Analyse der vermuteten Zen-Architektur
Vergleich mit Intels Skylake
Zu Intels Sky┬Łla┬Łke gab es vor Kur┬Łzem erst neue Daten samt einem Archi┬Łtek┬Łtur┬Łsche┬Łma, das wir ger┬Łne wiedergeben:
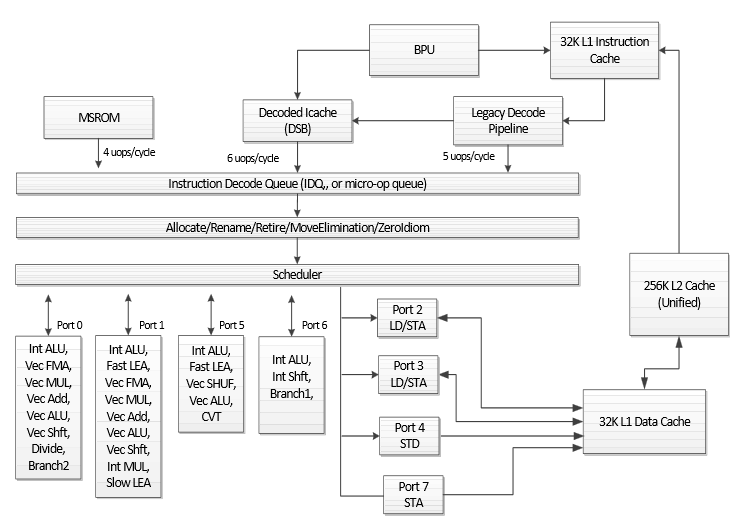
Neben der fort┬Łbe┬Łstehen┬Łden Schmal┬Łheit des Design, das von Intel in den letz┬Łten Jah┬Łren schon nach und nach ver┬Łbrei┬Łtert wur┬Łde ŌĆō anhand der Port┬Łnum┬Łmern kann man z.B. erken┬Łnen, dass Port 5 (Pen┬Łryn), 6 (Has┬Łwell) und 7 (Sky┬Łla┬Łke) erst nach┬Łtr├żg┬Łlich ins Design auf┬Łge┬Łnom┬Łmen wur┬Łden ŌĆō fal┬Łlen v.a. eini┬Łge Ver┬Łschlech┬Łte┬Łrun┬Łgen auf. So ver┬Łschlech┬Łter┬Łten sich L2- und L3-Laten┬Łzen, au├¤er┬Łdem redu┬Łzier┬Łte Intel die L2-Asso┬Łzia┬Łti┬Łvi┬Łt├żt von acht┬Łfach auf vier┬Łfach, wodurch die Tref┬Łfer┬Łra┬Łte sank. Das ├╝ber┬Łrascht schon, denn bis┬Łher ging es immer in die ande┬Łre Rich┬Łtung. Intel gab zur L2-Asso┬Łzia┬Łti┬Łvi┬Łt├żt an, dies aus Ener┬Łgie┬Łspar┬Łgr├╝n┬Łden ge├żn┬Łdert zu haben. Trotz der ange┬Łspro┬Łche┬Łnen Nach┬Łtei┬Łle steigt die Leis┬Łtung gegen┬Ł├╝ber der Vor┬Łg├żn┬Łger┬Łge┬Łne┬Łra┬Łti┬Łon wei┬Łter an, denn nat├╝r┬Łlich gab es auch Ver┬Łbes┬Łse┬Łrun┬Łgen, vor┬Łnehm┬Łlich wur┬Łden die inter┬Łnen Puf┬Łfer vergr├Č├¤ert:
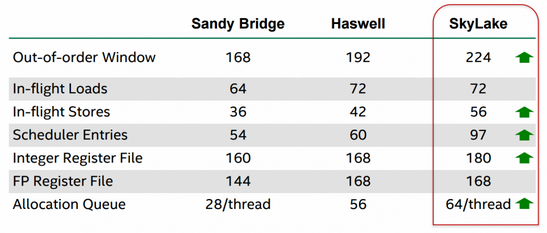
Wie man hier sieht, wur┬Łde dann doch nicht gekle┬Łckert, son┬Łdern wei┬Łter┬Łhin geklotzt. Ins┬Łbe┬Łson┬Łde┬Łre die Ver┬Łgr├Č┬Ł├¤e┬Łrung der Allo┬Łca┬Łti┬Łon-War┬Łte┬Łschlan┬Łge f├żllt auf. Hat┬Łte San┬Łdy Bridge noch 28 Ein┬Łtr├ż┬Łge pro Thread und Has┬Łwell eine gleich gro┬Ł├¤e War┬Łte┬Łschlan┬Łge f├╝r alle zwei Threads, besitzt Sky┬Łla┬Łke nun wie┬Łder getrenn┬Łte Ein┬Łtr├ż┬Łge pro Thread und zwar gleich 64. Ins┬Łge┬Łsamt wur┬Łde die Kapa┬Łzi┬Łt├żt damit mehr als ver┬Łdop┬Łpelt. Bef├╝llt wer┬Łden die┬Łse War┬Łte┬Łschlan┬Łgen vom Front┬Łend, wobei von Intels ┬ĄOp-Cache nun 6 Ope┬Łra┬Łtio┬Łnen pro Takt kom┬Łmen k├Čn┬Łnen. Eben┬Łfalls ├╝ber┬Łpro┬Łpor┬Łtio┬Łnal bedacht wur┬Łden die Sche┬Łdu┬Łler-Ein┬Łtr├ż┬Łge, die um mehr als die H├żlf┬Łte von 60 auf 97 zuleg┬Łten. Es zeigt sich also, dass man am Cache┬Łsys┬Łtem durch┬Łaus spa┬Łren kann ŌĆö wenn man die Daten┬Łzu┬Łgrif┬Łfe schon intern durch aus┬Łrei┬Łchend dimen┬Łsio┬Łnier┬Łte War┬Łte┬Łschlan┬Łgen abfe┬Łdern kann. Der Grund, aus dem man nicht von Beginn an so gro┬Ł├¤e Puf┬Łfer vor┬Łsah, ist nat├╝r┬Łlich der Her┬Łstel┬Łlungs┬Łpro┬Łzess. Neue, klei┬Łne┬Łre Struk┬Łtu┬Łren ver┬Łgr├Č┬Ł├¤ern das Tran┬Łsis┬Łto┬Łren┬Łbud┬Łget der CPU-Archi┬Łtek┬Łten und gro┬Ł├¤e Puf┬Łfer sind dann eine gute Anlage.
Ent┬Łfernt erin┬Łnert die Vor┬Łge┬Łhens┬Łwei┬Łse an Excava┬Łtors Cache┬Łde┬Łsign. Dort erm├Čg┬Łlich┬Łte der ver┬Łgr├Č┬Ł├¤er┬Łte L1-Cache einen klei┬Łne┬Łren L2-Cache ohne Performance-Einbu├¤en.