AMD Zen 3 Architektur im Detail
├änderungen ŌĆō Front-End und Load/Store
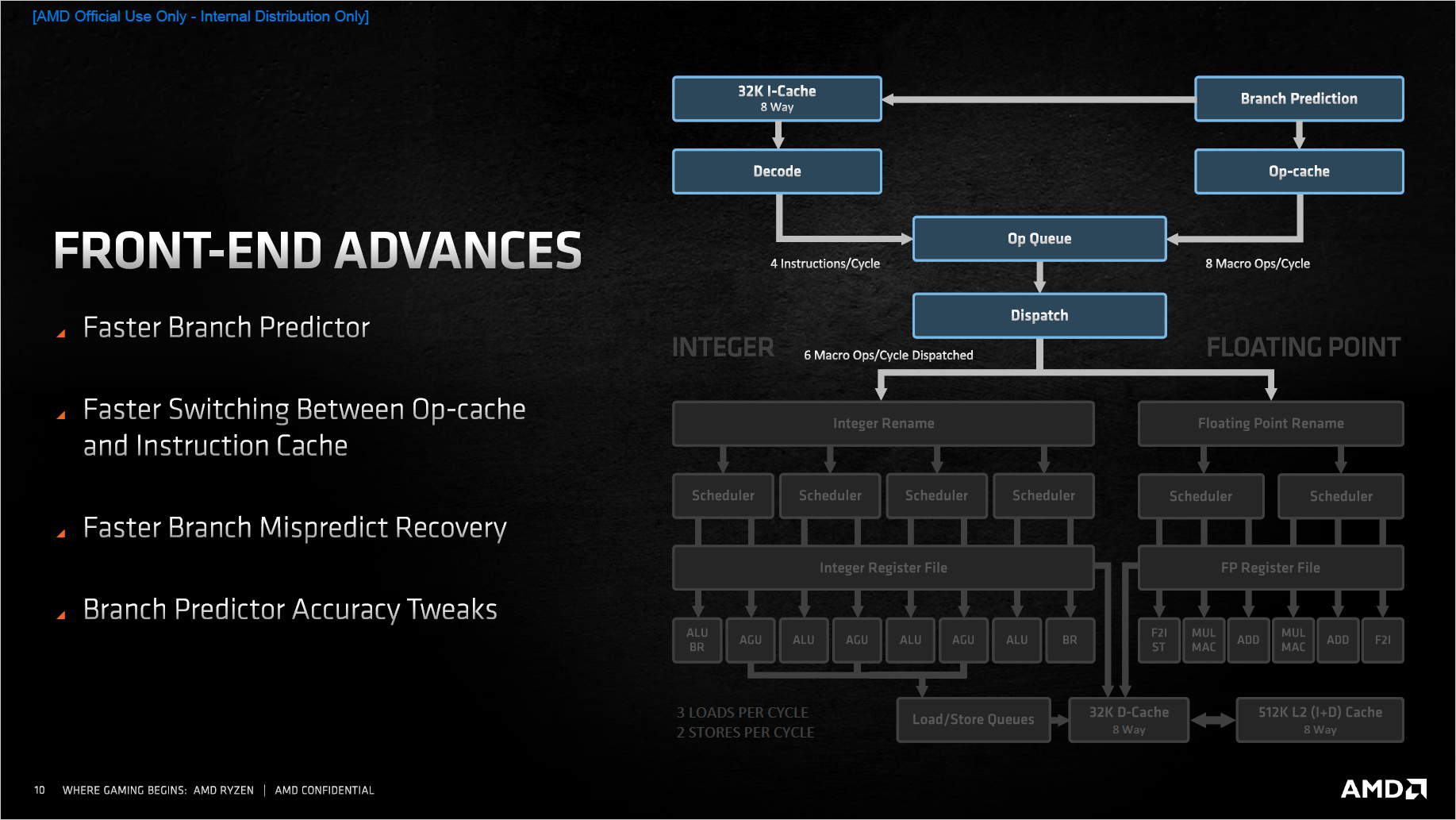
Nicht nur bei der Kom┬Łmu┬Łni┬Łka┬Łti┬Łon zwi┬Łschen ein┬Łzel┬Łnen Ker┬Łnen, auch bei der Ver┬Łar┬Łbei┬Łtung inner┬Łhalb eines Kerns hat AMD ver┬Łsucht, Laten┬Łzen abzu┬Łfei┬Łlen und Tot┬Łzeit zu redu┬Łzie┬Łren. So pro┬Łkla┬Łmiert AMD einen schnel┬Łle┬Łren Branch Pre┬Łdic┬Łtor, ein schnel┬Łle┬Łres Umschal┬Łten zwi┬Łschen Op-cache und Ins┬Łtruc┬Łtion Cache, eine h├Čhe┬Łre Tref┬Łfer┬Łquo┬Łte des Branch