AMD pr├żsentiert die Zen-Architektur
Schon lan┬Łge hat es Tra┬Łdi┬Łti┬Łon, dass AMD par┬Łal┬Łlel zur statt┬Łfin┬Łden┬Łden Kon┬Łfe┬Łrenz des Mit┬Łbe┬Łwer┬Łbers Intel die Redak┬Łteu┬Łre in eige┬Łne Hotel┬Łhin┬Łter┬Łzim┬Łmer ent┬Łf├╝hrt, um dort eige┬Łne Wer┬Łke zu zei┬Łgen. Die┬Łses Jahr konn┬Łte AMDs CEO Lisa Su mit einem beson┬Łde┬Łren Bon┬Łbon auf┬Łwar┬Łten: Erst┬Łmals wur┬Łden lauf┬Łf├ż┬Łhi┬Łge Sys┬Łte┬Łme gezeigt, die auf AMDs nagel┬Łneu┬Łer Zen-Mikro┬Łar┬Łchi┬Łtek┬Łtur auf┬Łbau┬Łen. Anhand von Com┬Łpi┬Łler┬Łinfor┬Łma┬Łtio┬Łnen konn┬Łten wir bereits letz┬Łten Okto┬Łber das Grund┬Łde┬Łsign ver┬Ł├Čf┬Łfent┬Łli┬Łchen:
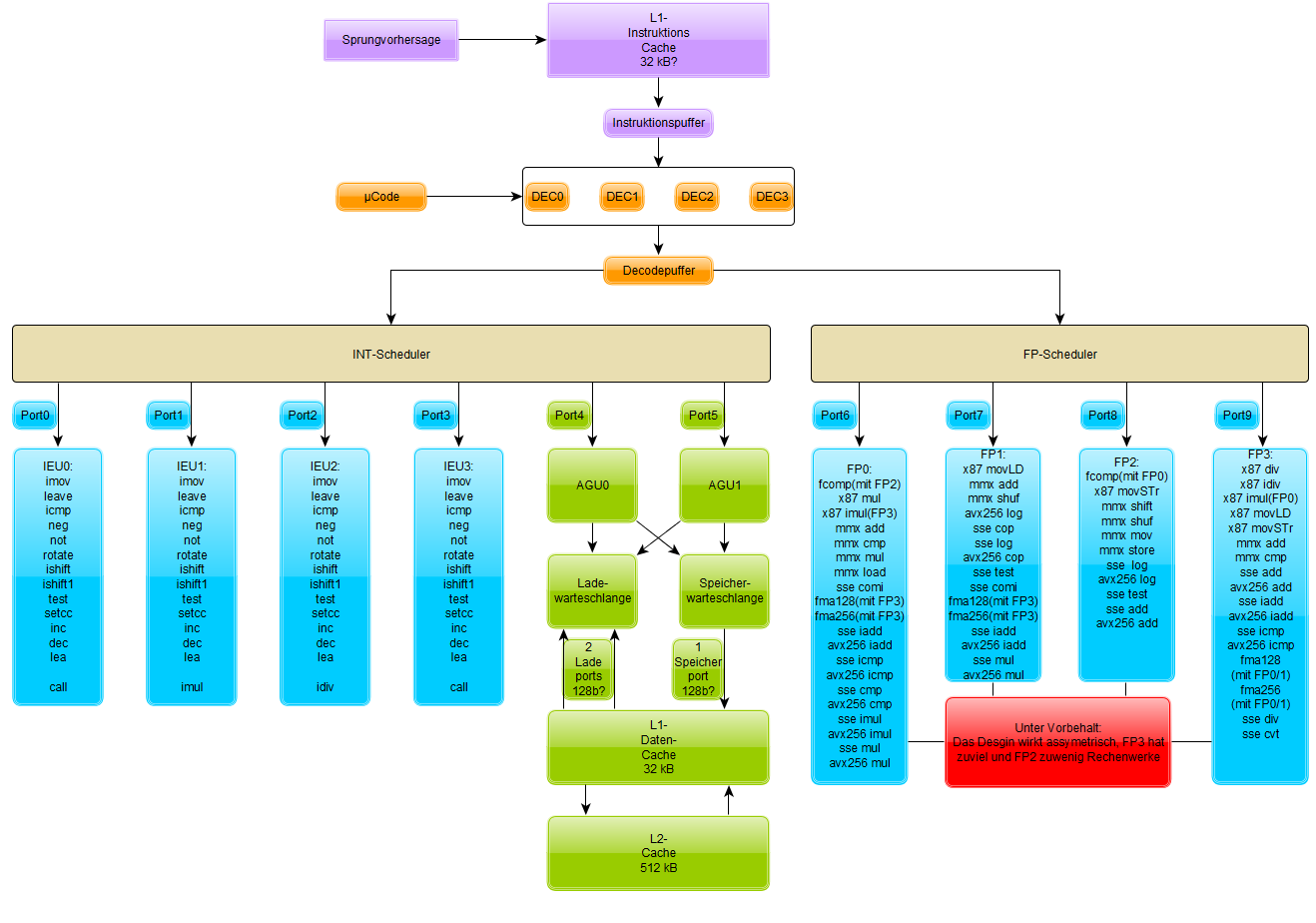
Dies erwies sich im Nach┬Łhin┬Łein als gute Inter┬Łpre┬Łta┬Łti┬Łon der Infor┬Łma┬Łtio┬Łnen aus dem damals neu┬Łen Code┬Łseg┬Łment, wenn man es mit AMDs offi┬Łzi┬Łel┬Łlem Archi┬Łtek┬Łtur┬Łsche┬Łma vergleicht:

Je vier Inte┬Łger- und FP-Ein┬Łhei┬Łten mit jeweils zwei ADD/┬ŁMUL-Units sowie zwei AGUs sind also gesi┬Łchert, womit es sich bei Zen um ein rela┬Łtiv brei┬Łtes Design mit vie┬Łlen Rechen┬Łein┬Łhei┬Łten han┬Łdelt ŌĆō sicher┬Łlich per┬Łfekt f├╝r den SMT-Einsatz.
