Analyse der vermuteten Zen-Architektur
INT- und FP-Rechenwerke
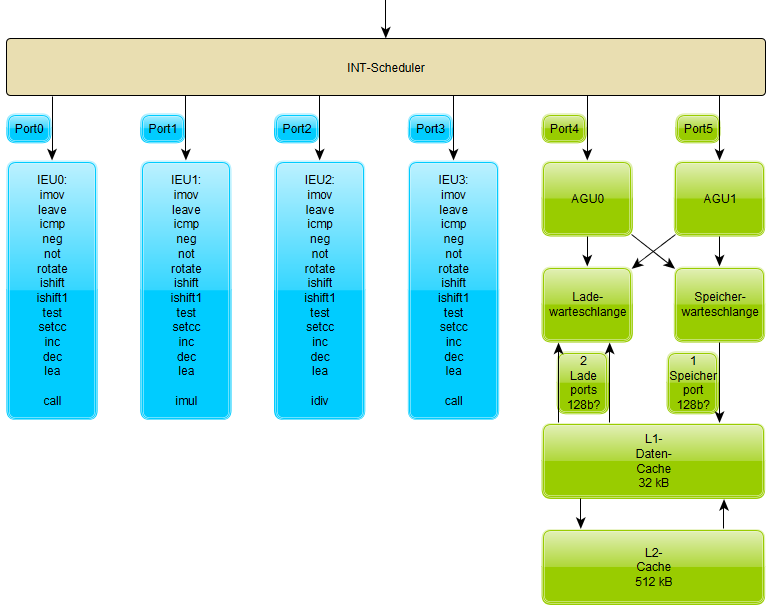
Die INT-Rechen┬Łwer┬Łke beschr├żn┬Łken sich auf das ├£bli┬Łche: Alle vier ALUs k├Čn┬Łnen die Stan┬Łdard┬Łbe┬Łfeh┬Łle abar┬Łbei┬Łten, die drit┬Łte Inte┬Łger Exe┬Łcu┬Łti┬Łon Unit (IEU2) ver┬Łf├╝gt ├╝ber eine Inte┬Łger┬Łdi┬Łvi┬Łsi┬Łons- und IEU1 ├╝ber eine Inte┬Łger┬Łmul┬Łti┬Łpli┬Łka┬Łti┬Łons-Ein┬Łheit, IEU0 und IEU3 k├Čn┬Łnen auch noch Call-Befeh┬Łle abar┬Łbei┬Łten. Erw├żh┬Łnens┬Łwert ist, dass die bei Bull┬Łdo┬Łzer ver┬Łwen┬Łde┬Łten AGLUs kei┬Łne Erw├żh┬Łnung mehr fin┬Łden, die dort abge┬Łar┬Łbei┬Łte┬Łte LEA-Instruk┬Łti┬Łon wird in den nor┬Łma┬Łlen ALUs berechnet:
Bei den FP-Ein┬Łhei┬Łten ist die Sache etwas weni┬Łger ├╝ber┬Łsicht┬Łlich. Grob kann man eine Zwei┬Łtei┬Łlung erken┬Łnen, die ers┬Łten bei┬Łden Ein┬Łhei┬Łten FP0 und FP1 arbei┬Łten Vec┬Łtor-Mul┬Łti┬Łpli┬Łka┬Łtio┬Łnen (SSE/AVX) und MMX-Addi┬Łtio┬Łnen ab, w├żh┬Łrend FP2 und FP3 f├╝r Vec┬Łtor-Addi┬Łtio┬Łnen zust├żn┬Łdig sind. FP3 ver┬Łf├╝gt au├¤er┬Łdem ├╝ber eine Divi┬Łsi┬Łons┬Łein┬Łheit, alte x87-Instruk┬Łtio┬Łnen wer┬Łden an FP0 und FP3 geschickt; FP1 und FP2 sind die Kan┬Łdi┬Łda┬Łten f├╝r logi┬Łsche Berech┬Łnun┬Łgen mit AVX. Zwar gibt es auch eine FMA-F├żhig┬Łkeit, aller┬Łdings die┬Łse wird ŌĆö wie die bereits erw├żhn┬Łten 256-Bit-Befeh┬Łle ŌĆö nur mit Dou┬Łbles imple┬Łmen┬Łtiert. Bei FMA arbei┬Łtet die Add-Ein┬Łheit FP3 ent┬Łwe┬Łder mit den Mul┬Łti┬Łpli┬Łka┬Łtor┬Łre┬Łchen┬Łwer┬Łken an FP1 oder FP2 zusam┬Łmen. Wie┬Łso die Adder von FP2 nicht ber├╝ck┬Łsich┬Łtigt wer┬Łden, ist im ers┬Łten Moment unklar. Dres┬Łden┬Łboy fie┬Łlen auf den zwei┬Łten Blick hin┬Łge┬Łgen die War┬Łte┬Łzy┬Łklen der bei┬Łden