Pre┬Łdic┬Łtors und eine k├╝r┬Łze┬Łre Reco┬Łvery Zeit falls der Pre┬Łdic┬Łtor falsch gele┬Łgen hat. Ins┬Łge┬Łsamt war das Design┬Łziel laut AMD, die Fetch┬Łpha┬Łse zu ver┬Łk├╝r┬Łzen, ins┬Łbe┬Łson┬Łde┬Łre bei Code, der vie┬Łle Spr├╝n┬Łge ent┬Łh├żlt und auf┬Łgrund der Gr├Č┬Ł├¤e auf Pre┬Łfetch ange┬Łwie┬Łsen ist.
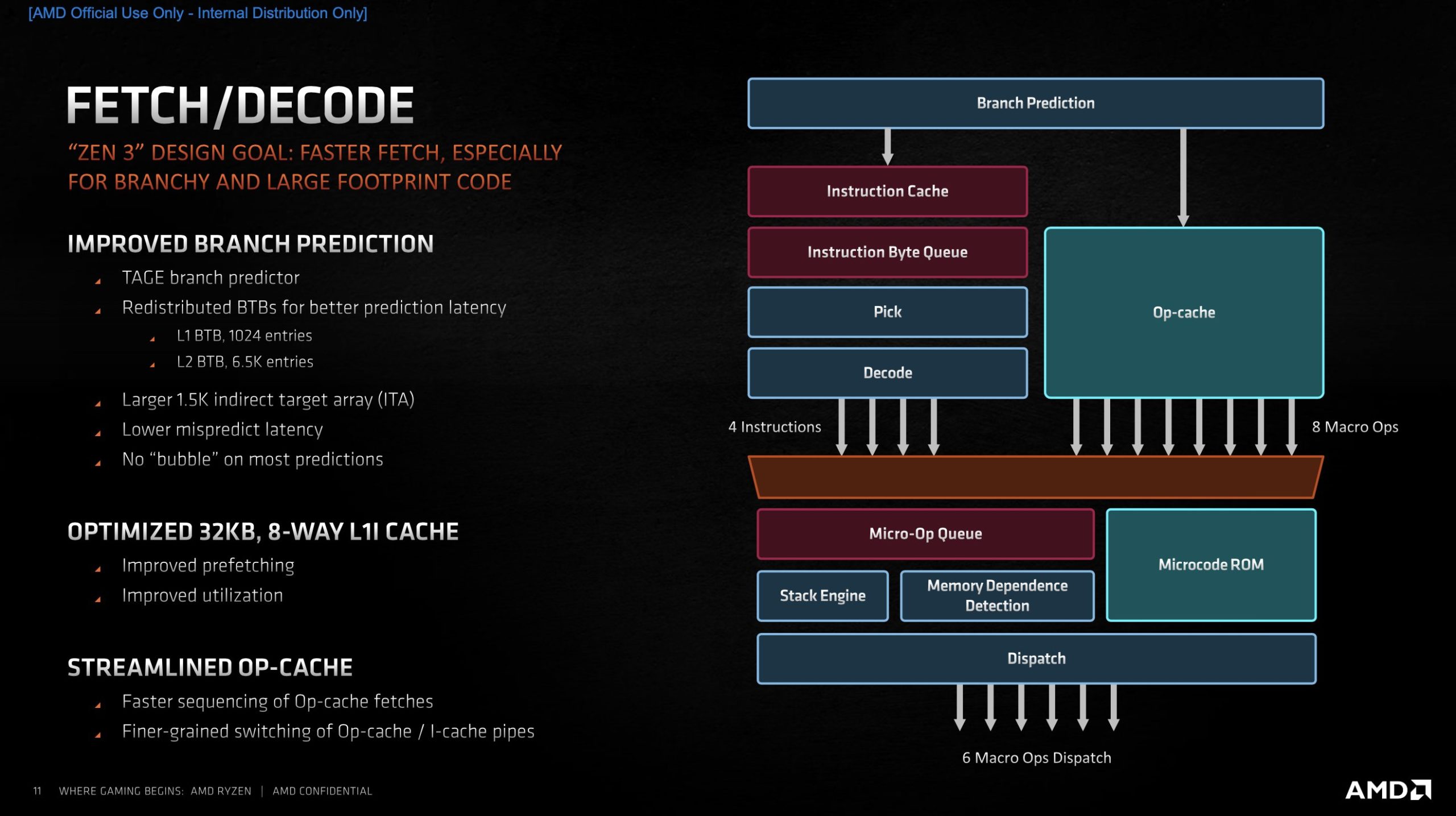
Wie schon bei Zen 2 setzt AMD auf einen TAGE Branch Pre┬Łdic┬Łtor. Aller┬Łdings arbei┬Łtet die┬Łser laut AMD nun bei den meis┬Łten Vor┬Łher┬Łsa┬Łgen mit ŌĆ£Zero