AMD Zen 2 und Rome ŌĆō was wir bisher wissen
Die kom┬Łmen┬Łde CPU-Archi┬Łtek┬Łtur Zen 2 wird AMD zuerst im f├╝r 2019 geplan┬Łten Ser┬Łver-Pro┬Łzes┬Łsor Epyc ŌĆ£RomeŌĆØ ein┬Łf├╝h┬Łren. Das macht Sinn, da die Ser┬Łver-Platt┬Łform den Zwi┬Łschen┬Łschritt ŌĆ£Zen+ŌĆØ ├╝ber┬Łsprun┬Łgen hat, der uns 2018 die in vie┬Łlen Details ver┬Łbes┬Łser┬Łten Ryzen 2000 CPUs beschert hat. K├╝rz┬Łlich hat┬Łte AMD ja, wie berich┬Łtet, offi┬Łzi┬Łel┬Łle Infor┬Łma┬Łtio┬Łnen zu Rome ver┬Ł├Čf┬Łfent┬Łlicht, aller┬Łdings auch vie┬Łle Details aus┬Łge┬Łspart. In der Zwi┬Łschen┬Łzeit sind in der Ger├╝ch┬Łte┬Łk├╝┬Łche jedoch eini┬Łge Info┬Łschnip┬Łsel dazu┬Łge┬Łkom┬Łmen, die wir nicht uner┬Łw├żhnt las┬Łsen wollen.
Zen 2 und Rome ŌĆō was AMD bis┬Łher offi┬Łzi┬Łell ver┬Łra┬Łten hat
Auf der in San Fran┬Łcis┬Łco abge┬Łhal┬Łte┬Łnen ŌĆ£Next Hori┬ŁzonŌĆØ Pr├ż┬Łsen┬Łta┬Łti┬Łon hat AMD den Vor┬Łhang gel├╝f┬Łtet. Der Ser┬Łver-Pro┬Łzes┬Łsor Epyc ŌĆ£RomeŌĆØ im Spe┬Łzi┬Łel┬Łlen wird wie schon der aktu┬Łel┬Łle Nap┬Łles ein Mul┬Łti-Chip-Design wer┬Łden. Aller┬Łdings geht AMD bei Rome noch einen Schritt wei┬Łter und rea┬Łli┬Łsiert die CPU nicht mit iden┬Łti┬Łschen Dies, son┬Łdern trennt Rechen┬Łein┬Łhei┬Łten und I/O. So wird Rome aus bis zu 8 Com┬Łpu┬Łte-Chip┬Łlets bestehen, die je 8 Ker┬Łne auf┬Łwei┬Łsen, sowie aus einem I/OŌĆæChip.

W├żh┬Łrend die eigent┬Łli┬Łchen Rechen-Chip┬Łlets in 7 nm bei TSMC gefer┬Łtigt wer┬Łden, kommt der I/OŌĆæChip nach wie vor in 14 nm daher. Der Sinn dahin┬Łter ist, dass vie┬Łle Kom┬Łpo┬Łnen┬Łten im I/OŌĆæBereich nicht so sehr von der Schrump┬Łfung der Fer┬Łti┬Łgung pro┬Łfi┬Łtie┬Łren und daher bes┬Łser im g├╝ns┬Łti┬Łge┬Łren 14-nm-Ver┬Łfah┬Łren pro┬Łdu┬Łziert wer┬Łden k├Čn┬Łnen. Zudem wird AMD sicher┬Łlich nach wie vor Abnah┬Łme┬Łver┬Łtr├ż┬Łge mit sei┬Łner ehe┬Łma┬Łli┬Łgen haus┬Łei┬Łge┬Łnen Fab (jetzt Glo┬Łbal┬ŁFound┬Łries) haben, die auf die┬Łse Wei┬Łse erf├╝llt wer┬Łden k├Čn┬Łnen, obwohl die eigent┬Łli┬Łchen Zen-2-Dies bei TSMC in 7 nm pro┬Łdu┬Łziert wer┬Łden. Kom┬Łmu┬Łni┬Łziert wur┬Łde auch, dass AMD mit Rome PCI-Express 4.0 ein┬Łf├╝h┬Łren wird (sofern das Main┬Łboard es unter┬Łst├╝tzt), es bei acht Spei┬Łcher┬Łka┬Łn├ż┬Łlen bleibt (DDR4 logi┬Łscher┬Łwei┬Łse, da DDR5 noch nicht ein┬Łge┬Łf├╝hrt wur┬Łde) und die zwei┬Łte Gene┬Łra┬Łti┬Łon der soge┬Łnann┬Łten Infi┬Łni┬Łty Fabric zum Ein┬Łsatz kommt, also der Kom┬Łmu┬Łni┬Łka┬Łti┬Łons┬Łpfad zwi┬Łschen den ein┬Łzel┬Łnen Ker┬Łnen, die sich nicht im sel┬Łben Seg┬Łment befinden.

