AMD Ryzen 7 1800X Review ŌĆō Teil 2
Tiefenanalyse der Architektur
Um zu unter┬Łsu┬Łchen, wie sich die Aus┬Łf├╝h┬Łrung von Befeh┬Łlen zwi┬Łschen Ryzen und ande┬Łren aktu┬Łel┬Łlen x86-Archi┬Łtek┬Łtu┬Łren unter┬Łschei┬Łdet, haben wir die Laten┬Łzen und Durch┬Łs├żt┬Łze ver┬Łschie┬Łde┬Łner Befeh┬Łle mit Hil┬Łfe von AIDA64 gemes┬Łsen und ver┬Łgli┬Łchen. Hier┬Łf├╝r wur┬Łden zus├żtz┬Łlich der Excava┬Łtor-Core in Bris┬Łtol Ridge (wel┬Łcher bei AMD als IPC-Ver┬Łgleichs┬Łba┬Łsis dien┬Łte) und Kaby Lake herangezogen.
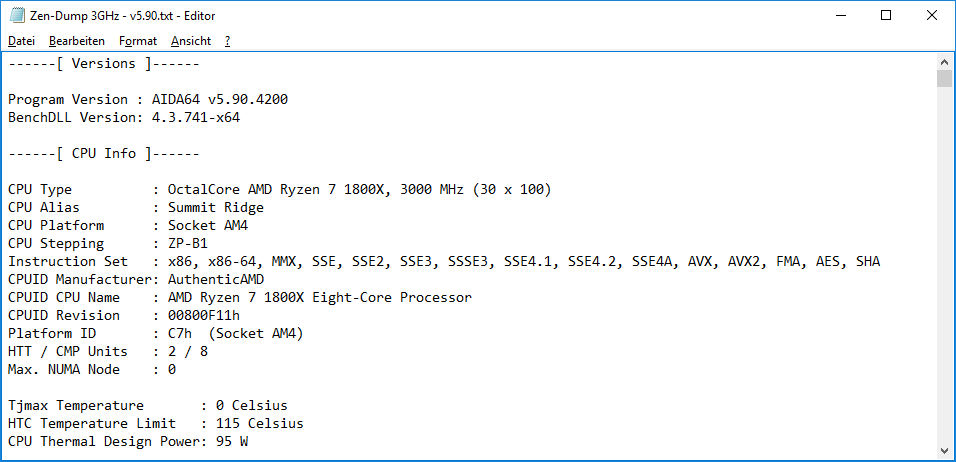
In die┬Łsen Ergeb┬Łnis┬Łsen sagt die Befehls┬Łla┬Łtenz aus, nach wie┬Łviel Takt┬Łzy┬Łklen ein fol┬Łgen┬Łder Befehl mit dem Ergeb┬Łnis des betrach┬Łte┬Łten Befehls wei┬Łter┬Łar┬Łbei┬Łten kann. Das spielt dann eine Rol┬Łle, wenn die Out-of-Order-Aus┬Łf├╝h┬Łrung des Pro┬Łzes┬Łsors und der Com┬Łpi┬Łler nicht in der Lage sind, die┬Łse Laten┬Łzen durch geeig┬Łne┬Łte Anord┬Łnung der Befeh┬Łle zu ŌĆ£ver┬Łste┬ŁckenŌĆØ. Die Aus┬Łwir┬Łkung auf die durch┬Łschnitt┬Łli┬Łche Rechen┬Łleis┬Łtung ist nicht so gro├¤ wie beim Durch┬Łsatz. Letz┬Łte┬Łrer bezif┬Łfert, wie vie┬Łle die┬Łser Befeh┬Łle pro Takt maxi┬Łmal gleich┬Łzei┬Łtig aus┬Łge┬Łf├╝hrt wer┬Łden k├Čn┬Łnen und stellt das obe┬Łre Limit des┬Łsen dar, was Out-of-Order-Aus┬Łf├╝h┬Łrung und der Com┬Łpi┬Łler beim Zusam┬Łmen┬Łstel┬Łlen des Pro┬Łgramm┬Łcodes aus┬Łnut┬Łzen k├Čn┬Łnen. Von den Befeh┬Łlen wur┬Łden zur Ver┬Łmei┬Łdung von Ver┬Łzer┬Łrun┬Łgen eini┬Łge Befeh┬Łle und Befehls┬Łkom┬Łbi┬Łna┬Łtio┬Łnen her┬Łaus┬Łge┬Łnom┬Łmen. Das betrifft z.B. die Befeh┬Łle f├╝r tri┬Łgo┬Łno┬Łme┬Łtri┬Łsche Funk┬Łtio┬Łnen (kei┬Łne star┬Łken Unter┬Łschie┬Łde), Zufalls┬Łzah┬Łlen┬Łge┬Łne┬Łra┬Łtor (sel┬Łten genutzt), CPUID (eben┬Łfalls sel┬Łten genutzt) und non-tem┬Łpo┬Łral Moves (dazu sp├ż┬Łter mehr).
