Der gesockelte Kabini ŌĆö Athlon 5350 im Test
AMDs Jaguar-Kerne
Anmer┬Łkung: Die┬Łse Sei┬Łte wur┬Łde von Dres┬Łden┬Łboy erstellt, vie┬Łlen Dank an die┬Łser Stelle!
Nach dem erfolg┬Łrei┬Łchen Start des Bob┬Łcat-Kerns in den Note┬Łbook- und Embedded-Plat┬Łform-M├żrk┬Łten leg┬Łte AMD im Jahr 2013 mit der Jagu┬Łar-Mikro┬Łar┬Łchi┬Łtek┬Łtur nach. Die┬Łse bil┬Łdet auch die Basis f├╝r den hier getes┬Łte┬Łten Pro┬Łzes┬Łsor. Des┬Łsen Fer┬Łti┬Łgung erfolgt im bew├żhr┬Łten 28nm-Her┬Łstel┬Łlungs┬Łpro┬Łzess bei TSMC oder Glo┬Łbal┬Łfound┬Łries (wie erst k├╝rz┬Łlich bekannt wur┬Łde). Das ver┬Łbes┬Łsert gegen┬Ł├╝ber dem in 40nm gefer┬Łtig┬Łten Bob┬Łcat sowohl den Takt┬Łfre┬Łquenz┬Łspiel┬Łraum als auch den Ver┬Łbrauch. Unter der Hau┬Łbe flos┬Łsen jedoch vie┬Łle wei┬Łte┬Łre ├ände┬Łrun┬Łgen ein, die die Leis┬Łtung des Pro┬Łzes┬Łsors deut┬Łlich verbessern.