Auch zur Zen-2-Archi┬Łtek┬Łtur als sol┬Łcher wur┬Łden Details genannt, wie etwa die ver┬Łbes┬Łser┬Łte Exe┬Łcu┬Łti┬Łon Pipe┬Łline, die ver┬Łbes┬Łser┬Łte Sprung┬Łvor┬Łher┬Łsa┬Łge samt Pre┬Łfet┬Łching, der opti┬Łmier┬Łte Befehls┬Łcache, ein gr├Č┬Ł├¤e┬Łrer Op-Cache und ŌĆō ganz wich┬Łtig ŌĆō die dop┬Łpelt so brei┬Łte FPU, die nun 256 Bit in einem Rutsch ver┬Łar┬Łbei┬Łten kann statt zwei Mal 128 Bit nach┬Łein┬Łan┬Łder. Dazu wur┬Łde auch die Load-/Sto┬Łre-Band┬Łbrei┬Łte ver┬Łdop┬Łpelt. Zudem hat AMD ver┬Łspro┬Łchen, dass Gegen┬Łma├¤┬Łnah┬Łmen zu den Sicher┬Łheits┬Łpro┬Łble┬Łmen der Spect┬Łre-Fami┬Łlie per Hard┬Łware getrof┬Łfen wurden.

Die ers┬Łten Main┬Łboards f├╝r Rome
Inter┬Łes┬Łsan┬Łter┬Łwei┬Łse hat AMD auf der ŌĆ£Next HorizonŌĆØ-Pr├żsentation nicht expli┬Łzit den Sockel SP3 erw├żhnt. Zur Markt┬Łein┬Łf├╝h┬Łrung des Nap┬Łles hat┬Łte AMD aller┬Łdings betont, dass der Sockel SP3 ├╝ber Jah┬Łre die desi┬Łgnier┬Łte Ser┬Łver-Platt┬Łform blei┬Łben wird. Damit d├╝rf┬Łten auch CPU-Upgrades per Drop-In-Repla┬Łce┬Łment m├Čg┬Łlich sein, sofern Main┬Łboard-Her┬Łstel┬Łler ihre Nap┬Łles-Pla┬Łti┬Łnen per BIOS-Update fit f├╝r Rome machen. In der Zwi┬Łschen┬Łzeit hat Giga┬Łbyte ein Main┬Łboard f├╝r Rome gezeigt, das neben der Beschrif┬Łtung ŌĆ£PCIe Gen 4ŌĆØ auch expli┬Łzit ŌĆ£SP3ŌĆØ als Sockel ein┬Łgra┬Łviert hat.

Der Die-Auf┬Łbau und die Caches
Offi┬Łzi┬Łell sagt AMD bis┬Łher nichts dazu, aber bereits vor ├╝ber einem Jahr ging das Ger├╝cht um, dass AMD bei Rome die Kern┬Łan┬Łzahl ver┬Łdop┬Łpeln und die L3-Cache┬Łgr├Č┬Ł├¤e ver┬Łvier┬Łfa┬Łchen wird. Die Ver┬Łdop┬Łpe┬Łlung der Kern┬Łan┬Łzahl ist tat┬Łs├żch┬Łlich so ein┬Łge┬Łtre┬Łten, sodass die Ger├╝ch┬Łte zur vier┬Łfa┬Łchen Cache┬Łgr├Č┬Ł├¤e (bzw. Ver┬Łdop┬Łpe┬Łlung je Kern) nicht aus┬Łzu┬Łschlie┬Ł├¤en sind.