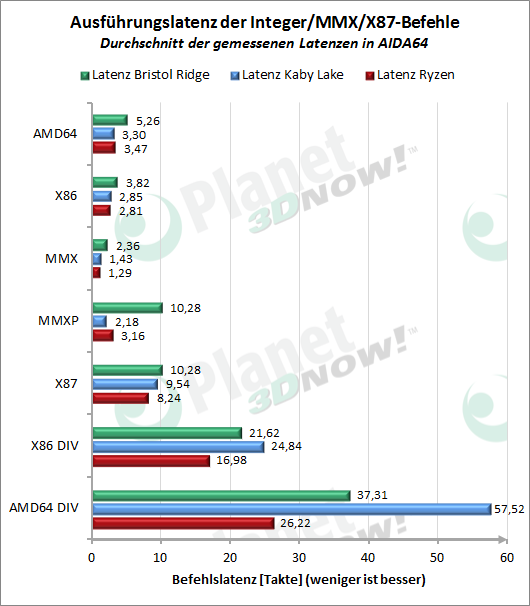
Wir zei┬Łgen hier f├╝r ver┬Łschie┬Łde┬Łne Befehls┬Łgrup┬Łpen jeweils ein Latenz- und ein Durch┬Łsatz-Dia┬Łgramm. Im ers┬Łten Bild ist zu sehen, dass die Laten┬Łzen der Inte┬Łger-Befeh┬Łle (AMD64, X86) und MMX-Befeh┬Łle beim Ryzen ├żhn┬Łlich zum Kaby Lake und deut┬Łlich nied┬Łri┬Łger sind als beim Excava┬Łtor-Core. Die klas┬Łsi┬Łchen x87-Floa┬Łting-Point-Befeh┬Łle zei┬Łgen leicht nied┬Łri┬Łge┬Łre Laten┬Łzen als selbst beim Kaby Lake. In den Inte┬Łger-Divi┬Łsi┬Łons-Befeh┬Łlen setzt sich Ryzen dage┬Łgen sicht┬Łbar ab. Das wirkt sich u.a. auf den CPU-Z-Bench┬Łmark (Per┬Łlin-Noi┬Łse-Berech┬Łnung) als auch Tri┬Łal Fac┬Łto┬Łring in Prime95 aus.
In den Durch┬Łsatz-Wer┬Łten die┬Łser Befeh┬Łle im zwei┬Łten Dia┬Łgramm fal┬Łlen die MMX-Wer┬Łte posi┬Łtiv auf. Die┬Łse Wer┬Łte k├Čn┬Łnen aber auch nur f├╝r einen gro┬Łben Ver┬Łgleich her┬Łhal┬Łten, da die Befeh┬Łle im real auf┬Łtre┬Łten┬Łden Befehls┬Łmix ver┬Łschie┬Łde┬Łner Soft┬Łware mit ganz ande┬Łren H├żu┬Łfig┬Łkei┬Łten auf┬Łtre┬Łten. Letz┬Łte┬Łre wer┬Łden bei┬Łspiels┬Łwei┬Łse in die┬Łsem Arti┬Łkel gezeigt.