Wir gehen im Fol┬Łgen┬Łden kurz auf die Unter┬Łschie┬Łde im Ver┬Łgleich zu Okto┬Łber ein:
- Zual┬Łler┬Łerst f├żllt der gr├Č┬Ł├¤e┬Łre L1-Befehls┬Łcache auf. Sind sich AMD und Intel bei der Daten┬Łcache┬Łgr├Č┬Ł├¤e noch einig und ver┬Łbau┬Łen 32 kB 8ŌĆæfach asso┬Łzia┬Łti┬Łven L1D-Cache, hat sich AMD beim Instruk┬Łti┬Łons┬Łcache f├╝r 64 kB ent┬Łschie┬Łden, wie es fr├╝┬Łher auch bei den K8- und K10-CPUs ├╝blich war. Aller┬Łdings wuchs die Asso┬Łzia┬Łti┬Łvi┬Łt├żt von 2ŌĆæfach auf 4ŌĆæfach an, wur┬Łde also besser.
- Bei den Inte┬Łger┬Łpipe┬Łlines zeich┬Łnet AMD jeweils eige┬Łne Sche┬Łdu┬Łler pro ALU/AGU ein, dies erin┬Łnert eben┬Łfalls etwas an die K8- und K10-Vor┬Łl├żu┬Łfer, ver┬Łrin┬Łgert aber stark die maxi┬Łma┬Łle Tie┬Łfe der Out-of-Order-Aus┬Łf├╝h┬Łrung. Aller┬Łdings ist zu ver┬Łmu┬Łten, dass AMD dank nomi┬Łnel┬Łler 14-nm-Pro┬Łzess┬Łtech┬Łnik jeden ein┬Łzel┬Łnen Sche┬Łdu┬Łler rela┬Łtiv gro├¤┬Łz├╝┬Łgig dimen┬Łsio┬Łnie┬Łren kann, so dass sich etwa┬Łige Nach┬Łtei┬Łle in Gren┬Łzen hal┬Łten k├Čnn┬Łten. Die Anga┬Łbe von 1,75-facher Gr├Č┬Ł├¤e im Ver┬Łgleich zu Excava┬Łtor hilft hier lei┬Łder nicht weiter.
