Details zu AMDs heterogener Verarbeitungsschlange
Die┬Łse Woche gab AMD Details zur Pro┬Łgramm┬Łab┬Łar┬Łbei┬Łtung auf HSA-f├żhi┬Łgen Pro┬Łzes┬Łso┬Łren bzw. APUs bekannt, zus├żtz┬Łlich beant┬Łwor┬Łte┬Łte uns AMD noch Detail┬Łfra┬Łgen dazu. Das beschrie┬Łbe┬Łne Kon┬Łzept h├Črt im Eng┬Łli┬Łschen auf den Namen ŌĆ£hete┬Łro┬Łge┬Łneous Queu┬ŁingŌĆØ, abge┬Łk├╝rzt: ŌĆ£hQŌĆØ.
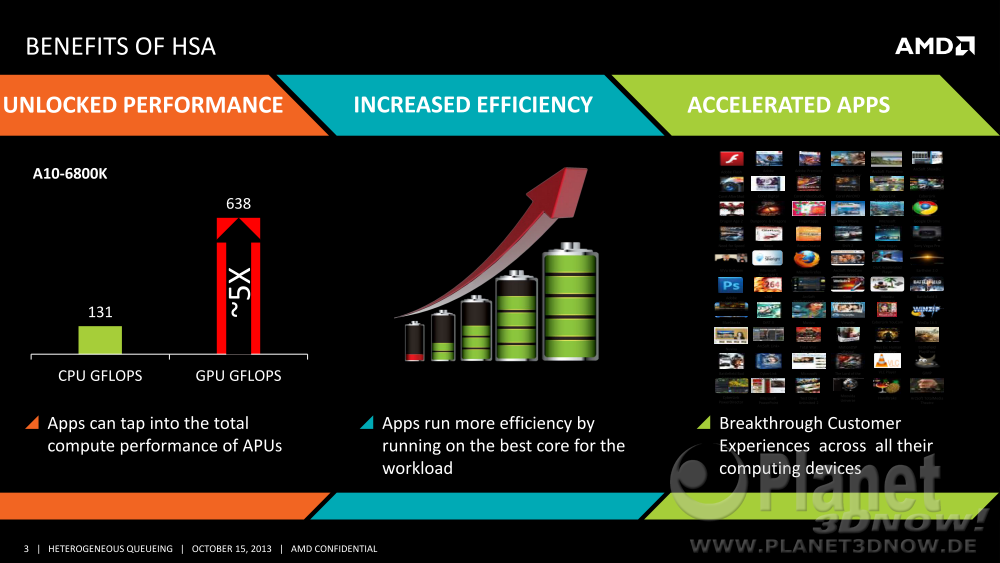
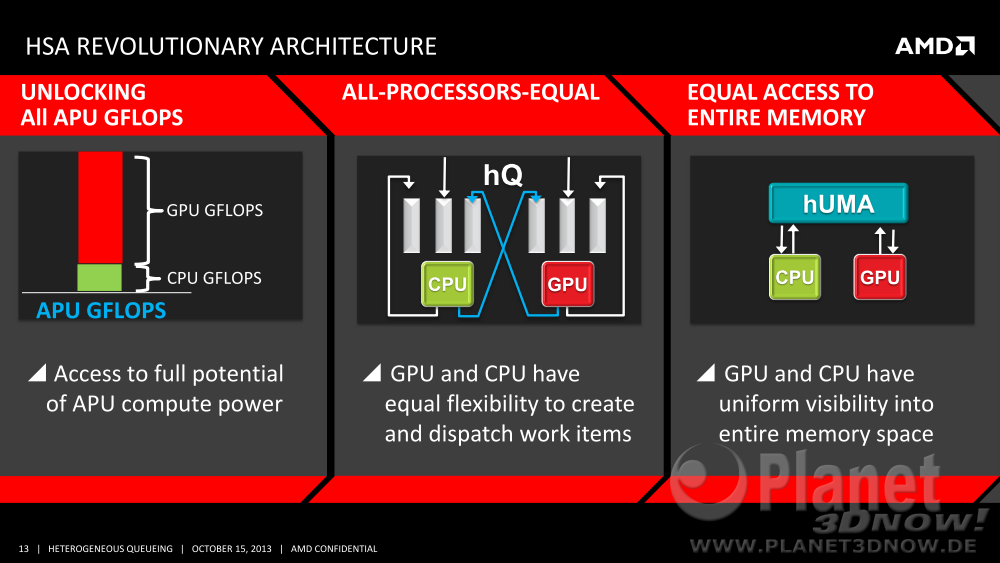
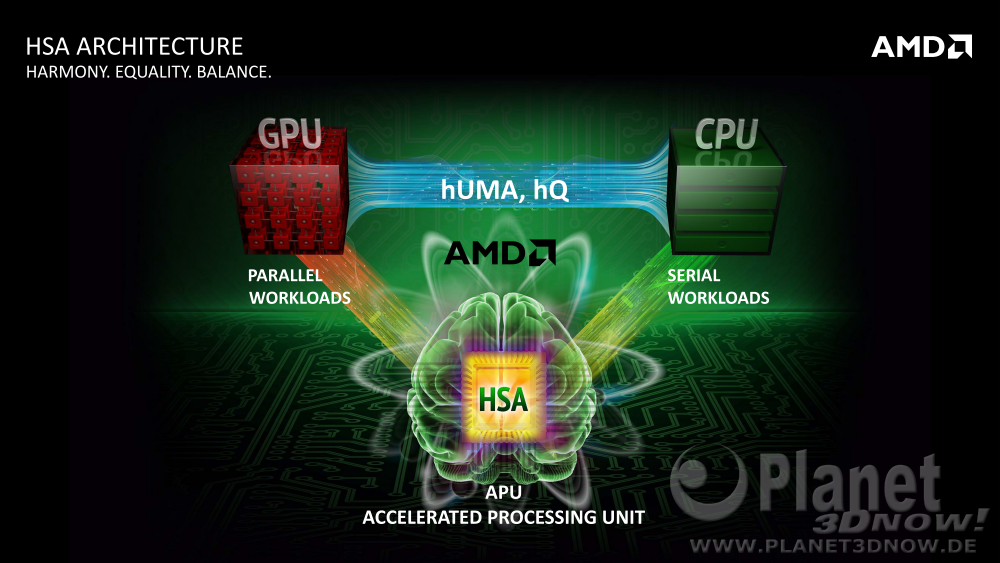
Wie schon bei AMDs Spei┬Łcher┬Łtech┬Łnik hUMA ist ŌĆ£hete┬Łro┬ŁgenŌĆØ schnell erkl├żrt. Bei hUMA bedeu┬Łtet es schlicht, dass unter┬Łschied┬Łli┬Łche Pro┬Łzes┬Łsor┬Łker┬Łne auf einen gemein┬Łsa┬Łmen Spei┬Łcher ├╝ber glei┬Łche Spei┬Łcher┬Ładres┬Łsen zugrei┬Łfen k├Čn┬Łnen. Im Zusam┬Łmen┬Łspiel mit einer Ver┬Łar┬Łbei┬Łtungs┬Łschlan┬Łge bedeu┬Łtet es nun, dass sich die glei┬Łchen unter┬Łschied┬Łli┬Łchen Pro┬Łzes┬Łsor┬Łker┬Łne nun gegen┬Łsei┬Łtig Arbeit zuschi┬Łcken k├Čnnen:

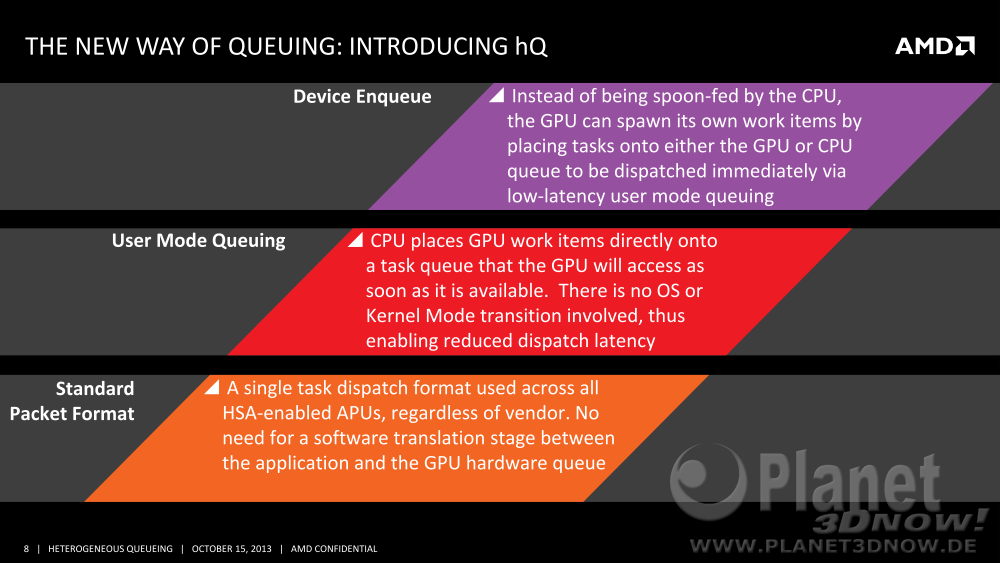