Auf der Hot-Chips-25-Kon┬Łfe┬Łrenz zeig┬Łte AMD die zusam┬Łmen┬Łge┬Łfass┬Łten Ent┬Łwick┬Łlungs┬Łzie┬Łle f├╝r die neue Mikro┬Łar┬Łchi┬Łtek┬Łtur. Neben den typi┬Łschen Zie┬Łlen von ver┬Łbes┬Łser┬Łter IPC, Takt┬Łfre┬Łquenz sowie Ener┬Łgie┬Łef┬Łfi┬Łzi┬Łenz stand auch die Erwei┬Łte┬Łrung um die g├żn┬Łgi┬Łgen Befehls┬Łsatz┬Łer┬Łwei┬Łte┬Łrun┬Łgen, wie AVX und AES, und einen gr├Č┬Ł├¤e┬Łren phy┬Łsi┬Łka┬Łli┬Łschen Adress┬Łraum auf dem Pro┬Łgramm. Ver┬Łbes┬Łser┬Łte Vir┬Łtua┬Łli┬Łsie┬Łrungs┬Łun┬Łter┬Łst├╝t┬Łzung und Por┬Łtier┬Łbar┬Łkeit zwi┬Łschen Pro┬Łzes┬Łsen run┬Łden das Gan┬Łze ab. Letz┬Łte┬Łre erkl├żrt die aktu┬Łel┬Łle Fer┬Łti┬Łgung bei Globalfoundries.
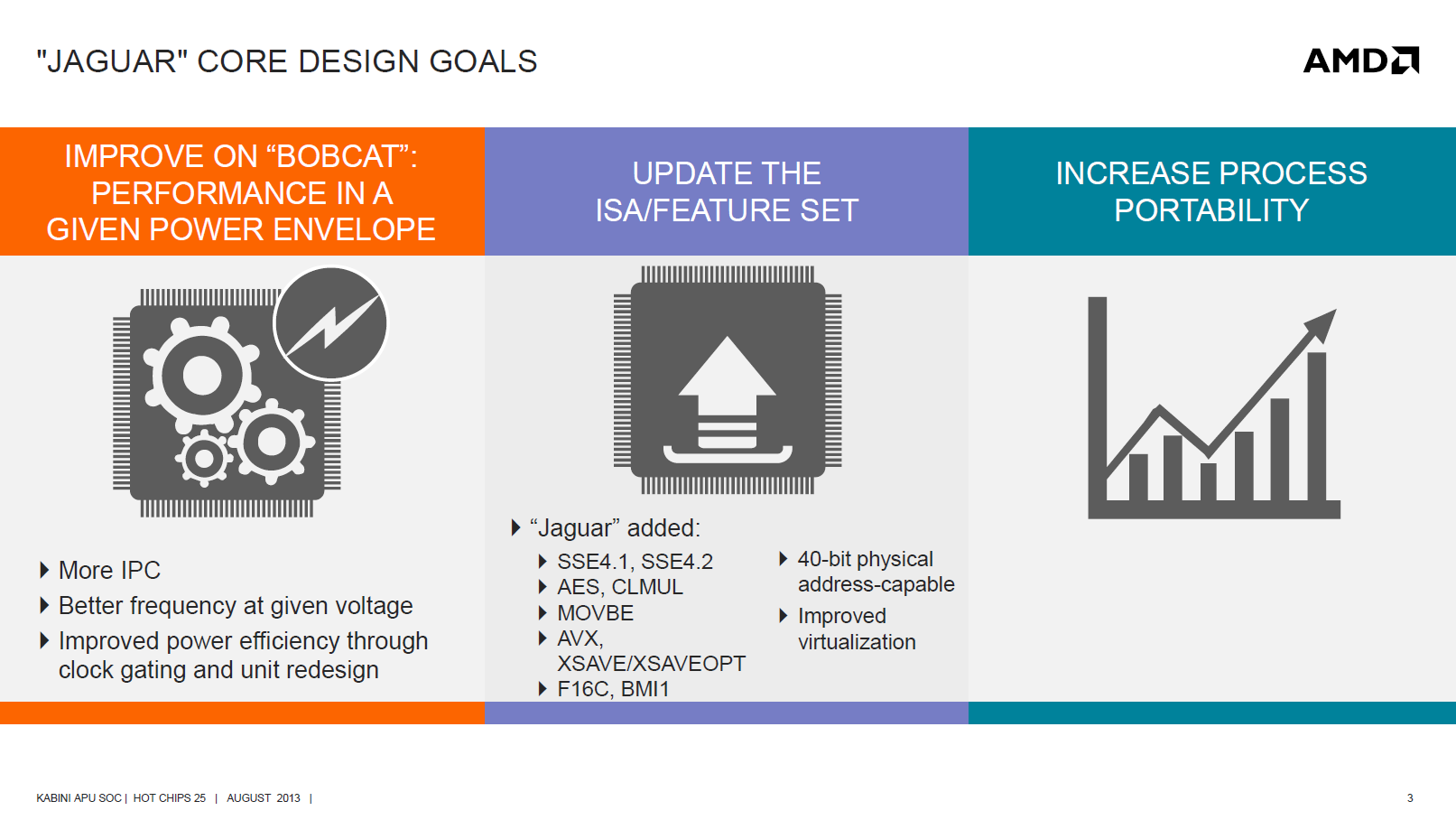
Eine wei┬Łte┬Łre Folie fasst die ├ände┬Łrun┬Łgen in der Mikro┬Łar┬Łchi┬Łtek┬Łtur gegen┬Ł├╝ber dem Bob┬Łcat-Kern zusam┬Łmen. Des┬Łsen Mikro┬Łar┬Łchi┬Łtek┬Łtur wur┬Łde hier bereits vor┬Łge┬Łstellt: http://www.planet3dnow.de/vbulletin/showthread.php/385065-Bobcat-das-Bulldoezerchen
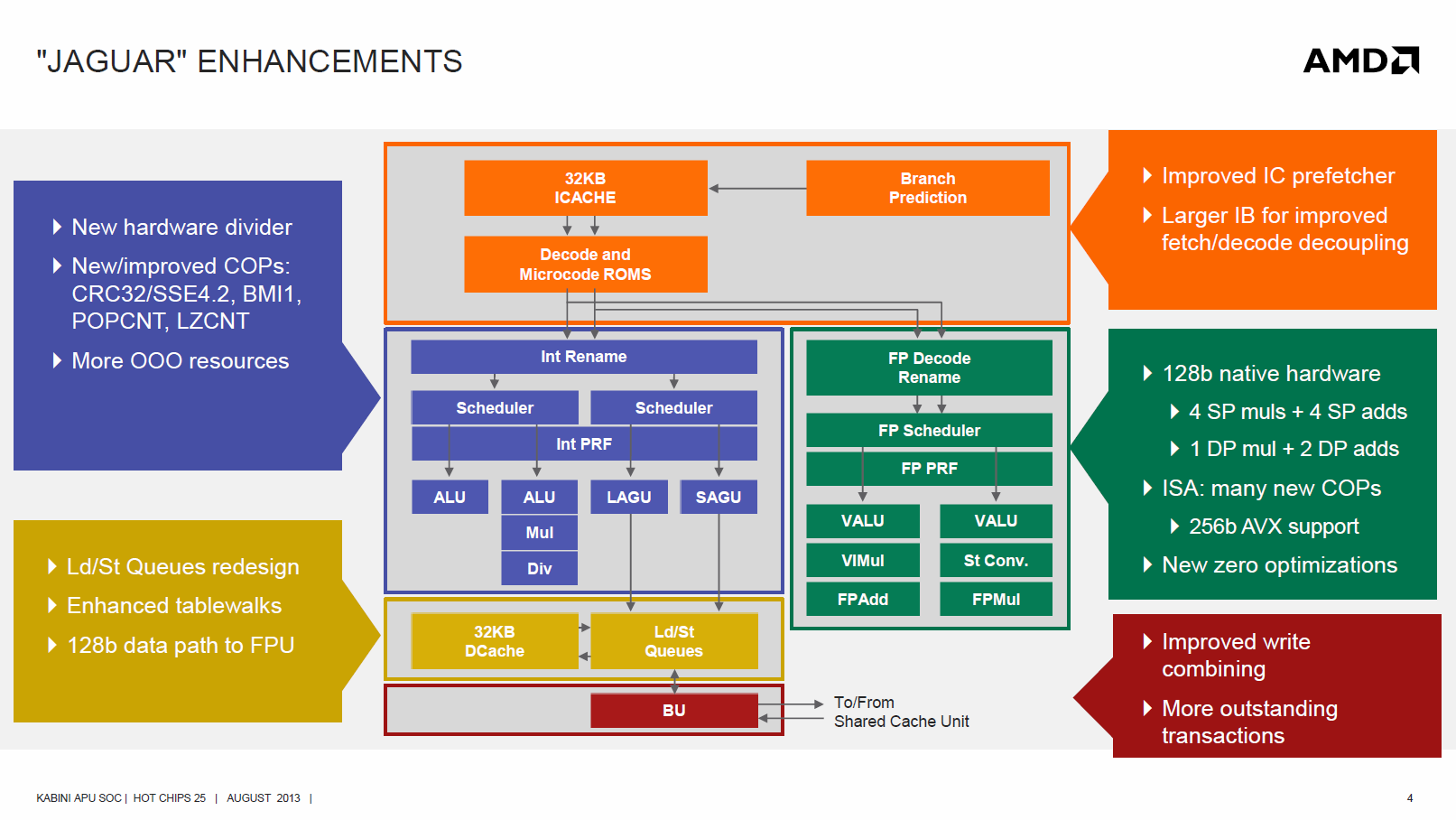