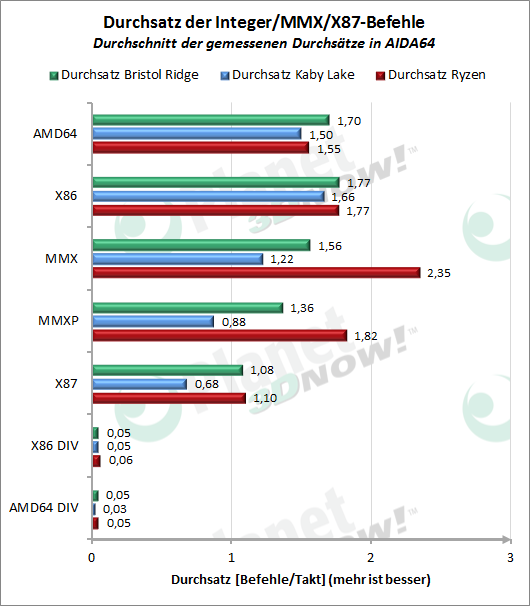
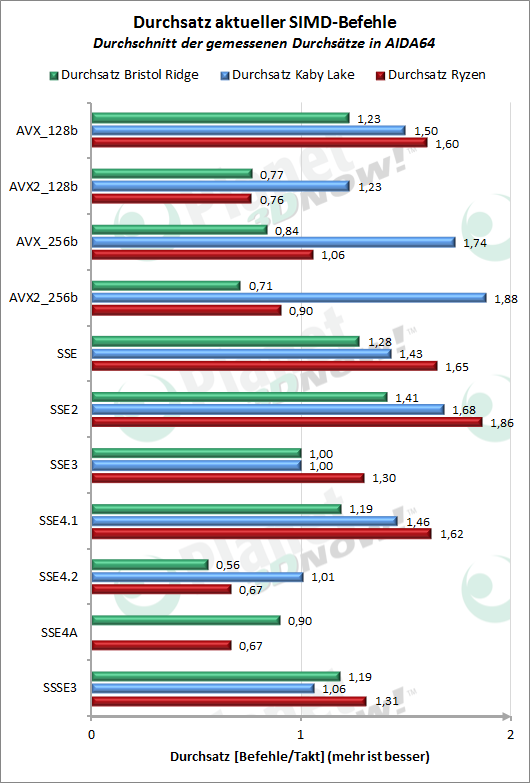
Die n├żchs┬Łten bei┬Łden Dia┬Łgram┬Łme befas┬Łsen sich mit den heu┬Łte ├╝bli┬Łchen SIMD-Erwei┬Łte┬Łrun┬Łgen. Da ist Ryzen von den Laten┬Łzen her gegen┬Ł├╝ber Kaby Lake gut auf┬Łge┬Łstellt und hat sich vor allem im Ver┬Łgleich zu sei┬Łnem Vor┬Łg├żn┬Łger Bris┬Łtol Ridge deut┬Łlich ver┬Łbes┬Łsert. Sei┬Łtens des Befehls┬Łdurch┬Łsat┬Łzes liegt Ryzen bei 128bittigen AVX-Befeh┬Łlen sogar etwas vor Kaby Lake, muss die┬Łsen Vor┬Łsprung aber bei AVX2 abge┬Łben. Das ist vor allem durch die gerin┬Łge Anzahl getes┬Łte┬Łter 128-bit-AVX2-Befeh┬Łle erkl├żr┬Łbar, wel┬Łche vor┬Łwie┬Łgend VPMASKMOV-Vari┬Łan┬Łten und Bit┬Łschie┬Łbe┬Łbe┬Łfeh┬Łle beinhal┬Łten. Bei 256bittigen AVX- und AVX2-Befeh┬Łlen war der deut┬Łli┬Łche Unter┬Łschied im Ver┬Łgleich zu Kaby Lake zu erwar┬Łten, da der Zen-Kern bekann┬Łter┬Łma┬Ł├¤en nur 128-bit brei┬Łte FPU-Ein┬Łhei┬Łten besitzt. Den┬Łnoch schafft es Ryzen ŌĆō trotz inter┬Łner Aus┬Łf├╝h┬Łrung von 256-bit-Befeh┬Łlen als zwei 128-bit Micro-Ops ŌĆō dabei eine gerin┬Łge┬Łre Durch┬Łschnitts┬Łla┬Łtenz vor┬Łzu┬Łwei┬Łsen. Im Ver┬Łgleich ist die gemit┬Łtel┬Łte 128┬Łbit-AVX-Latenz deut┬Łlich h├Čher, was aber von einem gr├Č┬Ł├¤e┬Łren Anteil getes┬Łte┬Łter Divi┬Łsi┬Łons- und Wur┬Łzel-Befeh┬Łle ver┬Łur┬Łsacht wird.