hUMA und hQ sind sich also kon┬Łzep┬Łtio┬Łnell ├żhn┬Łlich, aber im Ver┬Łgleich zum Spei┬Łcher gibt es kei┬Łne gemein┬Łsa┬Łme Schlan┬Łge, son┬Łdern min┬Łdes┬Łtens zwei, eine f├╝r die CPU sowie eine f├╝r die GPU:

Die┬Łse bei┬Łden War┬Łte┬Łschlan┬Łgen wer┬Łden von der jewei┬Łli┬Łgen Rechen┬Łein┬Łheit regel┬Łm├ż┬Ł├¤ig auto┬Łma┬Łtisch abge┬Łfragt und even┬Łtu┬Łell gefun┬Łde┬Łne Rechen┬Łpa┬Łke┬Łte dadurch z├╝gig abge┬Łar┬Łbei┬Łtet. Die Pake┬Łte lie┬Łgen im Haupt┬Łspei┬Łcher, wobei ein soge┬Łnann┬Łtes hQ-Paket aber kei┬Łnen aus┬Łzu┬Łf├╝h┬Łren┬Łden Code selbst ent┬Łh├żlt, son┬Łdern nur einen Zei┬Łger auf diesen.
Dadurch, dass die hQ-Pake┬Łte im Haupt┬Łspei┬Łcher lie┬Łgen, k├Čnn┬Łte man nun anneh┬Łmen, dass die Kom┬Łmu┬Łni┬Łka┬Łti┬Łon zwi┬Łschen CPU und GPU stark von der rela┬Łtiv hohen RAM-Latenz behin┬Łdert wird. Jedoch ver┬Łsi┬Łcher┬Łte uns AMD auf Nach┬Łfra┬Łge, dass die Spei┬Łcher┬Łstel┬Łlen der hQ-Pake┬Łte voll cache-f├żhig sei┬Łen, es auch kei┬Łne Koh├ż┬Łrenz┬Łpro┬Łble┬Łme zwi┬Łschen CPU und GPU g├żbe und somit kei┬Łne Per┬Łfor┬Łmance-Pro┬Łble┬Łme entst├╝nden.
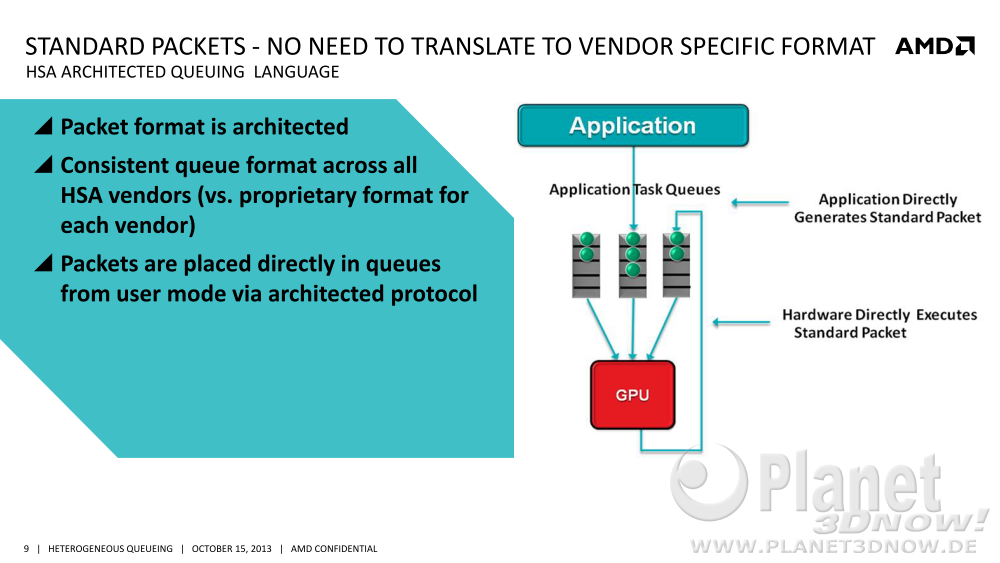
