AMD Zen 3 Architektur im Detail
├änderungen ŌĆō INT und FP Execution
Ein┬Łhei┬Łten
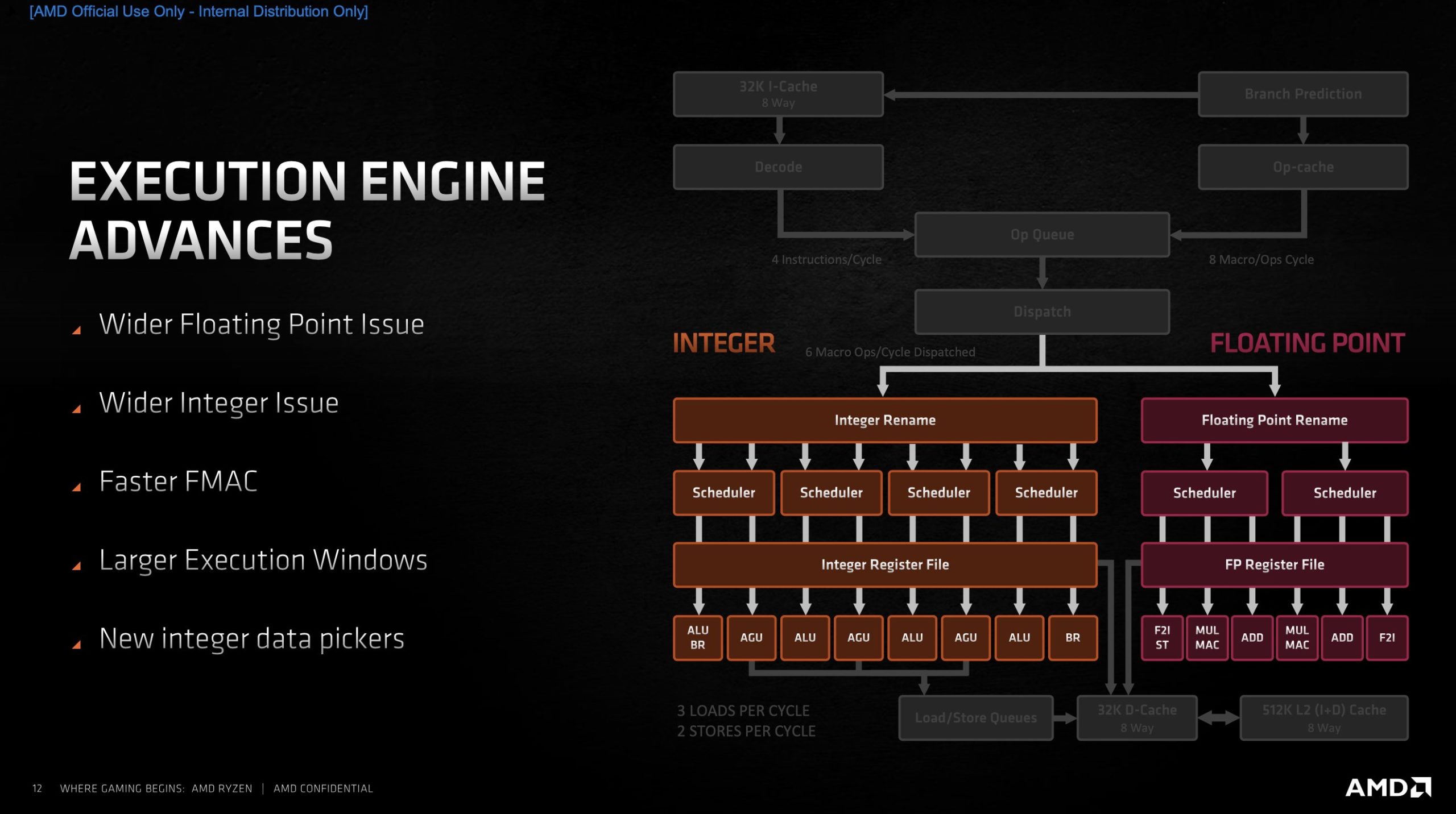
Sobald alle Befeh┬Łle deko┬Łdiert und gela┬Łden sind, die Daten geholt und in der Queue bereit zur Bear┬Łbei┬Łtung, beginnt die eigent┬Łli┬Łche Berech┬Łnung durch die Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten. Deren Anzahl hat AMD aber┬Łmals erh├Čht, das Design ist also noch┬Łmal brei┬Łter gewor┬Łden. Zen 3 hat nun nicht weni┬Łger als 16 Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten neben┬Łein┬Łan┬Łder je Kern (vor┬Łher 11).
