Analyse der vermuteten Zen-Architektur
Schon im M├żrz wuss┬Łten wir ├╝ber ein ers┬Łtes Code┬Łfrag┬Łment zu AMDs kom┬Łmen┬Łder Zen-Archi┬Łtek┬Łtur zu berich┬Łten. Erst┬Łmals wur┬Łde hier der Befehls┬Łsatz ange┬Łge┬Łben, der alle moder┬Łnen Erwei┬Łte┬Łrun┬Łgen bis AVX2 und FMA umfasst. Unser Foren┬Łmit┬Łglied Dres┬Łden┬Łboy hat in sei┬Łnem eng┬Łlisch┬Łspra┬Łchi┬Łgen Blog nun ├╝ber wei┬Łte┬Łre Details berich┬Łtet und ein Block┬Łschalt┬Łbild ent┬Łwor┬Łfen, wel┬Łches Zen nach aktu┬Łel┬Łlem Wis┬Łsens┬Łstand, gew├╝rzt mit eini┬Łgen Ver┬Łmu┬Łtun┬Łgen, zei┬Łgen k├Čnn┬Łte. Auf des┬Łsen Basis haben wir eine detail┬Łlier┬Łte Dar┬Łstel┬Łlung erstellt und zie┬Łhen einen Ver┬Łgleich mit Skylake:
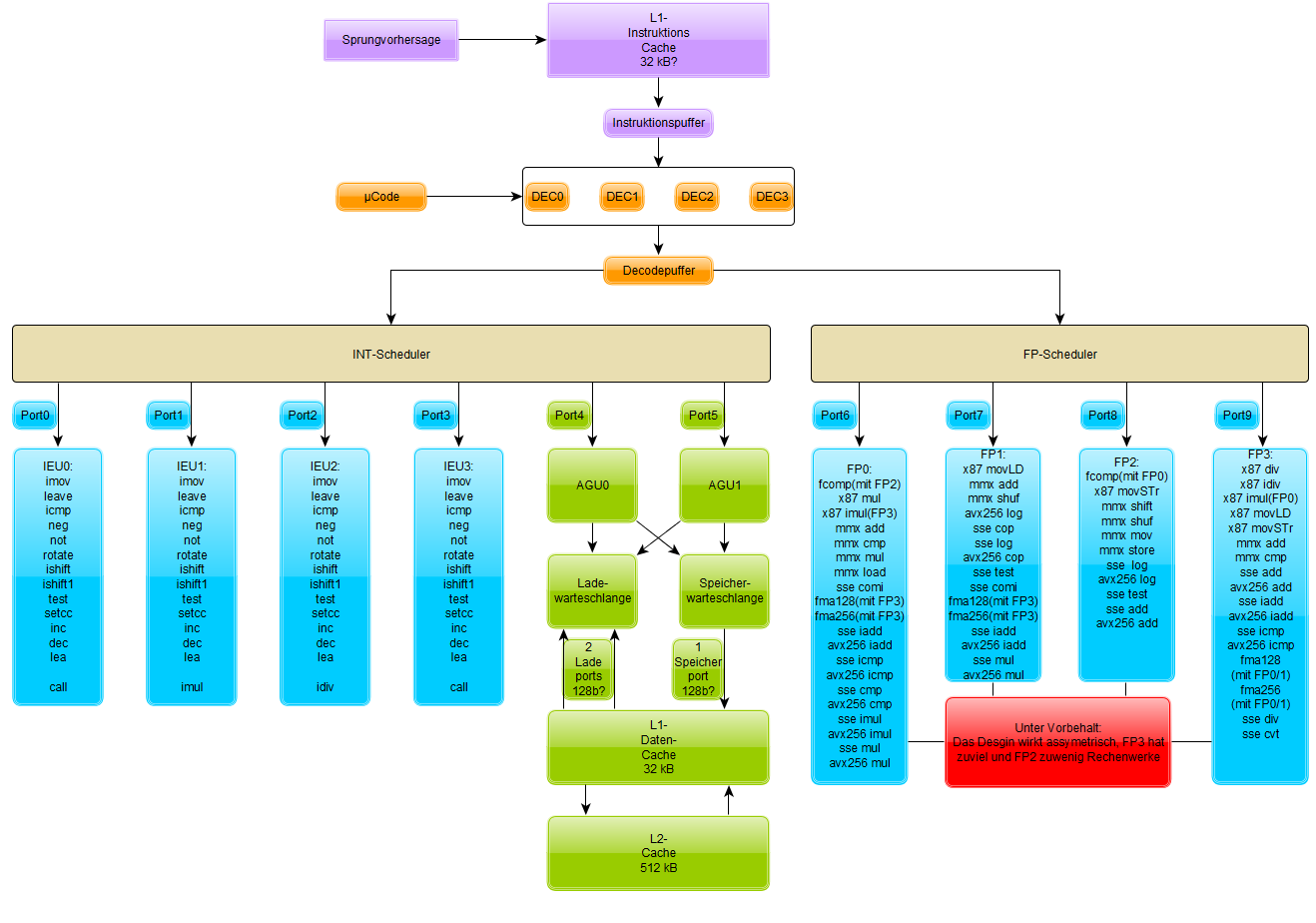
Fehl┬Łdar┬Łstel┬Łlun┬Łgen auf┬Łgrund von Copy-Pas┬Łte-Feh┬Łlern im Code sind m├Čglich!