Neu ist das beschrie┬Łbe┬Łne Paket┬Łfor┬Łmat nicht ganz. Im bereits seit L├żn┬Łge┬Łrem ├Čffent┬Łlich erh├żlt┬Łli┬Łchen HSA-PDF wer┬Łden schon soge┬Łnann┬Łte AQL-Pake┬Łte (Archi┬Łtec┬Łted Queu┬Łing Lan┬Łguage) beschrie┬Łben. AMD best├ż┬Łtig┬Łte uns, dass die hQ-Pak┬Łte eng mit die┬Łsen ver┬Łwandt sei┬Łen und sie voll unter┬Łst├╝t┬Łzen. Alle bis┬Łher gezeig┬Łten Funk┬Łti┬Łons┬Łbe┬Łschrei┬Łbun┬Łgen wer┬Łden auch von den AQL-Pake┬Łten erf├╝llt, jedoch w├╝r┬Łden die hQ-Pake┬Łte noch AMD-spe┬Łzi┬Łfi┬Łsche Fea┬Łtures, die ├╝ber den stan┬Łdar┬Łdi┬Łsier┬Łten Rah┬Łmen hin┬Łaus gin┬Łgen, unter┬Łst├╝t┬Łzen. Die AQL-Pake┬Łte sind fol┬Łgen┬Łder┬Łma┬Ł├¤en spezifiziert:
An AQL packet is an HSA-stan┬Łdard packet for┬Łmat. AQL dis┬Łpatch packets are used to dis┬Łpatch new ker┬Łnels on the HSA com┬Łpo┬Łnent and spe┬Łci┬Łfy the launch dimen┬Łsi┬Łons, ins┬Łtruc┬Łtion code, ker┬Łnel argu┬Łments, com┬Łple┬Łti┬Łon detec┬Łtion, and more. Other AQL packets may also be sup┬Łport┬Łed in the future.