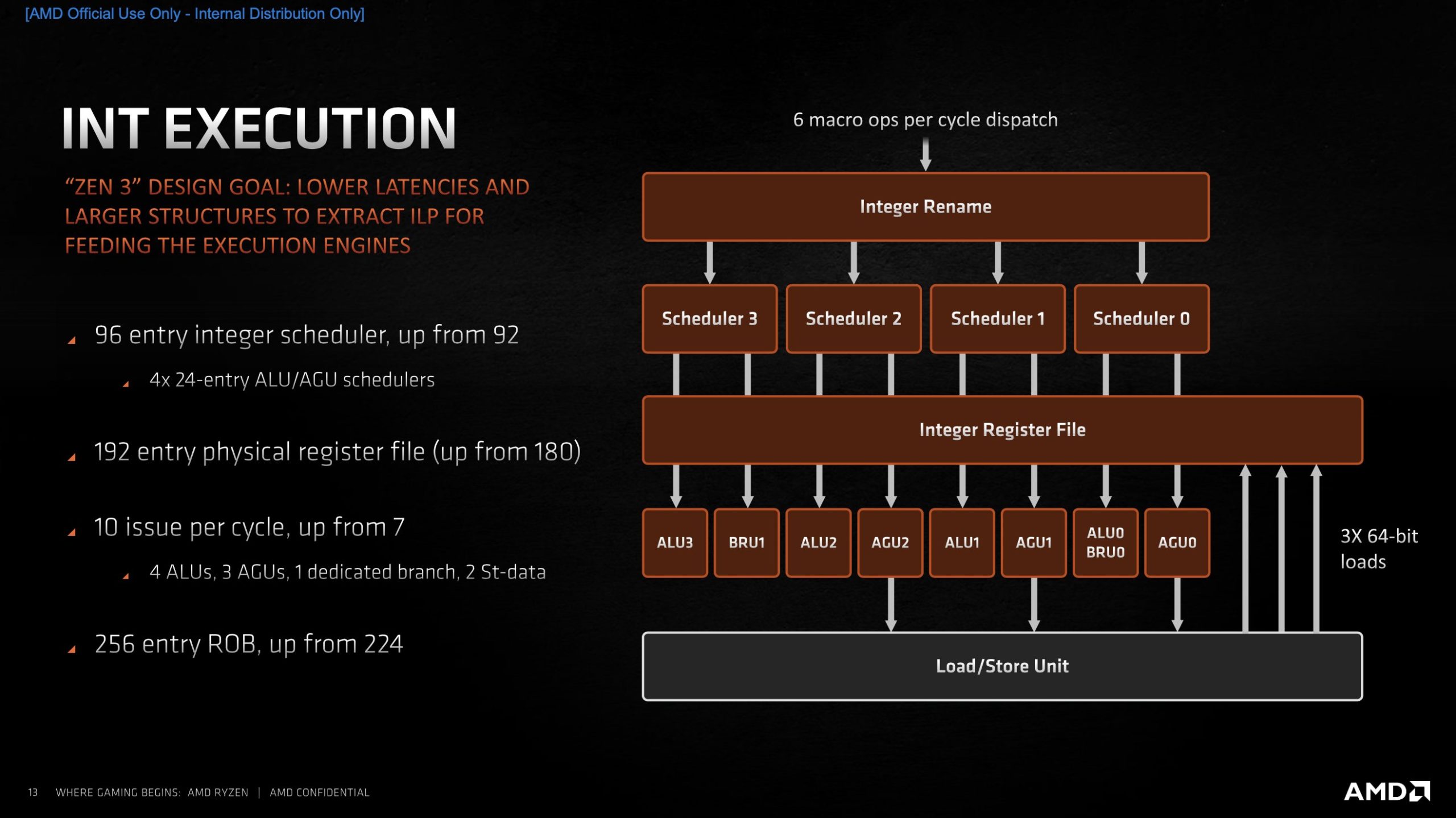
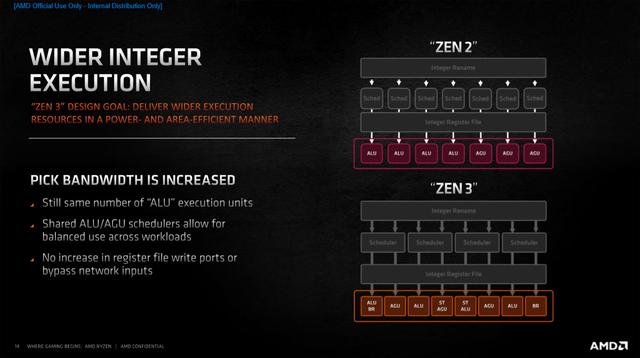
Wie ├╝blich bei allen AMD-Designs der letz┬Łten Jahr┬Łzehn┬Łte ist der Inte┬Łger-Bereich getrennt vom Flie├¤┬Łkom┬Łma-Bereich. Die INT-Sche┬Łdu┬Łler fas┬Łsen nun ins┬Łge┬Łsamt 96 Ein┬Łtr├ż┬Łge (vor┬Łher 92). Inter┬Łes┬Łsant ist aber, dass es nur noch 4 davon gibt (vor┬Łher 7). Die neu┬Łen Sche┬Łdu┬Łler tei┬Łlen sich nun jeweils eine ALU (Arith┬Łme┬Łtic Logic Unit) und eine AGU (Address Gene┬Łra┬Łti┬Łon Unit). Laut AMD soll dies zu einer aus┬Łge┬Łgli┬Łche┬Łne┬Łren Last┬Łver┬Łtei┬Łlung gemit┬Łtelt ├╝ber ver┬Łschie┬Łde┬Łne Workloads f├╝h┬Łren. Lei┬Łder geht AMD nicht tie┬Łfer dar┬Łauf ein, wie es zu die┬Łser Design┬Łent┬Łschei┬Łdung gekom┬Łmen ist und wo man sich Vor┬Łtei┬Łle davon verspricht.