Archi┬Łtek┬Łtur┬Łbe┬Łschrei┬Łbung
Auf┬Łfal┬Łlend ist erst ein┬Łmal die Brei┬Łte des Designs. Mit 10 Ports, von denen 8 direkt zu Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten (blau) f├╝h┬Łren, setzt man ein deut┬Łli┬Łches Zei┬Łchen. ├älte┬Łre Semes┬Łter wer┬Łden sich viel┬Łleicht an Alphas EV8 erin┬Łnern, der ers┬Łten CPU-Archi┬Łtek┬Łtur, f├╝r die SMT imple┬Łmen┬Łtiert wer┬Łden soll┬Łte. Aus dem Chip wur┬Łde am Ende zwar nichts, aber das noch brei┬Łte┬Łre EV8-Design, bestehend aus 8 INT-Pipes, 4 AGUs und 4 FPU-Pipes, zeigt, dass f├╝r SMT vie┬Łle Aus┬Łf├╝h┬Łrungs┬Łports kein Hin┬Łder┬Łnis, son┬Łdern im Gegen┬Łteil ide┬Łal sind. Aus die┬Łsem Grund soll┬Łte auch AMDs Zen (sehr) gut mit zwei┬Łfa┬Łchem SMT ska┬Łlie┬Łren, da die Wahr┬Łschein┬Łlich┬Łkeit, dass sich zwei Threads einen Port strei┬Łtig machen, sinkt, je brei┬Łter das Design aus┬Łge┬Łf├╝hrt wird. Eigent┬Łlich ist es bis auf sel┬Łte┬Łne Spe┬Łzi┬Łal┬Łf├żl┬Łle fast unm├Čg┬Łlich, da die h├żu┬Łfig genutz┬Łten Ein┬Łhei┬Łten wie Addie┬Łrer und Mul┬Łti┬Łpli┬Łzie┬Łrer (jeweils f├╝r INT und Floats) dop┬Łpelt zur Ver┬Łf├╝┬Łgung ste┬Łhen und an ver┬Łschie┬Łde┬Łnen Ports h├żn┬Łgen. Intel hat im Ver┬Łgleich nur 4 Ports ins┬Łge┬Łsamt, an wel┬Łchen sowohl alle INT- als auch alle FP-Ein┬Łhei┬Łten h├żn┬Łgen, was die Ver┬Łtei┬Łlung der Instruk┬Łtio┬Łnen ein┬Łschr├żnkt. Aller┬Łdings kann man mit SMT immer┬Łhin Pro┬Łfit aus den immer vor┬Łhan┬Łde┬Łnen Cache- und Spei┬Łcher┬Łla┬Łten┬Łzen zie┬Łhen. Wenn ein Thread auf Daten war┬Łten muss, hat der ande┬Łre schlie├¤┬Łlich auto┬Łma┬Łtisch alle Ports zur Verf├╝gung.
Doch wo bei Zen Licht ist, ist nat├╝r┬Łlich auch Schat┬Łten. Intels enges Port-Design und der gemein┬Łsa┬Łme INT+FP-Scheduler erm├Čg┬Łlich┬Łten z.B., dass die FP-Ein┬Łheit die Daten┬Łlei┬Łtun┬Łgen zum Cache der am sel┬Łben Port h├żn┬Łgen┬Łden INT-Ein┬Łheit (und umge┬Łkehrt) ver┬Łwen┬Łden kann. Schlie├¤┬Łlich kann im sel┬Łben Takt kein Befehl an die jeweils ande┬Łre Aus┬Łf├╝h┬Łrungs┬Łein┬Łheit erfol┬Łgen. Bei AMD ist das nicht der Fall, d.h. dass AMD f├╝r vol┬Łle 256 Bit zum Cache den dop┬Łpel┬Łten Auf┬Łwand h├żt┬Łte, qua┬Łsi 512 Lei┬Łtun┬Łgen ver┬Łle┬Łgen m├╝ss┬Łte. Das scheint AMD im Moment noch zu viel zu sein. 256-Bit-x86-Befeh┬Łle wer┬Łden wie ├╝blich in soge┬Łnann┬Łte Dou┬Łbles deco┬Łdiert, d.h. sie wer┬Łden in 2 Sub┬Łin┬Łstruk┬Łtio┬Łnen (Macro┬ŁOps) zer┬Łlegt, was logi┬Łscher┬Łwei┬Łse 128-Bit-Instruk┬Łtio┬Łnen sein m├╝s┬Łsen. Aus dem Grund kann man dann das ├╝bli┬Łche AMD-Cache┬Łde┬Łsign erwar┬Łten: dual-por┬Łted mit 128 Bit f├╝r Lese┬Łope┬Łra┬Łtio┬Łnen, ein┬Łfach f├╝r Schrei┬Łb┬Łope┬Łra┬Łtio┬Łnen (gr├╝n). Die Adres┬Łsen wer┬Łden dabei von zwei Adress┬Łge┬Łnerie┬Łrungs-Units (AGUs) berechnet.
Links zum Thema:
- Ers┬Łte Anzei┬Łchen f├╝r 2016 kom┬Łmen┬Łde AMD-APUs im BIOS-Update ent┬Łdeckt ()
- Jim Kel┬Łler ver┬Łl├żsst AMD aber┬Łmals ()
- AMD Piledri┬Łver vs. Steam┬Łrol┬Łler vs. Excava┬Łtor ŌĆö Leis┬Łtungs┬Łver┬Łgleich der Archi┬Łtek┬Łtu┬Łren ()
- AMDs Zen-Archi┬Łtek┬Łtur zeigt sich in Com┬Łpi┬Łler-Quell┬Łcode ()
- Der geso┬Łckel┬Łte Kabi┬Łni ŌĆö Ath┬Łlon 5350 im Test ()