- Wich┬Łtigs┬Łte Neue┬Łrung d├╝rf┬Łte der von Intel mit San┬Łdy-Bridge ein┬Łge┬Łf├╝hr┬Łte ┬ĄOp-Cache sein. Laut dem Sche┬Łma scheint die Funk┬Łtio┬Łna┬Łli┬Łt├żt ├żhn┬Łlich wie bei Intel zu sein, wo fer┬Łtig deko┬Łdier┬Łte Befeh┬Łle direkt an die Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten geschickt wer┬Łden k├Čn┬Łnen. Maxi┬Łmal k├Čn┬Łnen sechs ┬ĄOps auf die Rei┬Łse durch die Rechen┬Łwer┬Łke geschickt wer┬Łden, d.h. genau┬Łso vie┬Łle wie bei Intels aktu┬Łel┬Łler Sky┬Łla┬Łke-Archi┬Łtek┬Łtur. Intel erm├Čg┬Łlich┬Łte bis zur Has┬Łwell-Archi┬Łtek┬Łtur nur vier ┬ĄOps.
- Wei┬Łte┬Łre Punk┬Łte wie z.B. eine Stack-Engi┬Łne run┬Łden die Ein┬Łzel┬Łhei┬Łten ab, dies wur┬Łde zuerst im Blog von Mat┬Łthi┬Łas Wald┬Łhau┬Łer erw├żhnt.
Abschlie┬Ł├¤end noch eine ├£ber┬Łsicht zur Cache-Hier┬Łar┬Łchie, wel┬Łche eben┬Łfalls den Erwar┬Łtun┬Łgen entspricht:

Was ist nun das Resul┬Łtat aller Opti┬Łmie┬Łrun┬Łgen? Eine zu Intels Broad┬Łwell-Archi┬Łtek┬Łtur ver┬Łgleich┬Łba┬Łre Pro-Takt-Leis┬Łtung ŌĆö zumin┬Łdest bei Ver┬Łwen┬Łdung des Pro┬Łgramms Blender.
Das ist sicher┬Łlich mehr als man erwar┬Łten durf┬Łte, auch wenn nicht genau klar ist, wel┬Łche Befeh┬Łle Blen┬Łder ein┬Łsetzt und wel┬Łche nicht. Ver┬Łmut┬Łlich wer┬Łden kei┬Łne 256-Bit-Befeh┬Łle ver┬Łwen┬Łdet, dort h├żt┬Łte Intel n├żm┬Łlich noch einen star┬Łken Vor┬Łteil. Solan┬Łge AMD die neu┬Łen Zen-Chips aber preis┬Łlich attrak┬Łtiv gestal┬Łtet, wer┬Łden die Pro┬Łduk┬Łte sicher┬Łlich Zuspruch erfah┬Łren, schlie├¤┬Łlich ist AVX256-Code nur sel┬Łten anzu┬Łtref┬Łfen und als Ersatz ste┬Łhen zwei statt einer ADD/┬ŁMUL-Ein┬Łheit zur Verf├╝gung.
Vor der Pr├ż┬Łsen┬Łta┬Łti┬Łon ist bekannt┬Łlich nach der Pr├ż┬Łsen┬Łta┬Łti┬Łon und so wag┬Łte AMD auch schon einen Blick in die Zeit nach der ers┬Łten Zen-Ite┬Łra┬Łti┬Łon, f├╝r die wei┬Łte┬Łre Stei┬Łge┬Łrun┬Łgen ver┬Łspro┬Łchen wurden:

Wei┬Łte┬Łre Details zur Zen-Archi┬Łtek┬Łtur wer┬Łden n├żchs┬Łten Diens┬Łtag auf der Hot┬Łchips-Kon┬Łfe┬Łrenz erwar┬Łtet, wor┬Ł├╝ber wir eben┬Łfalls berich┬Łten werden.
Links zum Thema:
- AMD Zen mit DDR4-Tech┬Łno┬Łlo┬Łgie von Ram┬Łbus? ()
- Ers┬Łte Details zu AMDs Zen-Pro┬Łzes┬Łso┬Łren ()
- Ger├╝cht: Zen-APUs mit 4 Ker┬Łnen, L3-Cache und bis zu 11 Pola┬Łris-CUs? ()
- Sockel AM4 doch nicht mit abw├żrts┬Łkom┬Łpa┬Łti┬Łbler K├╝h┬Łler┬Łhal┬Łte┬Łrung? ()
- Sockel AM4 mit abw├żrts┬Łkom┬Łpa┬Łti┬Łbler K├╝h┬Łler┬Łbe┬Łfes┬Łti┬Łgung? ()
- Neu┬Łer Com┬Łpi┬Łler GCC 6 mit HSA- und Zen-Sup┬Łport ()
- Ana┬Łly┬Łse der ver┬Łmu┬Łte┬Łten Zen-Archi┬Łtek┬Łtur ()