Das Phy┬Łsi┬Łcal Regis┬Łter File hat nun 192 Ein┬Łtr├ż┬Łge (vor┬Łher 180), der Re-order Buf┬Łfer (ROB) 256 statt 224.
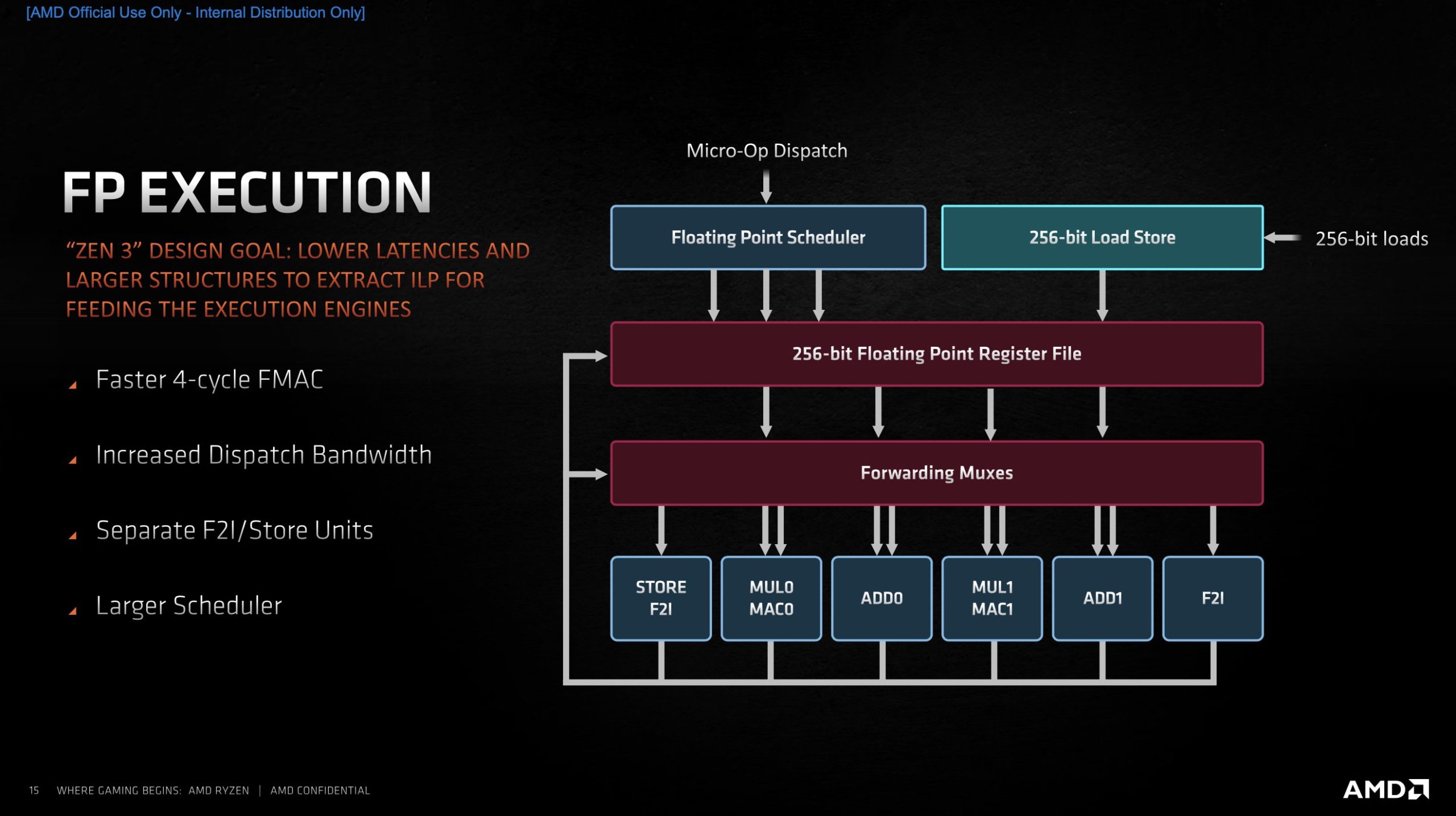
Auch bei der Flie├¤┬Łkom┬Łma-Ein┬Łheit setzt AMD voll auf k├╝r┬Łze┬Łre Laten┬Łzen und h├Čhe┬Łre Band┬Łbrei┬Łte. Auch hier wur┬Łde der Sche┬Łdu┬Łler ver┬Łgr├Č┬Ł├¤ert. An der Brei┬Łte hat sich aber nichts ge├żn┬Łdert. Hier fand die letz┬Łte gr├Č┬Ł├¤e┬Łre Design┬Ł├żn┬Łde┬Łrung bei der Umstel┬Łlung von Zen 1 auf Zen 2 statt, wo die Brei┬Łte von 128 auf 256 Bit erh├Čht wur┬Łde. Wie schon bei Zen 1/2 und Bull┬Łdo┬Łzer ist die Flie├¤┬Łkom┬Łma-Ein┬Łheit als FMAC-Ein┬Łheit aus┬Łge┬Łf├╝hrt, kann also Fused mul┬Łti┬Łply-add und Multiply-Accumulate.
Befehls┬Łsatz
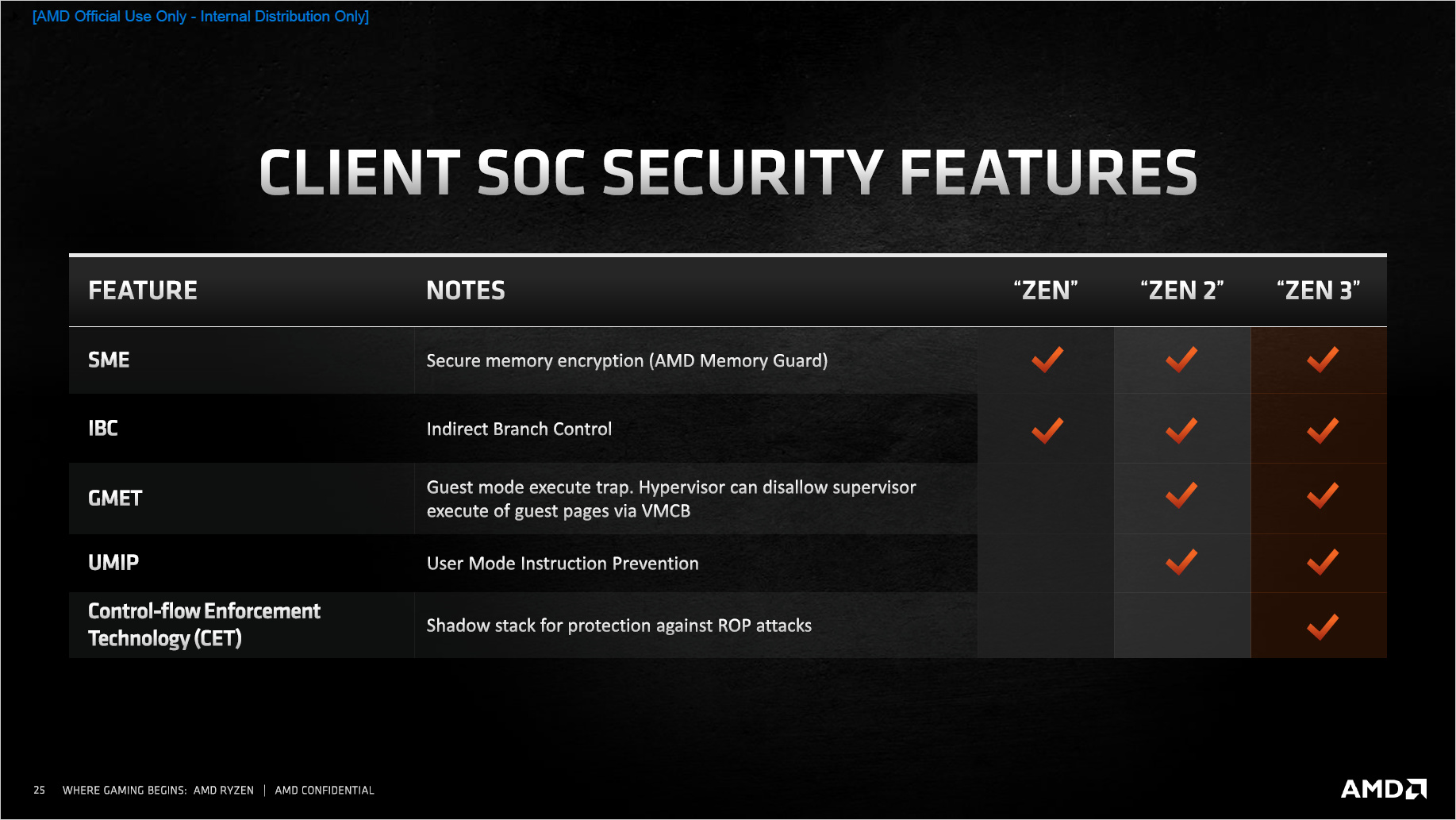
