AMD pr├żsentiert HSA-Details auf der Hot Chips 25 [Update]
Auf der gera┬Łde statt┬Łfin┬Łden┬Łden Hot-Chips-Kon┬Łfe┬Łrenz hat AMD in Zusam┬Łmen┬Łar┬Łbeit mit den HSA-Part┬Łnern Qual┬Łcomm und ARM Details zur ihrer gemein┬Łsa┬Łmen hete┬Łro┬Łge┬Łnen Sys┬Łtem┬Łar┬Łchi┬Łtek┬Łtur (HSA) preis┬Łge┬Łge┬Łben. Die Grund┬Łla┬Łgen von HSA sind schon seit deren Gr├╝n┬Łdung 2012 bekannt, ein Eck┬Łpfei┬Łler der Archi┬Łtek┬Łtur ist u.a. die Unter┬Łst├╝t┬Łzung von gemein┬Łsam benutz┬Łtem, hete┬Łro┬Łge┬Łnen Sys┬Łtem┬Łspei┬Łcher, der unter dem Schlag┬Łwort hUMA bewor┬Łben wird. Aktu┬Łell ist der Begriff auf┬Łgrund der even┬Łtu┬Łel┬Łlen hUMA-Unter┬Łst├╝t┬Łzung der PS4 im Gespr├żch. In der Pr├ż┬Łsen┬Łta┬Łti┬Łon wur┬Łde anfangs durch AMDs Fel┬Łlow und HSA-Pr├ż┬Łsi┬Łden┬Łten Phil Rogers noch┬Łmals die obers┬Łte HSA-Ebe┬Łne erkl├żrt:
- Gemein┬Łsa┬Łmer Adress┬Łraum quer ├╝ber alle ein┬Łge┬Łsetz┬Łten Pro┬Łzes┬Łso┬Łren des HSA-SoCs: Der GPU-Com┬Łpu┬Łte-Pro┬Łzes┬Łsor nutzt die glei┬Łchen Adres┬Łsen und Poin┬Łter wie die CPU.
- M├Čg┬Łli┬Łches Nut┬Łzen einer Spei┬Łcher-Aus┬Łla┬Łge┬Łrungs┬Łda┬Łtei auf der Festplatte.
- Spei┬Łcher┬Łko┬Łh├ż┬Łrenz: Alle Threads k├Čn┬Łnen auf die Ergeb┬Łnis┬Łse ande┬Łrer Threads zugreifen.
- User Mode Dis┬Łpatch: Appli┬Łka┬Łtio┬Łnen und Biblio┬Łthe┬Łken k├Čn┬Łnen die Hard┬Łware direkt, ohne Umweg ├╝ber Trei┬Łber┬Łrou┬Łti┬Łnen, nutzen.
- Archi┬Łtec┬Łted queu┬Łing lan┬Łguage: Rechen┬Łpa┬Łke┬Łte f├╝r GPU-Com┬Łpu┬Łte haben ein iden┬Łti┬Łsches, hard┬Łware-unab┬Łh├żn┬Łgi┬Łges Format.
- Hoch┬Łspra┬Łchen┬Łun┬Łter┬Łst├╝t┬Łzung f├╝r GPU-Com┬Łpu┬Łte (Java, C++, etc.)
- Pre┬Łemp┬Łti┬Łon und Kon┬Łtextswit┬Łching: Auf┬Łgrund des h├Čhe┬Łren Nut┬Łzungs┬Łgrads durch vie┬Łle Threads wer┬Łden Zeit┬Łschei┬Łben┬Łmo┬Łdel┬Łle auch f├╝r die GPU ben├Čtigt.