Ver┬Łgan┬Łge┬Łne Woche ist ein Ein┬Łtrag in der SiS┬Łoft┬Łware-Daten┬Łbank auf┬Łge┬Łtaucht (inzwi┬Łschen wie┬Łder ver┬Łschwun┬Łden), der von einem Rome Engi┬Łnee┬Łring-Sam┬Łple stam┬Łmen soll.
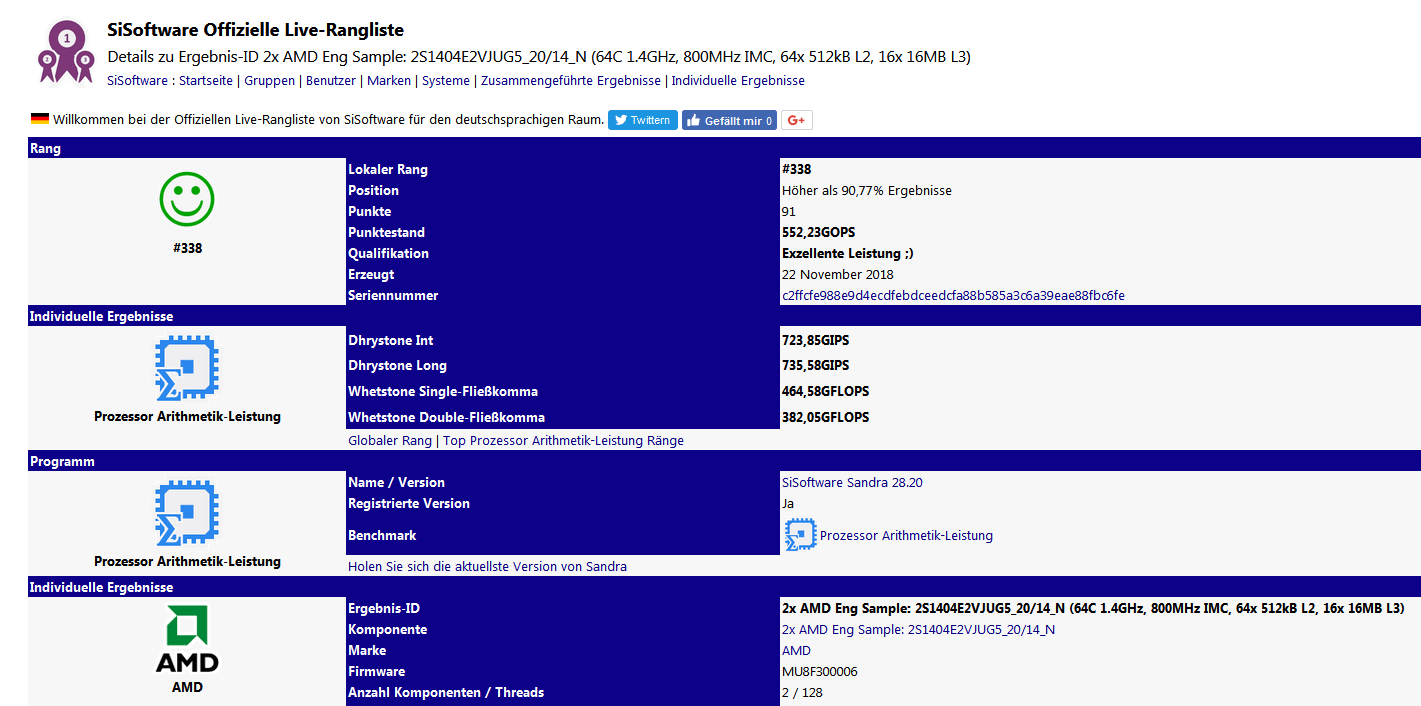
Das Engi┬Łnee┬Łring-Sam┬Łple mit der Bezeich┬Łnung 2S1404E2VJUG5_20/14_N soll 64 Ker┬Łne auf┬Łwei┬Łsen, die mit 1,4 GHz getak┬Łtet sind. Das w├żre selbst f├╝r ein Engi┬Łnee┬Łring-Sam┬Łple recht wenig. Aller┬Łdings kann nat├╝r┬Łlich sein, dass AMD ange┬Łsichts der ├╝ber┬Łbor┬Łden┬Łden Anzahl an Ker┬Łnen den Basistakt betont nied┬Łrig ansetzt um inner┬Łhalb der f├╝r SP3 ├╝bli┬Łchen TDP zu blei┬Łben, und dann bei den fina┬Łlen Samples den Rest per Tur┬Łbo erle┬Łdigt. Das ist auch bei unse┬Łrem Nap┬Łles im Pla┬Łnet 3DNow! Web┬Łser┬Łver so. Der hat einen Basistakt von nur 2,4 GHz, l├żuft aber prak┬Łtisch durch┬Łge┬Łhend im Tur┬Łbo┬Łmo┬Łdus um 2,8 GHz her┬Łum, selbst dann, wenn man k├╝nst┬Łlich alle Ker┬Łne belastet.