Auf der Folie ist zu erken┬Łnen, dass in jede Haupt┬Łkom┬Łpo┬Łnen┬Łte Ver┬Łbes┬Łse┬Łrun┬Łgen ein┬Łge┬Łflos┬Łsen sind. Das Front-End erhielt einen bes┬Łse┬Łren Ins┬Łtruc┬Łtion-Cache-Pre┬Łfet┬Łcher sowie einen von 192 Byte auf 256 Byte ver┬Łgr├Č┬Ł├¤er┬Łten Befehls┬Łpuf┬Łfer, um Fetch und Decode st├żr┬Łker zu ent┬Łkop┬Łpeln. Ein 4x32 Byte gro┬Ł├¤er Loop-Buf┬Łfer hilft beim Energiesparen.
Die Inte┬Łger-Ein┬Łheit wur┬Łde mit zus├żtz┬Łli┬Łchen Out-of-Order-Res┬Łsour┬Łcen und einer Hard┬Łware-Divi┬Łdier-Ein┬Łheit aus┬Łge┬Łstat┬Łtet. Hin┬Łzu kom┬Łmen eini┬Łge Befehlssatzerweiterungen.
Die FPU erhielt die deut┬Łlichs┬Łte ├ände┬Łrung in Form einer Ver┬Łbrei┬Łte┬Łrung auf 128 Bit und Unter┬Łst├╝t┬Łzung von 256-Bit-AVX. Allein das ver┬Łdop┬Łpelt den theo┬Łre┬Łti┬Łschen SIMD-Durch┬Łsatz im Ver┬Łgleich zur Bob┬Łcat-FPU. Die grund┬Łs├żtz┬Łli┬Łche Struk┬Łtur wur┬Łde etwas opti┬Łmiert. Wie┬Łviel davon in Rea┬Łli┬Łt├żt zu sehen ist, zei┬Łgen die Tests.