Mul┬Łti┬Łpli┬Łka┬Łtor┬Łein┬Łhei┬Łten auf. Laut den Ein┬Łtr├ż┬Łgen in besag┬Łtem Code┬Łfrag┬Łment k├Čn┬Łnen die┬Łse nur alle f├╝nf Tak┬Łte Befeh┬Łle ent┬Łge┬Łgen┬Łneh┬Łmen. Ein ein┬Łzel┬Łner Adder w├żre rech┬Łne┬Łrisch also genug, um im Schnitt alle 2,5 Tak┬Łte ein Add-Ergeb┬Łnis zur FMA-Berech┬Łnung zur Ver┬Łf├╝┬Łgung zu stellen:
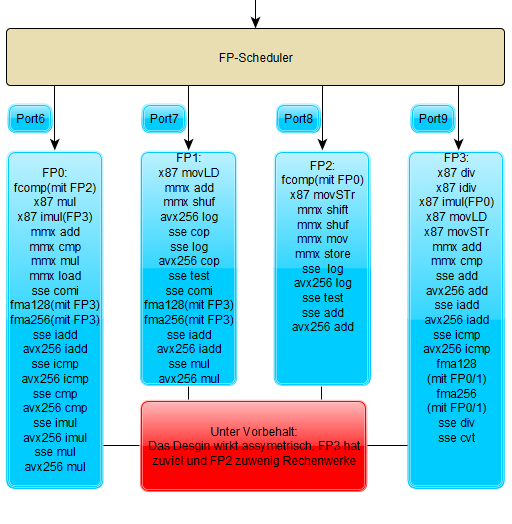
Soll┬Łte sich die┬Łser Umstand bewahr┬Łhei┬Łten, kann man gleich┬Łwohl auch wei┬Łte┬Łre Schluss┬Łfol┬Łge┬Łrun┬Łgen zie┬Łhen: Seit dem K7 waren AMDs FPUs immer ŌĆ£ful┬Łly pipe┬ŁlinedŌĆØ, d.h. sie konn┬Łten die Befeh┬Łle wie am Flie├¤┬Łband abar┬Łbei┬Łten, mit┬Łun┬Łter also jeden Takt Befeh┬Łle ent┬Łge┬Łgen┬Łneh┬Łmen. Nur die klei┬Łne Mul┬Łti┬Łpli┬Łka┬Łti┬Łons┬Łein┬Łheit der Puma-Ker┬Łne war nicht ŌĆ£ful┬Łly pipe┬ŁlinedŌĆØ. Der Code k├Čnn┬Łte also ein Indiz daf├╝r sein, dass sich AMD im Fal┬Łle von Zens Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten im Cat-Regal bedient hat. Wie schwer die┬Łser Umstand aus Leis┬Łtungs┬Łsicht ins Gewicht fal┬Łlen wird, bleibt abzu┬Łwar┬Łten. Immer┬Łhin gibt es je zwei Ein┬Łhei┬Łten statt nur einer, au├¤er┬Łdem wird AMD sicher┬Łlich die umlie┬Łgen┬Łden Puf┬Łfer, Caches, etc. opti┬Łmie┬Łren, um die Ein┬Łhei┬Łten bes┬Łser aus┬Łlas┬Łten zu k├Čn┬Łnen. Solan┬Łge man den Kern nicht mit SMT belas┬Łtet, k├Čnn┬Łte das also durch┬Łaus in einer guten IPC resultieren.
Ins┬Łge┬Łsamt f├żllt am Design der FPU auf, dass die Ein┬Łheit ŌĆ£FP2ŌĆØ eher schwach mit Aus┬Łf├╝h┬Łrungs┬Łein┬Łhei┬Łten aus┬Łge┬Łstat┬Łtet ist, w├żh┬Łrend FP3 eher zu vie┬Łle hat. Even┬Łtu┬Łell liegt hier noch ein Feh┬Łler im Code vor, z.B. w├żre die FMA-F├żhig┬Łkeit eher bei FP2 sinn┬Łvoll, um alle Ports aus┬Łba┬Łlan┬Łciert zu halten.