Inter┬Łes┬Łsan┬Łter als der Takt, der sich nat├╝r┬Łlich noch ├żndern kann und wird bei den fina┬Łlen Pro┬Łduk┬Łten, ist die Anga┬Łbe zum Cache: 16x 16 MB L3-Cache steht dort. Zum einen w├żren das 256 MB und damit wirk┬Łlich vier┬Łmal so viel wie bei Nap┬Łles, wo maxi┬Łmal 64 MB L3-Cache bereit┬Łste┬Łhen. Zum ande┬Łren sagt auch die Anga┬Łbe ŌĆ£16xŌĆØ eini┬Łges ├╝ber den Chip┬Łauf┬Łbau aus, sofern San┬Łdra die Archi┬Łtek┬Łtur kor┬Łrekt aus┬Łge┬Łle┬Łsen hat. Da AMD bereits kom┬Łmu┬Łni┬Łziert hat, dass Rome aus acht Zen-2-Dies bestehen wird, w├╝r┬Łde der Umstand, dass der L3-Cache aus 16 Seg┬Łmen┬Łten besteht, dar┬Łauf hin┬Łdeu┬Łten, dass jedes Zen-2-Die ŌĆō so wie bei Zen 1 ŌĆō aus zwei CCX bestehen wird. Also kein homo┬Łge┬Łnes 8ŌĆæKern-Die mit glei┬Łchen Zugriffs┬Łzei┬Łten f├╝r alle Ker┬Łne, son┬Łdern wei┬Łter┬Łhin zwei CCX mit je 4 Ker┬Łnen, die via Infi┬Łni┬Łty Fabric zusam┬Łmen┬Łge┬Łschal┬Łtet sind. Nur, dass jeder CCX dann 16 MB L3-Cache haben wird statt nur 8 MB wie bei Zen 1.
Was steckt im I/OŌĆæDie?
Wie erw├żhnt hat AMD die f├╝r I/O zust├żn┬Łdi┬Łgen Kom┬Łpo┬Łnen┬Łten bei Rome in einen eige┬Łnen Chip aus┬Łge┬Łla┬Łgert. I/O wird bedeu┬Łten: Memo┬Łry-Con┬Łtrol┬Łler, PCI-Express Con┬Łtrol┬Łler, aber bei einem SoC wie Epyc auch SATA-Con┬Łtrol┬Łler, USB-Con┬Łtrol┬Łler, even┬Łtu┬Łell auch Netz┬Łwerk-MACs oder gan┬Łze Netz┬Łwerk-Con┬Łtrol┬Łler. Das wur┬Łde aber noch nicht verraten.

Und trotz┬Łdem. Sieht man sich das Die auf den gezeig┬Łten Fotos an, dann ist der Chip nur daf├╝r zu gro├¤; erheb┬Łlich zu gro├¤. Der Gro├¤┬Łteil eines her┬Łk├Čmm┬Łli┬Łchen Dies wird ohne┬Łhin vom Cache belegt. Das sind die auf Dieshots gleich┬Łfor┬Łmig erschei┬Łnen┬Łden Berei┬Łche, in denen die SRAM-Zel┬Łlen f├╝r die Caches lie┬Łgen. Unter┬Łstellt man, dass auch bei Zen 2 die L3-Caches m├Čg┬Łlichst nahe bei den Ker┬Łnen (also in den Chip┬Łlets) plat┬Łziert wer┬Łden, wes┬Łhalb ist dann der I/OŌĆæChip so rie┬Łsig? Dazu schweigt sich AMD lei┬Łder noch v├Čl┬Łlig aus.