Die Loa┬Łd/S┬Łto┬Łre-Ein┬Łheit erhielt einen ver┬Łbrei┬Łter┬Łten 128-Bit-Daten┬Łpfad zur FPU und neu design┬Łte Queu┬Łes und Tab┬Łle┬Łwalks (x86-typi┬Łsche Auf┬Łl├Č┬Łsung vir┬Łtu┬Łel┬Łler Adres┬Łsen). Die dar┬Łan ange┬Łbun┬Łde┬Łne Bus Unit soll mit ver┬Łbes┬Łser┬Łtem Wri┬Łte Com┬Łbi┬Łning und der F├żhig┬Łkeit, mehr Trans┬Łak┬Łtio┬Łnen gleich┬Łzei┬Łtig zu bear┬Łbei┬Łten, sowohl dem ver┬Łbes┬Łser┬Łten Durch┬Łsatz des Kerns als auch dem neu┬Łen geteil┬Łten L2-Cache gerecht werden.
Die Pipe┬Łline wur┬Łde um eine Stu┬Łfe ver┬Łl├żn┬Łgert (eine zus├żtz┬Łli┬Łche Regis┬Łter Read-Stu┬Łfe), wodurch die Branch Miss Penal┬Łty von 13 auf 14 Zyklen steigt. Bis auf die┬Łse ├ände┬Łrung gleicht sie der Bobcat-Pipeline.
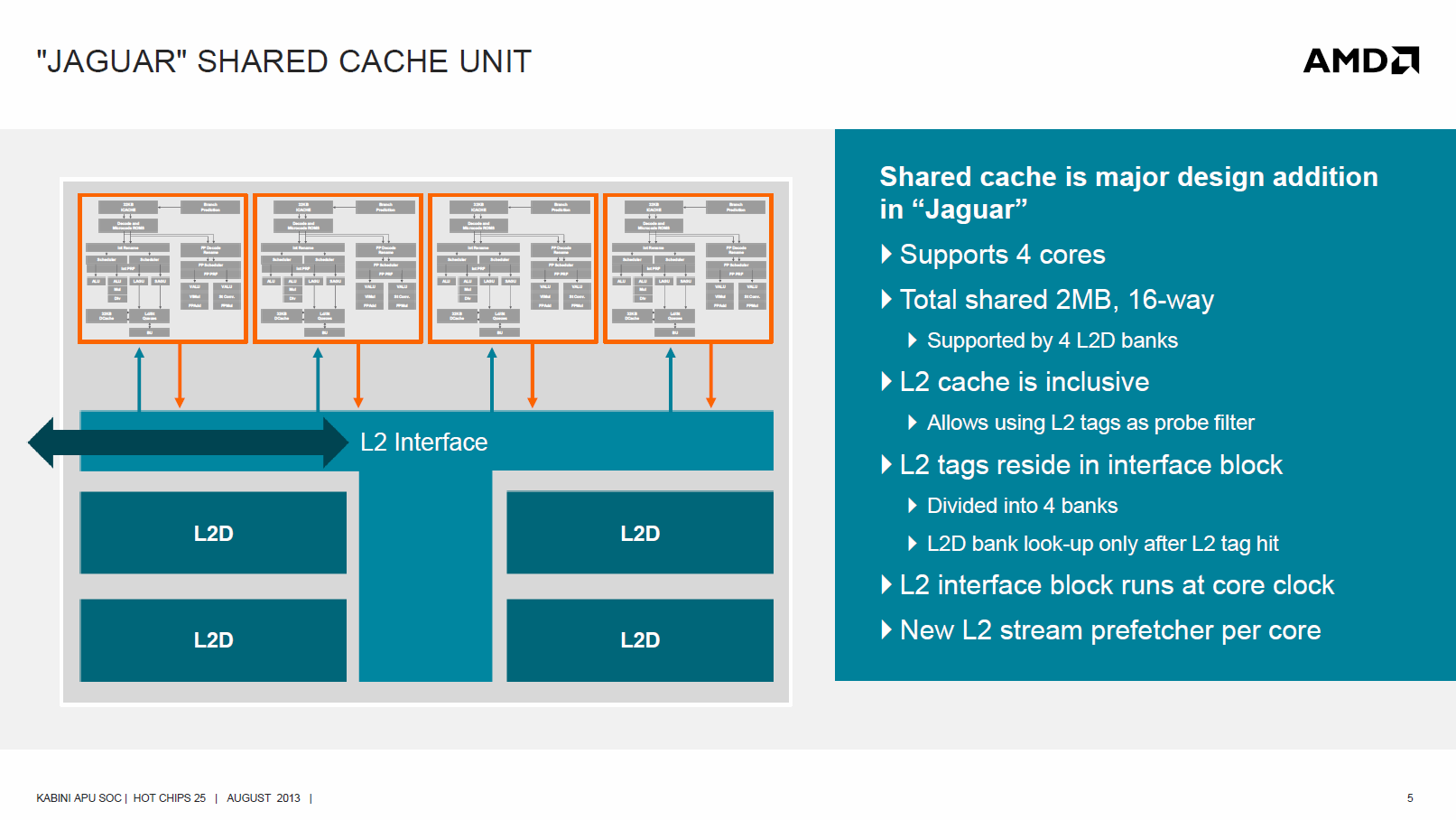
Der L2-Cache ist deut┬Łlich f├╝r par┬Łal┬Łlel rech┬Łnen┬Łde Anwen┬Łdun┬Łgen und st├żr┬Łker for┬Łdern┬Łde Mul┬Łti┬Łtas┬Łking-Auf┬Łga┬Łben aus┬Łge┬Łlegt. Im Ver┬Łgleich zu den ein┬Łzel┬Łnen L2-Caches der Bob┬Łcat-Ker┬Łne wur┬Łde nun die Gr├Č┬Ł├¤e deut┬Łlich erh├Čht und die gleich┬Łzei┬Łti┬Łge Nut┬Łzung durch bis zu vier Jagu┬Łar-Ker┬Łne ein┬Łge┬Łf├╝hrt. Die┬Łse Ein┬Łheit mit den Ker┬Łnen wird auch Com┬Łpu┬Łte-Unit genannt.
