
Die betreffende CPU (im Beispiel CPU0) überträgt die Cache-Line anschließend
zum Chipsatz, (3) welcher sie direkt weiterleitet an CPU1
(4). Somit werden massiv Taktzyklen eingespart die beim
Zugriff auf den im Vergleich zum schnellen Cache um den Faktor hundert bis
einige Tausend langsameren Arbeitsspeicher mit Nichtstun verbracht worden
wären.
Weiterhin profitiert auch der Speicherbus von dieser Taktik, da weniger
Zugriffe auf den Speicherbus stattfinden und er somit für andere Aufgaben
verfügbar ist.
Der durch die Wahrung
der Kohärenz verursachte Performanceverlust wird durch effiziente Umsetzung
des MOESI-Protokolls anstelle des MESI-Protokolls wieder mehr als wettgemacht.



Diesen Artikel bookmarken oder senden an ...