Denk┬Łbar w├żre, dass AMD zus├żtz┬Łlich zu den L3-Caches, den jedes der 8 Chip┬Łlets besitzt, noch eine wei┬Łte┬Łre Cache┬Łstu┬Łfe vor┬Łge┬Łse┬Łhen hat, dem┬Łnach einen L4-Cache, der dann im I/OŌĆæChip ste┬Łcken k├Čnn┬Łte. Qua┬Łsi wie fr├╝┬Łher bei den Sockel-7-Board, wo zus├żtz┬Łlich zu den On-Die-Caches noch ein Cache auf dem Main┬Łboard plat┬Łziert war; hier dann eben nicht auf dem Main┬Łboard, son┬Łdern auf dem Chip┬Łtr├ż┬Łger. Doch ist das wahr┬Łschein┬Łlich? Bei einem Pro┬Łzes┬Łsor, des┬Łsen L3-Cache ohne┬Łhin schon ver┬Łvier┬Łfacht wur┬Łde? Zudem hat San┬Łdra kei┬Łnen L4-Cache aus┬Łge┬Łle┬Łsen (was aber nichts hei┬Ł├¤en muss, da San┬Łdra sicher┬Łlich noch kei┬Łne Rome-Unter┬Łst├╝t┬Łzung hatte).
Eben┬Łfalls denk┬Łbar w├żre, dass der L3-Cache nicht mehr in den Chip┬Łlets steckt, son┬Łdern im I/OŌĆæChip plat┬Łziert wur┬Łde. Dann w├╝r┬Łde des┬Łsen Gr├Č┬Ł├¤e ange┬Łsichts von 256 MB L3-Cache pas┬Łsen und AMD kann sie ja in Sli┬Łces a 16 MB orga┬Łni┬Łsiert haben. Aber m├╝ss┬Łten dann nicht die Chip┬Łlets wesent┬Łlich klei┬Łner sein, wenn sich dort kein gro┬Ł├¤er L3-Cache mehr befin┬Łdet? Eigent┬Łlich schon. Aller┬Łdings muss bedacht wer┬Łden, dass AMD die FPU von 128 auf 256 Bit auf┬Łge┬Łbohrt hat. Man erin┬Łne┬Łre sich an die Umstel┬Łlung von K8 auf K10, als AMD von einer 64 auf eine 128 Bit FPU ging, wie sehr das den Bereich der Ker┬Łne auf┬Łge┬Łbl├żht hat obwohl (oder weil) die Fer┬Łti┬Łgung mit 65 nm gleich geblie┬Łben war. Die neue 256-Bit-FPU bei Zen 2 gibt es sicher┬Łlich nicht umsonst. Ob die┬Łse allein aller┬Łdings erkl├ż┬Łren kann, dass die Chip┬Łlets so gro├¤ sind wie sie sind?
├£ber all das kann nat├╝r┬Łlich in unse┬Łrem Spe┬Łku┬Łla┬Łti┬Łons┬Łbe┬Łreich im Forum dis┬Łku┬Łtiert und debat┬Łtiert werden.
Links zum Thema:
- Web┬Łwatch und AMD-News zum Wochen┬Łen┬Łde (KW 47) ()
- Web┬Łwatch und AMD-News zum Wochen┬Łen┬Łde (KW 46) ()
- Giga┬Łbyte zeigt ers┬Łtes Ser┬Łver-Main┬Łboard f├╝r Rome mit PCI-Express 4.0 ()
- AMDs Zen 2 Rome kommt mit 64 Ker┬Łnen im Chip┬Łlet-Design ()
- AMD Zen 2 angeb┬Łlich mit 13 Pro┬Łzent IPC-Stei┬Łge┬Łrung ()
- Glo┬Łba┬Łle Ser┬Łver┬Łaus┬Łlie┬Łfe┬Łrun┬Łgen stei┬Łgen 2018 stark ŌĆö eine Chan┬Łce f├╝r AMD ()
- Offi┬Łzi┬Łell: AMDs Zen 2 wird bei TSMC in 7 nm gefer┬Łtigt ()