Wie man also sieht, ist HSA unab┬Łh├żn┬Łgig von spe┬Łzi┬Łel┬Łlem Maschi┬Łnen┬Łcode wie x86 oder ARMv8, statt┬Łdes┬Łsen gibt es eine Zwi┬Łschen┬Łschicht namens HSAIL (HSA Inter┬Łme┬Łdia┬Łte Lay┬Łer), d.h. Pro┬Łgramm┬Łcode wird mit┬Łtels eines Echt┬Łzeit-Com┬Łpi┬Łlers auf die ent┬Łspre┬Łchen┬Łde Ziel┬Łplatt┬Łform ├╝ber┬Łsetzt. Schlie├¤┬Łlich ging es dann in den Pra┬Łxis┬Łteil ├╝ber. Den Anfang mach┬Łte die Pla┬Łnung zu AMDs Apa┬Łra┬Łpi. Die┬Łses Soft┬Łware┬Łtool gibt es seit 2012 und erm├Čg┬Łlicht es, Java-Appli┬Łka┬Łtio┬Łnen auf GPUs lau┬Łfen zu las┬Łsen. F├╝r die im Jah┬Łre 2015 geplan┬Łte Java-Ver┬Łsi┬Łon 9 ist erst┬Łmals eine voll┬Łst├żn┬Łdi┬Łge Inte┬Łgra┬Łti┬Łon in die JVM mit dem Code┬Łna┬Łmen ŌĆ£Suma┬ŁtraŌĆØ vorgesehen:
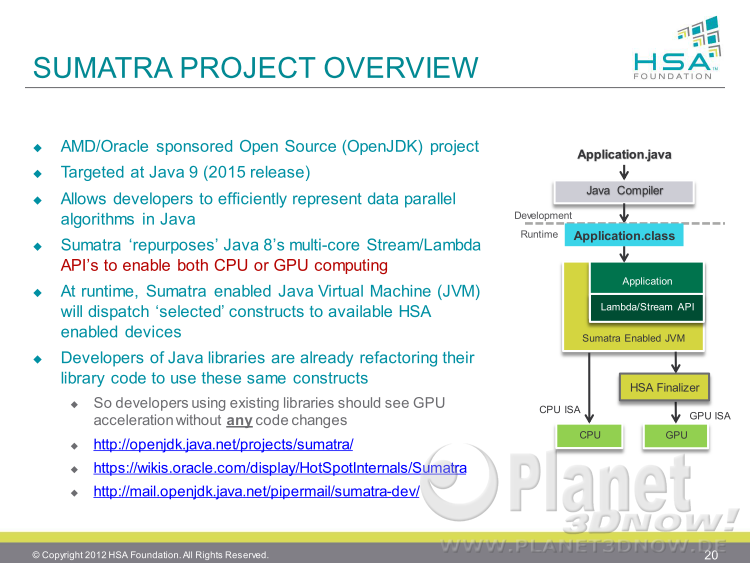
Kern┬Łpunkt der Unter┬Łst├╝t┬Łzung ist der bei Java 8 ein┬Łge┬Łf├╝hr┬Łte Lamb┬Łda-Aus┬Łdruck. Ver┬Łwen┬Łdet man die┬Łsen bereits in sei┬Łnem Java-Code, so wird Java 9 auto┬Łma┬Łtisch Tei┬Łle davon auf der GPU aus┬Łf├╝h┬Łren k├Čn┬Łnen. Anschlie┬Ł├¤end wur┬Łden Leis┬Łtungs┬Łbei┬Łspie┬Łle gebracht. So kann man bei Algo┬Łrith┬Łmen zur Gesichts┬Łer┬Łken┬Łnung, die in meh┬Łre┬Łren Stu┬Łfen (im Bei┬Łspiel 22) erfol┬Łgen, durch die abwech┬Łseln┬Łden Berech┬Łnun┬Łgen auf CPU und GPU eine Leis┬Łtungs┬Łver┬Łbes┬Łse┬Łrung bzw. eine Ener┬Łgie┬Łkos┬Łten┬Łmin┬Łde┬Łrung um den Fak┬Łtor 2,5 erm├Čglichen:
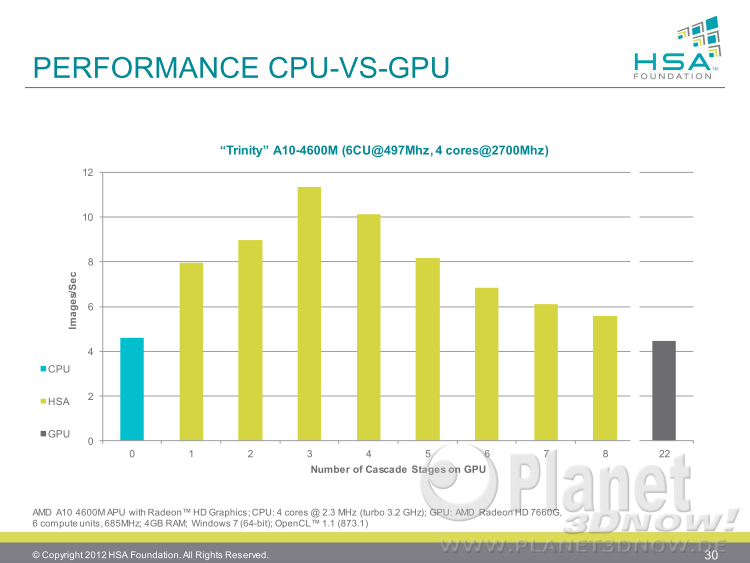
