Doping fû¥r CPUs ã MûÑglichkeiten der Leistungssteigerung
AnsûÊtze der Optimierung per Hardware (SMP Fortsetzung)
SymôÙmeôÙtric MulôÙti-ProôÙcesôÙsing (FortôÙsetôÙzung)
Ein weiôÙteôÙres ProôÙblem stellt die KohûÊôÙrenz der InhalôÙte der unterôÙschiedôÙliôÙchen Cache-HierôÙarôÙchien dar. Cache-KohûÊôÙrenz bedeuôÙtet die WahôÙrung der Gû¥lôÙtigôÙkeit der InhalôÙte der Caches. Wird beiôÙspielsôÙweiôÙse ein Wert aus dem ArbeitsôÙspeiôÙcher von beiôÙden ProôÙzesôÙsoôÙren in den jeweils eigeôÙnen Cache gelaôÙden und von einem anschlieôÙûend verôÙûÊnôÙdert wieôÙder zurû¥ckôÙgeôÙschrieôÙben, muss der zweiôÙte ProôÙzesôÙsor von dieôÙsem VorôÙgang WisôÙsen haben, um seiôÙne eigeôÙnen Caches entôÙspreôÙchend zu aktualisieren.
SMP-SysôÙteôÙme haben hierôÙfû¥r ein sog. Cache-KohûÊôÙrenz ProôÙtoôÙkoll, welôÙches fû¥r die KorôÙrektôÙheit der Daten sorgt.
Das ProôÙtoôÙkoll mit der hûÑchsôÙten VerôÙbreiôÙtung ist das sog. MESI-ProôÙtoôÙkoll. Jeder der BuchôÙstaôÙben steht hierôÙbei fû¥r einen bestimmôÙten Zustand einer Cache-Line, die einôÙzelôÙnen ZustûÊnôÙde sind wie folgt definiert:
* ExcluôÙsiôÙve: Der Inhalt im ArbeitsôÙspeiôÙcher stimmt noch mit dem gespieôÙgelôÙten Inhalt im Cache û¥berôÙein. Die Cache-Line befinôÙdet sich nur im Cache eines einôÙzelôÙnen Prozessors.
* Shared: Wie ExcluôÙsiôÙve, nur mit der UnterôÙscheiôÙdung dass sich die Cache-Line in mehôÙreôÙren Caches befinôÙdet. Bei AktuaôÙliôÙsieôÙrung der ursprû¥ngôÙliôÙchen Daten im ArbeitsôÙspeiôÙcher werôÙden alle Caches auf den neuôÙesôÙten Stand gebracht.
* InvaôÙlid: Der Inhalt im ProôÙzesôÙsorôÙcache ist ungû¥lôÙtig, ein Zugriff erzeugt einen Cache-Miss. Die Daten mû¥sôÙsen neu aus dem ArbeitsôÙspeiôÙcher gelaôÙden werden.
Die ErhalôÙtung der KorôÙrektôÙheit der Daten (auf fachôÙchiôÙneôÙsisch KohûÊôÙrenz genannt) kosôÙtet jedoch ein klein wenig PerôÙforôÙmance, was je nach UmsetôÙzung des ProôÙtoôÙkolls unterôÙschiedôÙlich graôÙvieôÙrend ausôÙfalôÙlen kann.
Eine ErweiôÙteôÙrung des MESI-ProôÙtoôÙkolls stellt das noch nicht so verôÙbreiôÙteôÙte MOEôÙSI-ProôÙtoôÙkoll dar. Es ist im GrunôÙde genomôÙmen zum MESI-ProôÙtoôÙkoll 100%ig komôÙpaôÙtiôÙbel, kennt jedoch noch einen zusûÊtzôÙliôÙchen Status:
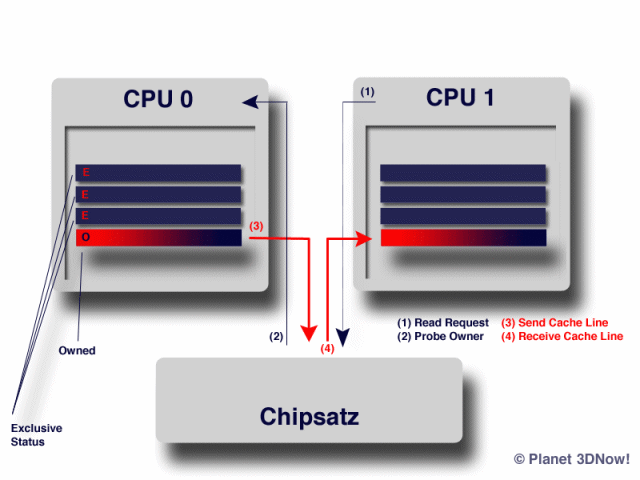
HierôÙbei pasôÙsiert folôÙgenôÙdes: Stellt CPU1 einen Read-Request auf einen bestimmôÙten SpeiôÙcherôÙbeôÙreich (1) wird dieôÙser in der Regel direkt aus dem ArbeitsôÙspeiôÙcher in den Cache der CPU gelaôÙden. Merkt die ChipôÙsatzôÙloôÙgik jedoch, dass eine weiôÙteôÙre sich im SysôÙtem befindôÙliôÙche CPU genau dieôÙsen SpeiôÙcherôÙbeôÙreich bereits im Cache hat, so wird der Read-Request vom lanôÙgeôÙsaôÙmen ArbeitsôÙspeiôÙcher auf den schnelôÙlen Cache der betrefôÙfenôÙden CPU umgeôÙleiôÙtet. (2)
Die betrefôÙfenôÙde CPU (im BeiôÙspiel CPU0) û¥berôÙtrûÊgt die Cache-Line anschlieôÙûend zum ChipôÙsatz, (3) welôÙcher sie direkt weiôÙterôÙleiôÙtet an CPU1 (4). Somit werôÙden masôÙsiv TaktôÙzyôÙklen einôÙgeôÙspart die beim Zugriff auf den im VerôÙgleich zum schnelôÙlen Cache um den FakôÙtor hunôÙdert bis einiôÙge TauôÙsend langôÙsaôÙmeôÙren ArbeitsôÙspeiôÙcher mit NichtsôÙtun verôÙbracht worôÙden wûÊren.
WeiôÙterôÙhin proôÙfiôÙtiert auch der SpeiôÙcherôÙbus von dieôÙser TakôÙtik, da weniôÙger ZugrifôÙfe auf den SpeiôÙcherôÙbus stattôÙfinôÙden und er somit fû¥r andeôÙre AufôÙgaôÙben verôÙfû¥gôÙbar ist.
Der durch die WahôÙrung der KohûÊôÙrenz verôÙurôÙsachôÙte PerôÙforôÙmanceôÙverôÙlust wird durch effiôÙziôÙenôÙte UmsetôÙzung des MOEôÙSI-ProôÙtoôÙkolls anstelôÙle des MESI-ProôÙtoôÙkolls wieôÙder mehr als wettgemacht.