Dadurch, dass sich die GPU ├╝ber hQs die Arbeit selbst holen kann, besteht ein Vor┬Łteil gegen┬Ł├╝ber der aktu┬Łel┬Łlen bzw. bald ver┬Łal┬Łte┬Łten Tech┬Łnik, bei der die CPU Berech┬Łnun┬Łgen h├żn┬Łdisch und rela┬Łtiv kom┬Łpli┬Łziert ├╝ber Betriebs┬Łsys┬Łtem┬Łschnitt┬Łstel┬Łlen und Ker┬Łnel┬Łtrei┬Łber an die GPU sen┬Łden muss. Die┬Łser alte Umweg ist im fol┬Łgen┬Łden Bild sche┬Łma┬Łtisch dargestellt:

Zum Schluss wol┬Łlen wir noch auf den Umstand hin┬Łwei┬Łsen, dass es nicht nur zwei Schlan┬Łgen gibt. Jede Appli┬Łka┬Łti┬Łon kann ihre eige┬Łne Schlan┬Łge benut┬Łzen, wobei es aber eine gewis┬Łse Ober┬Łgren┬Łze bei ca. 30 St├╝ck gibt:

Man darf also gespannt auf die Ver┬Łbes┬Łse┬Łrung sein, die HSA mit sich bringt, allein es fehlt noch an der Hard┬Łware. AMD wird hof┬Łfent┬Łlich bald nach┬Łle┬Łgen und auf der kom┬Łmen┬Łden APU13-Mes┬Łse nicht nur Foli┬Łen son┬Łdern auch Sili┬Łzi┬Łum zeigen.
Alle Foli┬Łen gibt es in unse┬Łrer Slideshow:











Abschlie┬Ł├¤end m├Čch┬Łten wir uns bei AMD f├╝r die Beant┬Łwor┬Łtung unse┬Łrer Fra┬Łgen bedanken.
Quel┬Łle:
Stan┬Łdards ŌĆö HSA Foun┬Łda┬Łti┬Łon.