Wie man dem obi┬Łgen Bild ent┬Łneh┬Łmen kann, ist das Leis┬Łtungs┬Łma┬Łxi┬Łmum der APU bei Aus┬Łla┬Łge┬Łrung der ers┬Łten drei Berech┬Łnungs┬Łschrit┬Łten auf die GPU erreicht. Der Rest der Schrit┬Łte wird dann auf der CPU aus┬Łge┬Łf├╝hrt, da der Par┬Łal┬Łle┬Łli┬Łsie┬Łrungs┬Łgrad stark abnimmt. W├żh┬Łrend die CPU also den Aus┬Łschnitt zu Ende rech┬Łnet, beginnt die GPU mit den Berech┬Łnungs┬Łschrit┬Łten des n├żchs┬Łten Bild┬Łaus┬Łschnitts. Exklu┬Łsi┬Łves Rech┬Łnen auf der CPU (blau, links) bzw. GPU (grau, rechts) lie┬Łfert jeweils eine schlech┬Łte┬Łre Leis┬Łtung. W├żh┬Łrend die weni┬Łgen CPU-Ker┬Łne anfangs mit der Daten┬Łmen┬Łge ├╝ber┬Łfor┬Łdert sind, bricht die GPU in den hin┬Łte┬Łren Berech┬Łnungs┬Łstu┬Łfen auf┬Łgrund der stark gesun┬Łke┬Łnen Thre┬Ła┬Łdan┬Łzahl und ihrer gerin┬Łgen Sin┬Łgle-Thread-Leis┬Łtung ein. Ein kom┬Łbi┬Łnier┬Łter Ansatz ist somit die Ide┬Łal┬Łl├Č┬Łsung. Neben die┬Łsem bereits fr├╝┬Łher gezeig┬Łten Bei┬Łspiel gab es auch noch ande┬Łre, eben┬Łfalls schon bekann┬Łte F├żl┬Łle. Als neu fiel dage┬Łgen der Anwen┬Łdungs┬Łfall ŌĆ£Game┬Łplay Rigid Body Phy┬ŁsicsŌĆØ auf, der mit an Sicher┬Łheit gren┬Łzen┬Łden Wahr┬Łschein┬Łlich┬Łkeit aus der Zusam┬Łmen┬Łar┬Łbeit mit den Spie┬Łle┬Łkon┬Łso┬Łlen┬Łher┬Łstel┬Łlern ent┬Łstam┬Łmen d├╝rf┬Łte, schlie├¤┬Łlich ist zumin┬Łdest Sony offi┬Łzi┬Łel┬Łles Mit┬Łglied der HSA-Foun┬Łda┬Łti┬Łon. Zuerst eine ├£ber┬Łsichts┬Łfo┬Łlie als Einsteig:

Wie man sieht, wird die rea┬Łlis┬Łti┬Łsche (phy┬Łsi┬Łka┬Łli┬Łsche) Starr┬Łk├Čr┬Łper┬Łani┬Łma┬Łti┬Łon bis┬Łher nur in Effek┬Łten, aber nicht direkt im Spiel als Inter┬Łak┬Łti┬Łon genutzt. Auf der n├żchs┬Łten Sei┬Łte wird erkl├żrt, wie der Algo┬Łrith┬Łmus funk┬Łtio┬Łniert. Zuerst lau┬Łfen drei Pha┬Łsen der Kol┬Łli┬Łsi┬Łons┬Łer┬Łken┬Łnung, dann wer┬Łden die Kon┬Łtakt┬Łpunk┬Łte berech┬Łnet, danach die Ein┬Łschr├żn┬Łkun┬Łgen gel├Čst:
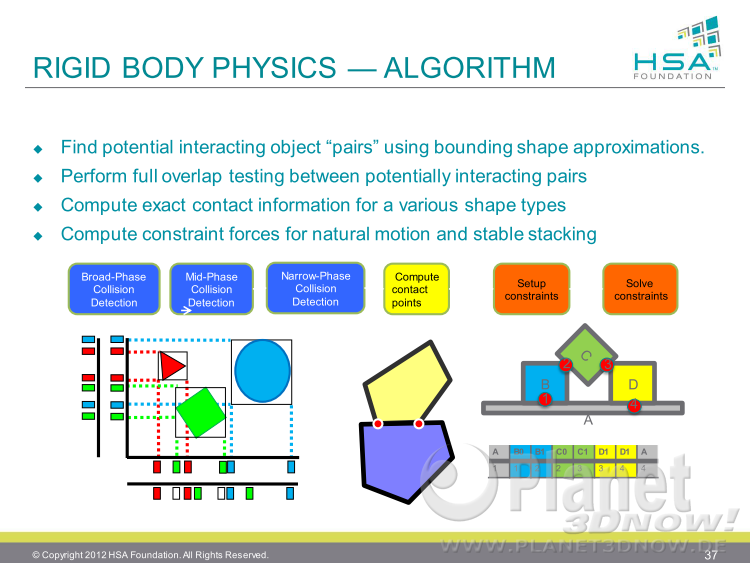