├£ber den Cache k├Čn┬Łnen die Ker┬Łne effi┬Łzi┬Łent gemein┬Łsam auf Daten zugrei┬Łfen. Die Gr├Č┬Ł├¤e erlaubt auch eine fle┬Łxi┬Łble Nut┬Łzung je nach Bedarf. Das Inter┬Łface zu den Ker┬Łnen l├żuft mit Kern-Takt, w├żh┬Łrend die vier Cache-Spei┬Łcher┬Łb├żn┬Łke mit hal┬Łbem Takt arbei┬Łten. Jede Spei┬Łcher┬Łbank lie┬Łfert 16 Bytes pro Takt, was bei ver┬Łteil┬Łtem Zugriff maxi┬Łmal 64 Bytes pro Takt erm├Čg┬Łlicht. Der Cache ist inklu┬Łsiv aus┬Łge┬Łlegt und kann mit sei┬Łnen Tags als Snoop-Fil┬Łter zwi┬Łschen den Ker┬Łnen die┬Łnen. Ein neu┬Łer Stream Pre┬Łfet┬Łcher soll hel┬Łfen, die pas┬Łsen┬Łden Daten unab┬Łh├żn┬Łgig von den Core-Pre┬Łfet┬Łchern vorzuladen.
Neben die┬Łsen Archi┬Łtek┬Łtur┬Łver┬Łbes┬Łse┬Łrun┬Łgen haben die AMD-Inge┬Łnieu┬Łre nat├╝r┬Łlich auch die Ener┬Łgie┬Łef┬Łfi┬Łzi┬Łenz wei┬Łter opti┬Łmiert sowie ein fle┬Łxi┬Łble┬Łres Manage┬Łment der ver┬Łf├╝g┬Łba┬Łren Ener┬Łgie und des aktu┬Łel┬Łlen Ver┬Łbrauchs inte┬Łgriert. AMD gibt an, dass bei typi┬Łschen Appli┬Łka┬Łtio┬Łnen meist mehr als 92% der Tran┬Łsis┬Łto┬Łren abge┬Łschal┬Łtet (clock gated) sind.
Die┬Łser Mikro┬Łar┬Łchi┬Łtek┬Łtur┬Ł├╝ber┬Łblick soll mit einer Tabel┬Łle aus AMDs ISSCC-Pr├ż┬Łsen┬Łta┬Łti┬Łon abschlie┬Ł├¤en. Die┬Łse zeigt wei┬Łte┬Łre phy┬Łsi┬Łsche Eigen┬Łschaf┬Łten und Architekturdetails.
Quel┬Łle: ISSCC 2013