Vishera Reloaded
Performance mit vier Threads
Auf die┬Łser Sei┬Łte m├Čch┬Łten wir uns den Per┬Łfor┬Łmance-Unter┬Łschied anschau┬Łen, wel┬Łcher bei Nut┬Łzung von vier Threads auf vier Modu┬Łlen bzw. vier Threads auf zwei Modu┬Łlen ent┬Łsteht. AMD gibt an, durch Ver┬Łdop┬Łpe┬Łlung der Regis┬Łter sowie der Inte┬Łger-Ein┬Łhei┬Łten, was etwa 20 Pro┬Łzent des Fl├ż┬Łchen┬Łbe┬Łdarfs eines ŌĆ£ech┬ŁtenŌĆØ Kerns bedeu┬Łtet, ca. 80 Pro┬Łzent der Per┬Łfor┬Łmance eines Kerns erzie┬Łlen zu k├Čn┬Łnen. Auf unse┬Łre Test┬Łrei┬Łhe ├╝ber┬Łtra┬Łgen bedeu┬Łtet dies, dass vier Threads, wel┬Łche auf vier Modu┬Łlen lau┬Łfen (also je Thread die kom┬Łplet┬Łten Res┬Łsour┬Łcen eines Moduls zur Ver┬Łf├╝┬Łgung ste┬Łhen) schnel┬Łler arbei┬Łten k├Čn┬Łnen als vier Threads, die sich die Res┬Łsour┬Łcen von zwei Modu┬Łlen tei┬Łlen m├╝s┬Łsen. Vier Threads auf zwei Modu┬Łlen sol┬Łlen also etwa 90 Pro┬Łzent der Leis┬Łtung von vier Threads auf vier Modu┬Łlen errei┬Łchen. So sind jeden┬Łfalls die Anga┬Łben von AMD zu ver┬Łste┬Łhen. Wer┬Łfen wir nun einen Blick auf die Pra┬Łxis, f├╝r wel┬Łche die┬Łses Mal das Giga┬Łbyte GA-990FXA-UD7 zum Ein┬Łsatz kommt:
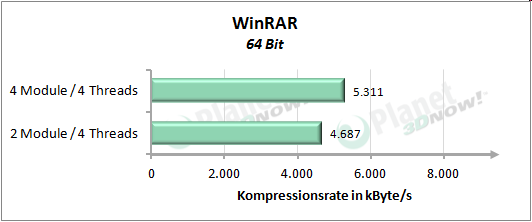
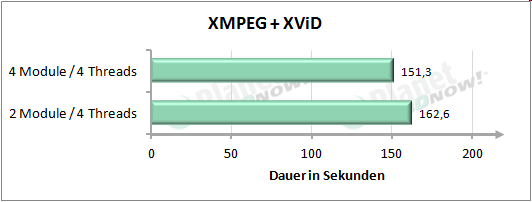
Das Ergeb┬Łnis in XMPEG zeigt jedoch noch eine wei┬Łte┬Łre Beson┬Łder┬Łheit, wel┬Łche nicht aus dem Dia┬Łgramm her┬Łvor┬Łgeht: In Nor┬Łmal┬Łkon┬Łfi┬Łgu┬Łra┬Łti┬Łon (also acht Threads auf vier Modu┬Łlen) dau┬Łert der XMPEG-Bench┬Łmark zwi┬Łschen 185 Sekun┬Łden (Tur┬Łbo CORE akti┬Łviert) und 191 Sekun┬Łden (Tur┬Łbo CORE deak┬Łti┬Łviert). Bei┬Łde Kon┬Łfi┬Łgu┬Łra┬Łtio┬Łnen mit vier Threads unter┬Łbie┬Łten die┬Łses Ergeb┬Łnis mehr als deut┬Łlich. Zuerst hat┬Łten wir hier das ver┬Łwen┬Łde┬Łte Giga┬Łbyte-Main┬Łboard in Ver┬Łdacht. Doch wir muss┬Łten schnell fest┬Łstel┬Łlen, dass es tat┬Łs├żch┬Łlich an den zur Ver┬Łf├╝┬Łgung ste┬Łhen┬Łden Res┬Łsour┬Łcen liegt. Denn akti┬Łviert man auch auf dem Giga┬Łbyte-Main┬Łboard wie┬Łder alle acht Threads des FX-8350, so lan┬Łdet die Bear┬Łbei┬Łtungs┬Łzeit auch wie┬Łder im bis┬Łher bekann┬Łten Zeit┬Łfens┬Łter. Somit scheint die┬Łse Soft┬Łware ein Pro┬Łblem mit der Modul┬Łbau┬Łwei┬Łse zu haben bzw. mit weni┬Łger Res┬Łsour┬Łcen bes┬Łser klar┬Łzu┬Łkom┬Łmen. M├Čg┬Łli┬Łcher┬Łwei┬Łse liegt das an her┬Łum┬Łge┬Łreich┬Łten Bear┬Łbei┬Łtungs┬Łth┬Łreads, wel┬Łche immer wie┬Łder auf gera┬Łde abge┬Łschal┬Łte┬Łten Ker┬Łnen lan┬Łden, was bis zum erneu┬Łten Auf┬Łwa┬Łchen eini┬Łge Takt┬Łzy┬Łklen kos┬Łtet. Eine wei┬Łte┬Łre Erkl├ż┬Łrung k├Čnn┬Łte sein, dass XMPEG h├żu┬Łfig auf Daten im L2-Cache zur├╝ck┬Łgreift. Sobald ein Bear┬Łbei┬Łtungs┬Łth┬Łread auf ein ande┬Łres Modul ver┬Łscho┬Łben wur┬Łde, ist der L2-Cache des soeben noch genutz┬Łten Moduls f├╝r den Thread nicht mehr erreich┬Łbar, sodass erst wie┬Łder nach┬Łge┬Łla┬Łden wer┬Łden muss.