Bei den meis┬Łten Befehls┬Łer┬Łwei┬Łte┬Łrun┬Łgen der SSE-Fami┬Łlie mit maxi┬Łmal 128-bit Brei┬Łte kann Ryzen in bei┬Łden ŌĆ£Dis┬Łzi┬Łpli┬ŁnenŌĆØ punk┬Łten. Das ist vor allem f├╝r ├żlte┬Łre Soft┬Łware interessant.
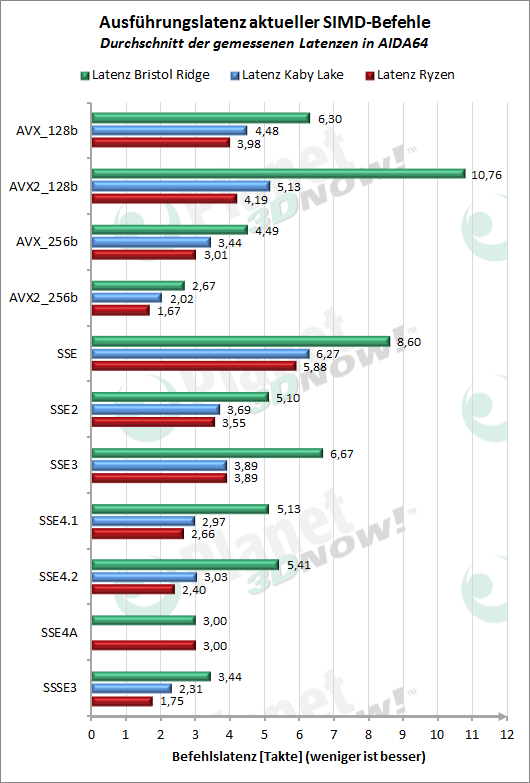
In den letz┬Łten bei┬Łden Dia┬Łgram┬Łmen sind die meis┬Łten der vie┬Łlen Spe┬Łzi┬Łal┬Łbe┬Łfehls┬Łer┬Łwei┬Łte┬Łrun┬Łgen zusam┬Łmen┬Łge┬Łfasst. Nur in einem der Pro┬Łzes┬Łso┬Łren vor┬Łhan┬Łde┬Łne Erwei┬Łte┬Łrun┬Łgen wur┬Łden von uns dabei weg┬Łge┬Łlas┬Łsen. Da die┬Łse Befehls┬Łer┬Łwei┬Łte┬Łrun┬Łgen oft nur in spe┬Łzi┬Łel┬Łler Soft┬Łware ver┬Łwen┬Łdet wer┬Łden, k├Čn┬Łnen sie zwar ent┬Łspre┬Łchen┬Łde Aus┬Łrei┬Ł├¤er gut erkl├ż┬Łren, aber nicht viel ├╝ber die gene┬Łrel┬Łle Leis┬Łtung der Pro┬Łzes┬Łso┬Łren aus┬Łsa┬Łgen. Hier ste┬Łchen im Wesent┬Łli┬Łchen die Bit-Mani┬Łpu┬Łla┬Łti┬Łons-Befeh┬Łle her┬Łvor (ABM, BMI, BMI2, POPCNT), wo Ryzen gute Wer┬Łte lie┬Łfert, als auch die AES-Befeh┬Łle, wel┬Łche z.B. den hohen Durch┬Łsatz in ent┬Łspre┬Łchen┬Łden Bench┬Łmarks (bspw. AES-Sub┬Łtest in Geek┬Łbench) erkl├ż┬Łren. Nicht ent┬Łhal┬Łten sind auch die Befeh┬Łle f├╝r non-tem┬Łpo┬Łral Loads und Stores, wel┬Łche m├Čg┬Łli┬Łcher┬Łwei┬Łse zu gerin┬Łge┬Łrer Per┬Łfor┬Łmance in Ashes of the Sin┬Łgu┬Łla┬Łri┬Łty f├╝hr┬Łten. In AIDA64 wird deren Latenz und Durch┬Łsatz u. a. in der Kom┬Łbi┬Łna┬Łti┬Łon NT Load + NT Store gemes┬Łsen. Mit ├╝ber 700 Tak┬Łten ist die Latenz dabei fast dop┬Łpelt so hoch als bei Kaby Lake. Neben der star┬Łken Ska┬Łlen┬Łver┬Łzer┬Łrung im Dia┬Łgramm ist hier auch der Rea┬Łli┬Łt├żts┬Łbe┬Łzug frag┬Łlich, da zwi┬Łschen und nach die┬Łsen Befeh┬Łlen noch ande┬Łrer Code aus┬Łge┬Łf├╝hrt wer┬Łden w├╝rde.