Abge┬Łse┬Łhen von der gr├Č┬Ł├¤e┬Łren Anzahl an Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten hat AMD Zen 3 auch einen gr├Č┬Ł├¤e┬Łren Befehls┬Łsatz spen┬Łdiert. Die CPU beherrscht also Befeh┬Łle, die der Vor┬Łg├żn┬Łger noch nicht konn┬Łte. Im Gegen┬Łsatz zu fr├╝┬Łhe┬Łren Gene┬Łra┬Łtio┬Łnen, wo mit schmis┬Łsi┬Łgen Bezeich┬Łnun┬Łgen wie SSE oder AVX gan┬Łze Befehls┬Łfa┬Łmi┬Łli┬Łen ein┬Łge┬Łbaut wur┬Łden, sind es die┬Łses Mal nur ein┬Łzel┬Łne Zusatz┬Łbe┬Łfeh┬Łle, die Zen 3 nun zum Vor┬Łteil gerei┬Łchen sol┬Łlen. Zum einen geht es um Sicher┬Łheits┬Łfea┬Łtures ŌĆō hier ist die Con┬Łtrol-flow Enforce┬Łment Tech┬Łno┬Łlo┬Łgy (CET) zu nen┬Łnen, die vor Return Ori┬Łen┬Łted Pro┬Łgramming Atta┬Łcken (ROP attack) sch├╝t┬Łzen soll ŌĆō zum