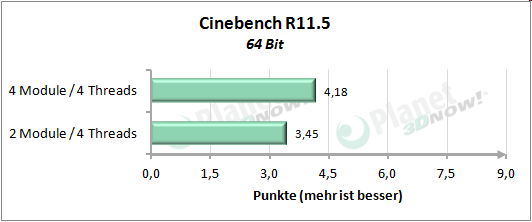
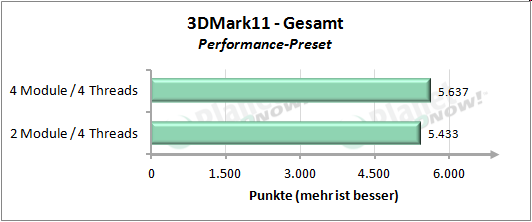
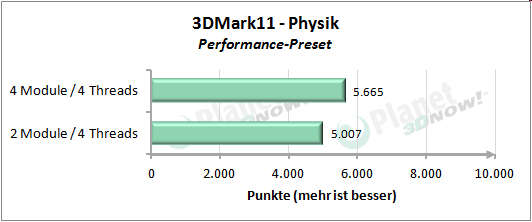
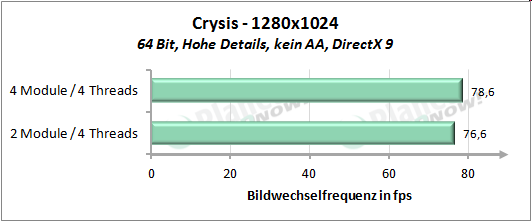
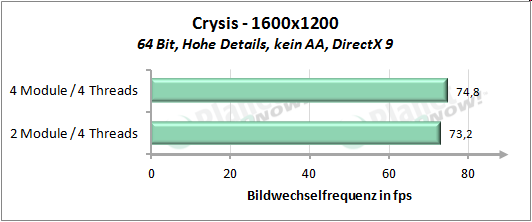
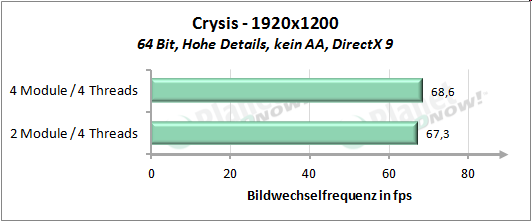
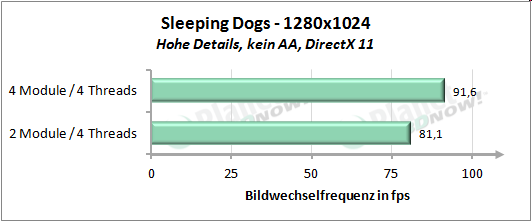
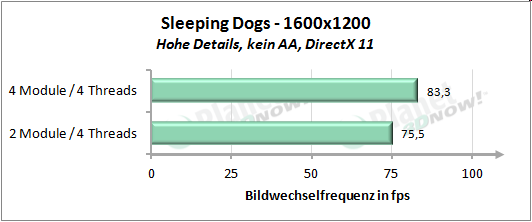
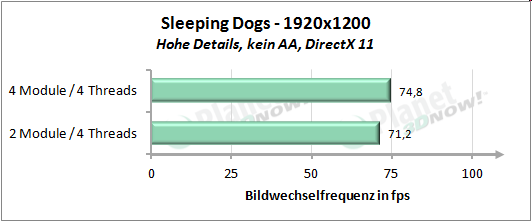
├£ber unse┬Łren kur┬Łzen Test┬Łpar┬Łcours gemit┬Łtelt erreicht die Modul┬Łbau┬Łwei┬Łse 92 Pro┬Łzent der Leis┬Łtung von vier Threads auf vier nati┬Łven Ker┬Łnen. Inso┬Łfern wird die Aus┬Łsa┬Łge von AMD, etwa 90 Pro┬Łzent der Leis┬Łtung zu errei┬Łchen, ziem┬Łlich genau eingehalten.