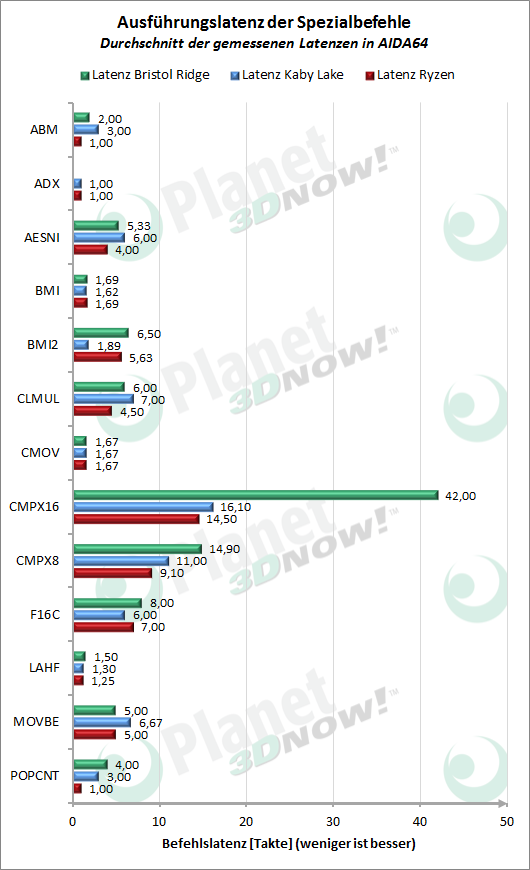
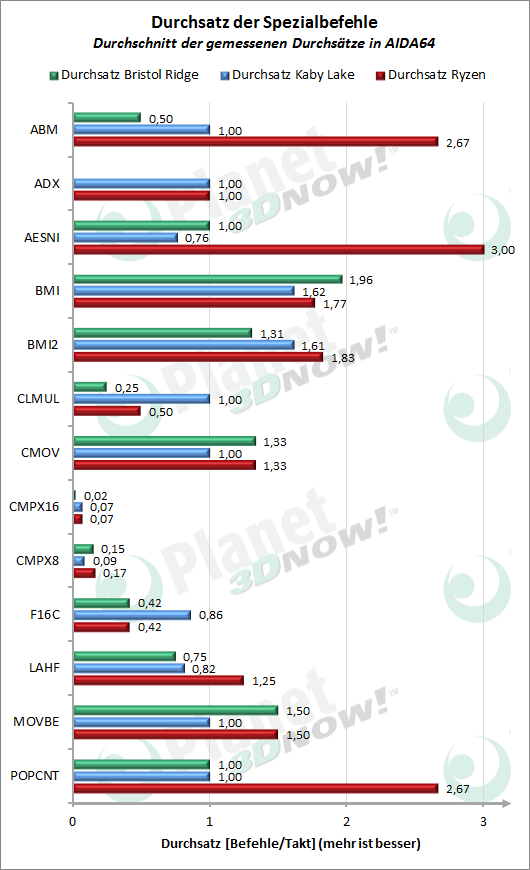
Ins┬Łge┬Łsamt zeigt sich der Zen-Kern inner┬Łhalb der Ryzen-Pro┬Łzes┬Łso┬Łren auch auf die┬Łser Ebe┬Łne als flott und durchsatzstark.