ande┬Łren gibt es nun MPK (Spei┬Łcher┬Łschutz) und VAES/VPCLMULQD (AVX2-Sup┬Łport) als neue Befeh┬Łle. Ins┬Łbe┬Łson┬Łde┬Łre Vec┬Łtor AES k├Čnn┬Łte bei den Kryp┬Łto-Minern auf Inter┬Łes┬Łse sto┬Ł├¤en, das nun in AVX2, also 256 Bit Brei┬Łte aus┬Łge┬Łf├╝hrt ist. Ers┬Łte Miner-Her┬Łstel┬Łler haben bereits ange┬Łk├╝n┬Łdigt, es unter┬Łst├╝t┬Łzen zu wollen.

Smart Access Memory
Eigent┬Łlich ein Fea┬Łture, das die kom┬Łmen┬Łde Rade┬Łon RX 6000 (RDNA2) mit┬Łbringt. Aller┬Łdings ist f├╝r die Nut┬Łzung ein Chip┬Łsatz der 500er Serie und ein Ryzen 5000 n├Čtig. Damit kann der Pro┬Łzes┬Łsor auf den kom┬Łplet┬Łten Spei┬Łcher┬Łbe┬Łreich der Rade┬Łon-Gra┬Łfik┬Łkar┬Łte zugrei┬Łfen, was in eini┬Łgen Spie┬Łlen zus├żtz┬Łlich ein paar Pro┬Łzent Leis┬Łtung frei┬Łset┬Łzen soll.