BubbleŌĆØ, also ohne Ver┬Łz├Č┬Łge┬Łrung beim Aus┬Łle┬Łsen des Branch Tar┬Łget Buf┬Łfers (BTB), an wel┬Łcher Adres┬Łse denn nun der n├żchs┬Łte Befehl zu fin┬Łden ist. ├£ber┬Łhaupt hat AMD am BTB ordent┬Łlich Hand ange┬Łlegt. der L1BTB ist mit 1024 Ein┬Łtr├ż┬Łgen glatt dop┬Łpelt so gro├¤ wie bei Zen 2 und vier Mal so gro├¤ wie bei Zen 1. Daf├╝r muss┬Łte der L2TLB mit 6500 vs. 7000 Ein┬Łtr├ż┬Łgen etwas Federn lassen.
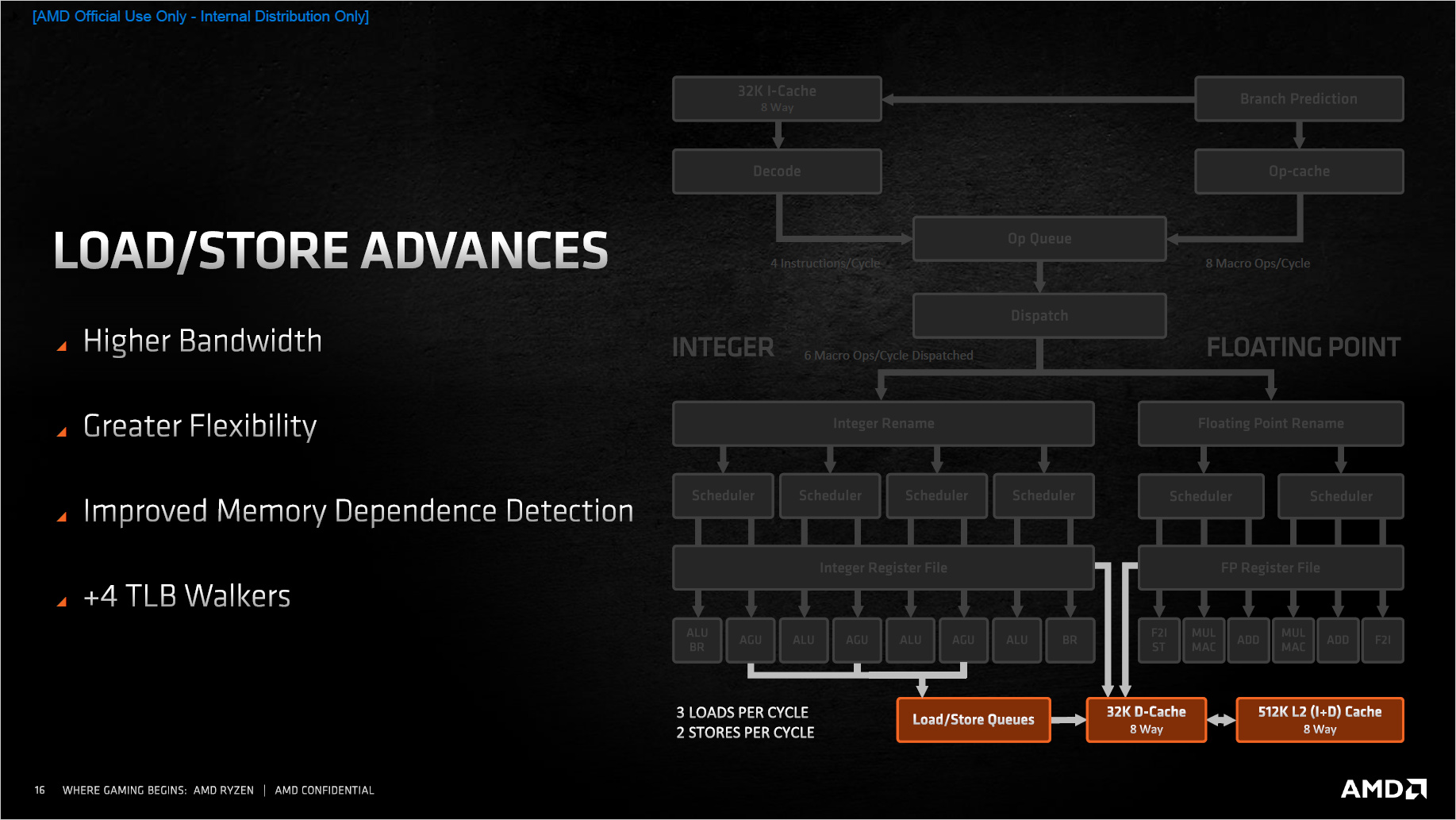
Beim Lesen und Schrei┬Łben von Daten (Load/Store) hat AMD eben┬Łfalls opti┬Łmiert. Die Store Queue hat nun 64 Ein┬Łtr├ż┬Łge gegen┬Ł├╝ber 48 zuvor. Ins┬Łge┬Łsamt sol┬Łlen gr├Č┬Ł├¤e┬Łre Struk┬Łtu┬Łren vor┬Łge┬Łla┬Łden wer┬Łden k├Čn┬Łnen, um Abh├żn┬Łgig┬Łkei┬Łten bes┬Łser auf┬Łl├Č┬Łsen zu k├Čn┬Łnen und mehr Ins┬Łtruc┬Łtion Level Par┬Łal┬Łle┬Łlism (ILP) zu errei┬Łchen, um die Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten bes┬Łser aus┬Łlas┬Łten zu k├Čn┬Łnen. Dazu wur┬Łde die Trans┬Łfer┬Łra┬Łte der Loa┬Łd/S┬Łto┬Łre-Ein┬Łhei┬Łten ver┬Łgr├Č┬Ł├¤ert und fle┬Łxi┬Łbler gestaltet.