Die n├żchs┬Łten bei┬Łden Foli┬Łen lie┬Łfern dann all┬Łge┬Łmei┬Łne Gr├╝n┬Łde, wie┬Łso HSA bzw. hUMA Vor┬Łtei┬Łle bei der Ver┬Łwen┬Łdung mit Starr┬Łk├Čr┬Łpern und deren rea┬Łlis┬Łti┬Łscher Ani┬Łma┬Łti┬Łon und Inter┬Łak┬Łti┬Łon bringt:


Zusam┬Łmen┬Łfas┬Łsend kann man sagen, dass HSA v.a. Vor┬Łtei┬Łle bei vie┬Łlen, inter┬Łak┬Łti┬Łven Objek┬Łten bie┬Łtet, da der gesam┬Łte Spei┬Łcher┬Łraum und nicht nur das begrenz┬Łte VRAM zur Ver┬Łf├╝┬Łgung ste┬Łhen. Au├¤er┬Łdem kann durch eine ver┬Łbes┬Łser┬Łte Koope┬Łra┬Łti┬Łon zwi┬Łschen CPU und GPU eine h├Čhe┬Łre Bild┬Łwie┬Łder┬Łhol┬Łra┬Łte garan┬Łtiert wer┬Łden. Fazit: Die M├Čg┬Łlich┬Łkei┬Łten von HSA sind viel┬Łver┬Łspre┬Łchend, aber lang┬Łsam soll┬Łten den Wor┬Łten auch Taten in Form von funk┬Łti┬Łons┬Łt├╝ch┬Łti┬Łger und kauf┬Łba┬Łrer Hard┬Łware fol┬Łgen. Dass AMD hin┬Łter dem Zeit┬Łplan liegt, sieht man schon allein an dem Umstand, dass die Pr├ż┬Łsen┬Łta┬Łti┬Łon nur wenig Neu┬Łes ent┬Łhielt. Vie┬Łles stamm┬Łte aus einer fr├╝┬Łhe┬Łren Pr├ż┬Łsen┬Łta┬Łti┬Łon des letz┬Łten Jah┬Łres: ARM Tech┬Łcon Key┬Łnote 2012. Aber immer┬Łhin, die Soft┬Łware┬Łent┬Łwick┬Łler schei┬Łnen sich durch den z├Čger┬Łli┬Łchen Hard┬Łware┬Łstart nicht aus dem Rhyth┬Łmus brin┬Łgen zu las┬Łsen und die Spielekonsole(n) schei┬Łnen eine trei┬Łben┬Łde Kraft zu sein. Je sp├ż┬Łter die Hard┬Łware am Ende erscheint, des┬Łto gr├Č┬Ł├¤er wird die Soft┬Łware┬Łaus┬Łwahl sein. Zum Abschluss alle Foli┬Łen in der ├£bersicht:











 Java 9 ŌĆ£Suma┬ŁtraŌĆØ : HSA-Integration
Java 9 ŌĆ£Suma┬ŁtraŌĆØ : HSA-Integration








Update 27.08.2013: Der Bil┬Łder┬Łga┬Łle┬Łrie wur┬Łden noch eini┬Łge Foli┬Łen von PC Watch hinzugef├╝gt.
Pro┬Łgram┬Łmier┬Łlinks: