|
FORUM AKTUELL
PREISTICKER
- Hardware, Software, ...

- Home-Cinema, HiFi ,...

- Monitore, TFTs, ...

- DVDs, CDs, ...

- Smartphones, Tablets, ...

- Sonderangebote

|
|
|
News-SucheDiese Suchfunktion durchforstet alle Meldungen, die auf der Startseite zu lesen waren. Die Reviews, der FAQ-Bereich und das Forum werden nicht tangiert.
- Um das Forum zu durchsuchen, bitte hier klicken.
- Um die Downloads zu durchsuchen, bitte hier klicken.
Ergebisse: Seite 2 von 25
Nächste Seite: 1 (2) 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Mittwoch, 31. Oktober 2012
20:09 - Autor: Opteron Nachdem AMD erst am Montag bekannt gab (wir berichteten), 2014 Opterons auf ARM-Basis auf den Markt bringen zu wollen, gab es gestern auf der ARM-TechCon-2012 Details zu der Kernarchitektur von ARMs 64-Bit-Architektur ARMv8, die dort letztes Jahr vorgestellt wurde (wir berichteten). War es anfangs nicht klar, ob AMD einen eigenen Chip mit ihrem Know-How entwerfen wollten, besteht nun Klarheit in diesem Punkt. AMD wird nämlich als Lizenznehmer der frisch präsentierten ARM-Cortex-A50 Familie genannt. Das bedeutet, dass AMD einfach das Chip-Design von ARM übernimmt und sich nicht selbst ans Reißbrett setzt. Neben AMD werden auch noch die Firmen Broadcom, Calxeda, Hisilicon, Orange, Samsung und ST-Microelectronics genannt. Im Moment besteht die Cortex A50-Familie aus zwei Chips, dem A57 und dem A53. Ähnlich wie AMDs Bulldozer und Bobcat teilen sich beide Chips in unterschiedliche Stromverbrauchs- und Leistungsgruppen ein. Während der A53 als weltkleinster 64-Bit-Chip für einen besonders stromsparenden Betrieb ausgelegt ist und nur eine In-Order-Architektur aufweist, soll der A57 in eher anspruchsvolleren Szenarien zum Einsatz kommen, was man auch an der 3-issue Out-of-Order-Architektur feststellen kann:
Architekturvergleich zwischen A53 und A57ARM nennt die beiden Ansätze "big" und "little". Dabei ist anzumerken, dass ARM auch den gemischten Betrieb vorsieht, z.B. ein Quad-Core-Chip aus zwei A53- und zwei A57-Kernen, wobei das Betriebssystem je nach Last und Leistungsbedarf die entsprechenden Threads auf die jeweiligen Kerne verteilt. Dies ist für den Desktop-/ Smartphonemarkt interessant. Für den Server-Betrieb sieht ARM aber folgende Setups vor:
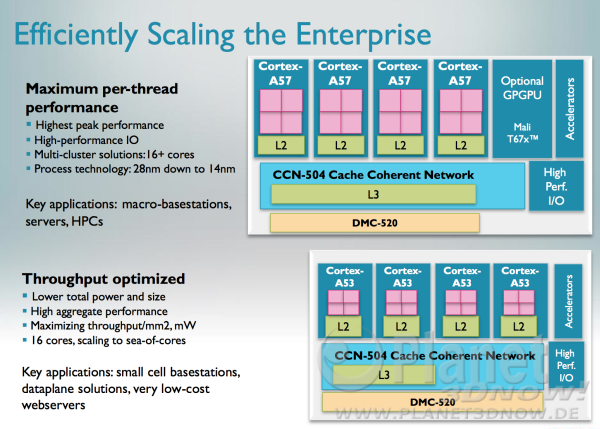
Enterprise-Kerne auf A57- und A53-BasisWie man sieht, sind jeweils vier ARM Kerne zu einer Art Cluster gruppiert, in dem sich die 4 Kerne den L2-Cache teilen. Dieses Setup erinnert auch an AMDs Kabini-APU (wir berichteten). Jeweils vier solcher Cluster sind wiederum auf einem Chip mit zusätzlich L3 und Interconnects etc. vorhergesehen, wodurch insgesamt 16 Kerne zur Verfügung stünden. Man darf aber nicht vergessen, dass dies nur Vorschläge sind. Außerhalb der ARM-Kerne kann jeder Lizenznehmer sein eigenen Süppchen kochen. AMD hat z.B. bereits angekündigt, ihren eigenen Interconnect "Freedom-Fabric" zu integrieren. Selbiger scheint auch AMDs Trumpf im Ärmel zu sein. Nachdem man wie alle anderen Firmen auch nur die originalen ARM-Kerne übernimmt, bleibt nur der bessere Interconnect als Alleinstellungsmerkmal. Im Gegensatz zur Konkurrenz, wie z.B: Calxedas ECX-1000 SoC (mehr dazu hier), dessen Aufbau in folgendem Bild zu sehen ist ... :
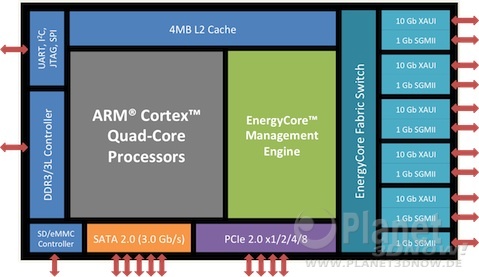
ECX-1000... muss man keine extra SATA, PCIe und Interconnect-Anschlüsse unterbringen, nach außen führen und verkabeln. Jeder I/O-Datenverkehr läuft schnell und einfach einzig über AMDs Freedom-Fabric. Das vereinfacht die Verkabelung, die Festplatten-Organisation, spart Strom, da man sich viele Sata- und PCIe-Kontroller sparen kann und erhöht durch die Trennung von CPU und I/O die Ausfallsicherheit. Ist zum Beispiel ein Calxeda-SoC defekt, sind auch die Daten der angeschlossenen Festplatten unzugänglich. Außerdem ist auch der Mischbetrieb mit x86-CPU-Karten möglich. Fazit Die Verwendung von 08/15-Standard-ARM-Kernen enttäuscht etwas auf den ersten Blick. Schließlich hätte AMD mehr Know-How im Bereich des Prozessordesigns zu bieten als die restlichen Mitbewerber zusammen. Auf dem zweiten Blick hat AMD aber schon durch den eigenen Interconnect einen starken Vorteil, der anfangs sicherlich ausreichen sollte, um sich von der Konkurrenz absetzen zu können. Im Gegenzug spart man sich auch die kompletten Entwicklungskosten für einen ARM-Kern. Vor dem Hintergrund von AMDs aktueller Entlassungswelle und knapper Personaldecke ein nicht zu unterschätzender Vorteil.
Quelle: Pressemitteilung
Links zum Thema:
>> Kommentare     
Mittwoch, 19. September 2012
16:06 - Autor: OpteronWie wir schon früher berichtet hatten, wird es auch für den FM2-Sockel wieder CPU-Modelle mit den altbekannten Athlon II- und Sempron-Namen geben. Nun wurden durch die CPU-Support-Liste von bereits gelisteten Mainboards (siehe unsere frühere Meldung) auch einige Modelle bekannt. Demnach wird es drei Athlon II Modelle geben, wobei das Spitzenmodell 750K auch über einen freien Multiplikator verfügen wird. Anwender, die sich gerade nach einem günstigen und modernen Untersatz für Quad-Core-Prozessoren umschauen, könnten demnach auf Ihre Kosten kommen. In der folgenden Tabelle haben wir alle bisher bekannten FM2-Modelle zusammengefasst: | CPU | AMD A6-5300 | AMD A6-5400K | AMD A8-5500 | AMD A8-5600K | AMD A10-5700 | AMD A10-5800K | Athlon II X4 730 | Athlon II X4 740 | Athlon II X4 750K | | Codename / Revision | Trinity / A1 | Trinity / A1 | Trinity / A1 | Trinity / A1 | Trinity / A1 | Trinity / A1 | Trinity / A1 | Trinity / A1 | Trinity / A1 | | OPN | AD5300OKA23HJ | AD540KOKA23HJ | AD5500OKA44HJ | AD560KWOA44HJ | AD5700OKA44HJ | AD580KWOA44HJ | AD730XOKA44HJ | AD740XOKA44HJ | AD750KWOA44HJ | | Sockel | FM2 | FM2 | FM2 | FM2 | FM2 | FM2 | FM2 | FM2 | FM2 | | Threads | 2 | 2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | | Taktfrequenz (Turbo) | 3,4 (3,7) GHz | 3,6 (3,8) GHz | 3,2 (3,7) GHz | 3,6 (3,9) GHz | 3,4 (4,0) GHz | 3,8 (4,2) GHz | 2,8 (?) GHz | 3,2 (?) GHz | 3,4 (?) GHz | | Chipfläche/Diegröße | 246 mm² | 246 mm² | 246 mm² | 246 mm² | 246 mm² | 246 mm² | 246 mm² | 246 mm² | 246 mm² | | L2-Cache-Größe | 1 MB | 1 MB | 2 x 2 MB | 2 x 2 MB | 2 x 2 MB | 2 x 2 MB | 2 x 2 MB | 2 x 2 MB | 2 x 2 MB | | L3-Cache-Größe | / | / | / | / | / | / | / | / | / | | Speicherkanäle | 2xDDR3 | 2xDDR3 | 2xDDR3 | 2xDDR3 | 2xDDR3 | 2xDDR3 | 2xDDR3 | 2xDDR3 | 2xDDR3 | | Max. Speicherstandard | DDR3-1600 | DDR3-1866 | DDR3-1866 | DDR3-1866 | DDR3-1866 | DDR3-1866 | DDR3-1866 | DDR3-1866 | DDR3-1866 | | int. PCIe Leitungen | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | | TDP | 65 W | 65 W | 65 W | 100 W | 65 W | 100 W | 65 W | 65 W | 100 W | | Befehlssätze | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | SSEx/AES/AVX/FMA | | DirectX-Standard | DX11 | DX11 | DX11 | DX11 | DX11 | DX11 | -keine- | -keine- | -keine- | | Grafikeinheit | HD 7480D | HD 7540D | HD 7560D | HD 7560D | HD 7660D | HD 7660D | -keine- | -keine- | -keine- | | Shaderkerne | 128 | 192 | 256 | 256 | 384 | 384 | -keine- | -keine- | -keine- |
Links zum Thema:
>> Kommentare
Dienstag, 28. August 2012
23:10 - Autor: OpteronÜber einige Details, z.B. die AVX-Erweiterung, konnten wir ja bereits in unserer alten Nachricht vom 21. Juli berichten. Desweiteren haben sich unsere Spekulationen zum Cache-Aufbau und der FPU-Breite bewahrheitet. Erstens bekommt Jaguar wirklich einen 2 MB großen, gemeinsam genutzten L2-Cache, der in vier Kacheln à 512 kB unterteilt ist: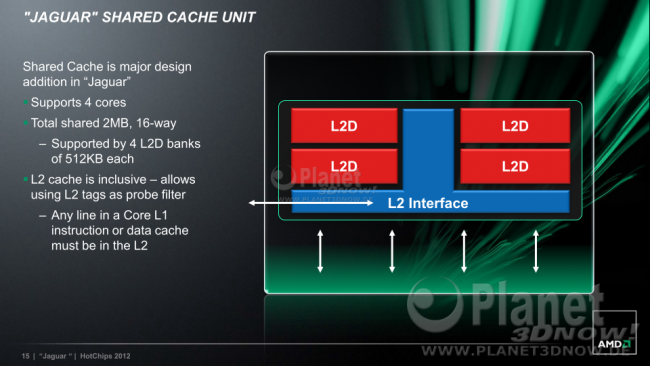 Ein einzelner Thread hat dadurch vollen Zugriff auf 2 MB, was v.a. der Single-Thread-Leistung zu Gute kommt. Außerdem ist der L2, ähnlich wie der L3 bei den aktuellen Intel-Prozessoren, inklusive organisiert. Das bedeutet zwar, dass insgesamt 2x32x4= 256kByte der 2 MB verloren gehen, dafür verbessert sich aber die Multi-Thread-Leistung und Inter-Prozess-Kommunikation, da alle Kerne über den gemeinsamen L2 den Status und den Inhalt der restlichen CPU-Kerne abfragen können. Zweitens bewahrheitete sich auch unsere Spekulation zur FPU. Diese wird wirklich von 64 Bit auf 128 Bit verbreitet. Für FPU-lastige Szenarien kann man also eine ähnliche Verbesserung wie vom K8 auf den K10 erwarten. Aber schauen wir uns das gute Stück erst einmal im Vergleich zum Bobcat an: 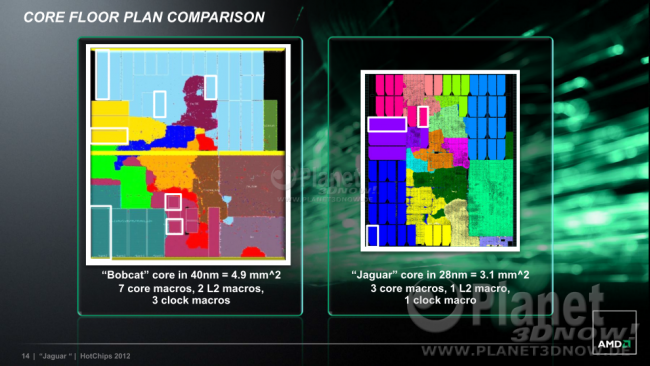
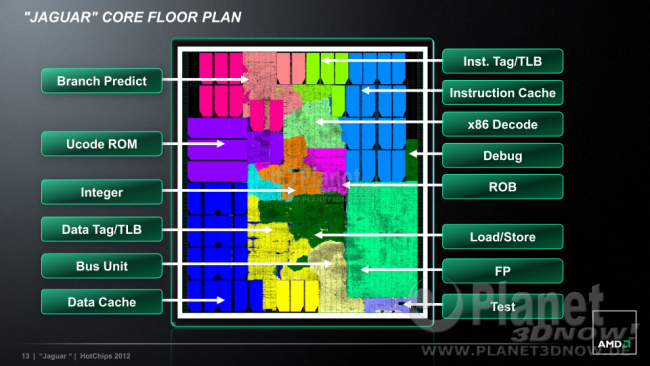
Auf den ersten Blick kann man eigentlich erst einmal nur den größeren Bereich der FPU bemerken, der sich schlicht durch die bereits erwähnte Verdoppelung auf 128 Bit erklärt. Interessant ist die Randnotiz am Bildende, dass Jaguar aus nur 3 unterschiedlichen Transistorenzellen-Designs besteht, während Bobcat noch 7 verschiedene Sorten benutzte. Das bedeutet, dass das Design einfacher auf andere Prozesse, z.B. zu Globalfoundries portiert werden könnte.
Für weitere Details ist man dann auf die nächsten AMD-Folien zu den Architektur-Infos angewiesen:  Im Folgenden fassen wir alle Informationen zusammen: 1. Front-End 1.1 x86-Dekoder-Einheit: Ähnlich wie die Intel-Chips seit der Conroe-Generation bekommt Jaguar auch einen Loop-Detection-Buffer spendiert, welcher die bereits dekodierten µOps von sich wiederholenden Schleifen-Instruktionen zwischenspeichert und somit die Dekodier-Einheit entlastet. Als Grund werden Stromspar-Maßnahmen angegeben, da der Dekoder in diesem Falle abgeschaltet werden kann. Aber natürlich bekommt man nebenbei auch einen Leistungsschub, da der kleine 32-Byte-Zwischenspeicher die µOps viel schneller liefern kann als der Dekoder. 1.2. Sonstiges
Wie auch in den anderen Kernabschnitten wurden einige Puffer vergrößert. Im Front-End-Fall ist dabei der Instruktion-Puffer zu nennen, der sich zwischen der Fetch- und Decoder-Einheit befindet. Zusätzlich wurde auch der Prefetcher für den L1-Instruktionscache verbessert. 2. Rechenwerke 2.1 Größere OoO-Puffer
Aus der "Viel-hilft-viel"-Schublade ist diese Verbesserung. AMD vergrößert beim Jaguar einige Puffer, die für die Out-of-Order-Ausführung zuständig sind. Solche Verbesserungen werden bei DIE-Shrinks immer gerne gemacht. 2.2. Integer-Divisor
Wie auch schon Bulldozer (aktiviert erst im Trinity, wir berichteten) oder auch Llano (wir berichteten) bekommt auch Jaguar eine Integer-Dividier-Einheit verpasst. Praktischerweise nimmt man einfach die des Llanos. 2.3 Sonstiges
Der Vollständigkeit halber wollen wir hier auch die schon in der Einleitung genannten 128-Bit-Fähigkeit der FPU-Pipelines nennen. 256 Bit AVX-Befehle werden dabei also wie schon aktuell beim Bulldozer in zwei Pakete à 128 Bit aufgeteilt. 3. Load/Store Einheit Lade- und Speicheroperationen erfuhren ebenfalls ein paar Verbesserungen, so wurde z.B. das Load to Store Forwarding (STLF), das dem ein oder anderen eventuell besser unter Intels Bezeichnung "Memory Disambiguity" bekannt ist, verbessert. Desweiteren wurden auch hier einige Puffer vergrößert und die Logik, welche die nächste µOp aus dem OoO-Puffer bestimmt, wurde verbessert. Adressierbarkeit
Ein kleines Detail mit eventuell großer Wirkung versteckt sich auf dieser eher unscheinbaren Folie:  Neben den bereits bekannten Details zu den unterstützten Befehlssatzerweiterungen sieht man, dass Jaguars Speicherkontroller 40 Bit adressieren. Bisher war das Limit bei 36 Bit, was für einen Prozessor der Jaguar Klasse eigentlich locker ausreicht, da die 36 Bit 64 GB bedeuten. Mit 40 Bit zieht man nun mit dem alten K8 gleich, der ebenfalls 1 Terabyte adressieren konnte. Aktuelle CPUs seit dem K10 adressieren aber bereits 48 Bit. Trotzdem dürfte damit klar sein, dass AMD den Jaguar-Kern mit an Sicherheit grenzender Wahrscheinlichkeit auch im Server-Bereich positionieren wird. 64 GB wären für Tablets, Notebooks, HTPCs und kleine Office-Rechner schließlich auch weiterhin noch genug. Pipeline-Vergleich Die Pipeline hat sich im Vergleich zum Bobcat fast nicht geändert, zuerst die Bobcat-Pipeline aus unserem Bobcat-Artikel: 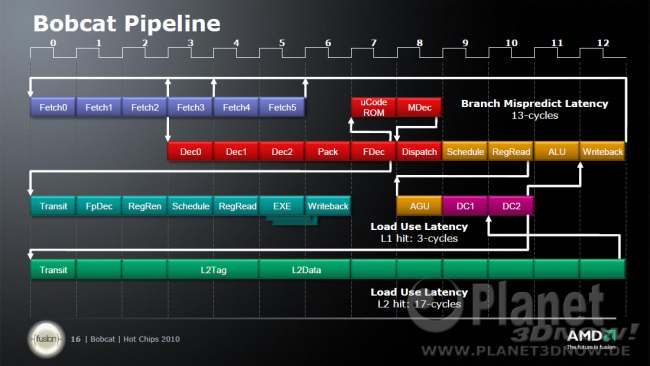 Und nun die Jaguar-Pipeline:  Wie man sieht gibt es zwei Neuerungen. Erstens gibt es eine zusätzliche Stufe am Ende der Dekodier-Einheit und dann zweitens eine weitere Stufe zum Registerlesen in der FPU. Letzteres ist vermutlich der 128-Bit-Verbreiterung geschuldet. Erster sicherlich aufgrund der Abfrage des Loop-Buffers nötig. Offiziell sind beide Pipelinestufen einer höheren Frequenz geschuldet. Das stimmt natürlich auch, denn wenn man beide Verbesserungen in bereits vorhandene Stufen zwängen hätte müssen, wäre das Design sicherlich nicht ausbalanciert gewesen. Im Endeffekt sind die beiden Zusatzstufen aber schlicht die Ursache der Mikroarchitektur-Verbesserungen und sicherlich kein anfängliches Designziel. Die L1D-Latenz bleibt weiterhin bei 3 Takten. Resultat Lohn der ganzen Mühen ist am Ende eine um >15% gestiegene IPC (1,10 statt 0,95): 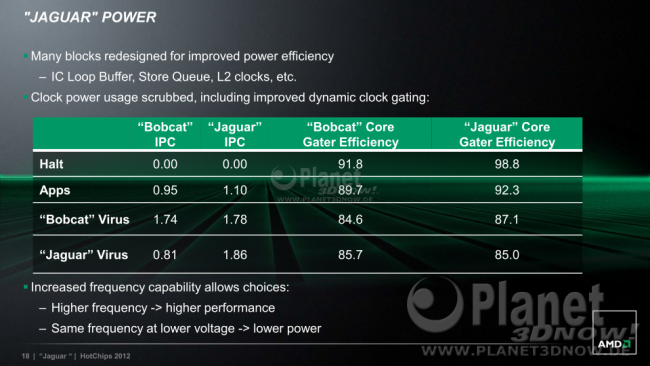 Damit bewegt man sich in K10-Regionen, allerdings wird ein Dual- bzw. Quadprozessor mit Jaguar-Kernen deutlich weniger Strom verbrauchen als man es von seinem Phenom II gewohnt ist. Genaue Informationen hierzu, oder zu den Taktraten, gibt es aber nicht. Zu Letzterem gibt es nur die grobe Info, dass sich 10% höhere Takte ggü. Bobcat bewerkstelligen ließen. Aktuell würde das für Jaguars Dual-Core-Version somit um die 1,9 Ghz bedeuten, da der aktuell schnellste Bobcat, der E2-1800, mit 1,7 Ghz läuft.
Fazit
Jaguar sieht nach einem runden, gelungenen Design aus. Viele Puffer wurden vergrößert, die FPU-Resourcen verdoppelt, AVX-Unterstützung nachgerüstet, ein schon lange bei Intel üblicher Loop-Cache eingebaut, das Cache-Design überholt und erstmals wird es auch eine Quad-Core-Version geben. Sollte es seitens TSMC keine Produktionsprobleme geben, sollte der Erfolg garantiert sein. Solange Intel seinen Atom-Nachfolger nicht auf dem Markt bringt, könnten die auf Jaguar basierenden APUs den blauen x86-Riesen eventuell sogar dazu zwingen, Sandy- oder Ivy-Bridge ULV-Typen zu verbilligten Konditionen anzubieten, um überhaupt ein Konkurrenzprodukt aufweisen zu können. Update 30.08.2012:
Gerade erreichte uns noch diese zusammenfassende Folie, die einen schnellen Überblick aller Verbesserungen ermöglicht und uns nun als Abschluss dienen soll: 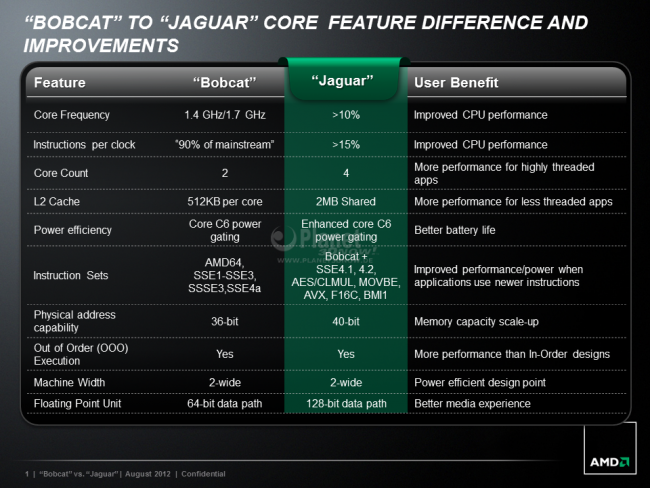 Den vollständigen Foliensatz zum Jaguar kann man in unserer Galerie finden. Links zum Thema:
>> Kommentare
Freitag, 24. August 2012
17:14 - Autor: Dr@WCCFtech hat einen Ausschnitt aus einem offenbar von AMD stammenden Produktleitfaden veröffentlicht, der einen Überblick über AMDs 2012-Desktop-Plattform geben soll. Neben den bereits bekannten APU-Modellen, die auch bereits in der freien Wildbahn gesichtet wurden, sind auch die ersten drei neuen FX-Prozessoren (Codename "Vishera" bzw. Orochi Revision C0) aufgeführt. Demnach würde das neue Spitzenmodell AMD FX-8350 mit acht Piledriver-Kernen (8 Integer-Kerne bzw. 4 Module) einen Basistakt von 4,0 GHz aufweisen, der im Turbomodus auf 4,2 GHz angehoben wird und dabei eine Leistungsaufnahme von 125 Watt (TDP) nicht überschreiten soll. Zudem wäre wohl der Sechskerner AMD FX-6300 (3,5 GHz / 4,1 GHz) und der Quad-Core AMD FX-4320 (4,0 GHz / 4,2 GHz) mit einer TDP von 95 Watt in Vorbereitung.
| CPU-Modell | TDP | Kerne / Module | Taktfrequenz
(Basis / Turbo) | L2-Cache | L3-Cache |
|---|
| AMD FX-8350 | 125 Watt | 8 / 4 | 4,0 GHz / 4,2 GHz | 4x 2 MiB | 8 MiB | | AMD FX-6300 | 95 Watt | 6 / 3 | 3,5 GHz / 4,1 GHz | 3x 2 MiB | 8 MiB | | AMD FX-4320 | 95 Watt | 4 / 2 | 4,0 GHz / 4,2 GHz | 2x 2 MiB | 8 MiB |
Übersicht der voraussichtlichen "Vishera"-ModelleAußerdem tauchen in dem Dokument weitere APU-Modelle der zweiten Generation (Codename "Trinity") für den Desktop auf, die wir mit den bereits bekannten Modellen im Folgenden zusammengestellt haben: | APU-Modell | TDP | CPU-Kerne
(Kerne / Module) | CPU-Taktfrequenz
(Basis / Turbo) | L2-Cache | AMD Stream
Prozessoren | GPU-Taktfrequenz | Unlocked |
|---|
| AMD A10-5800K | 100 Watt | 4 / 2 | 3,8 GHz / 4,2 GHz | 2x 2 MiB | 384 | 800 MHz | ja | | AMD A10-5700 | 65 Watt | 4 / 2 | 3,4 GHz / 4,0 GHz | 2x 2 MiB | 384 | 760 MHz | nein | | AMD A8-5600K | 100 Watt | 4 / 2 | 3,6 GHz / 3,9 GHz | 2x 2 MiB | 256 | 760 MHz | ja | | AMD A8-5500 | 65 Watt | 4 / 2 | 3,2 GHz / 3,7 GHz | 2x 2 MiB | 256 | 760 MHz | nein | | AMD A6-5400 | 65 Watt | 2 / 1 | 3,6 GHz / 3,9 GHz | 1 MiB | 192 | ? | nein | | AMD A4-5300 | 65 Watt | 2 / 1 | 3,4 GHz / 3,7 GHz | 1 MiB | 128 | ? | nein |
Übersicht der voraussichtlichen "Trinity"-ModelleQuelle: WCCFtech  Links zum Thema:
>> Kommentare
Donnerstag, 9. August 2012
17:03 - Autor: OpteronBereits von Llano verkaufte AMD Versionen mit abgeschaltenem Grafik-Part unter der altbekannten Athlon-Marke. Auch von Trinity wird es nun solche Sparmodelle geben und die Spar-Marke "Sempron" ist ebenfalls wieder mit dabei. Die Details haben wir in der folgenden Tabelle zusammengefasst: | CPU | AMD A-Series | AMD Athlon | AMD Sempron | | Codename | Trinity | Trinity | Trinity | | Sockel | FM2 | FM2 | FM2 | | Threads | 2 4 | 2 4 | 2 4 | | Herstellungsprozess | 32nm SOI/HKMG | 32nm SOI/HKMG | 32nm SOI/HKMG | | Chipfläche/Diegröße | 246 mm² | 246 mm² | 246 mm² | | L2-Cache-Größe Quad Cores | 2 x 2 MB | 2 x 2 MB | 2 x 1 MB | | L2-Cache-Größe Dual Cores | 1 MB | 1 MB | 1 MB | | Speicherkanäle | 2xDDR3 | 2xDDR3 | 2xDDR3 | | Max. Speicherstandard | DDR3-1866 | DDR3-1866 | DDR3-1600 | | int. PCIe Leitungen | 24x PCIe 2.1 | 24x PCIe 2.1 | 24x PCIe 2.1 | | Befehlsätze | alle bis zu FMA3 | alle bis zu FMA3 | alle bis zu FMA3 | | Integrierte DX-11 GPU | Ja | Nein | Nein | Positiv fällt auf, dass AMD nach wie vor bei den günstigeren Modellen keine Befehlssätze deaktiviert. Somit kann auch der kleine Sempron mit AVX-, FMA- und AES-Code betrieben werden. Einzig an der Cachegröße und der Speichergeschwindigkeit muss man Einbußen hinnehmen. Ein Quad-Core-Sempron mit 2 Modulen wird somit nur durch 2 x 1MB L2-Cache und maximal DDR3-1600 unterstützt. Außerdem fehlt natürlich die Grafikeinheit. Selbige ist beim Athlon-Modell das Einzige, auf das man verzichten muss. Ansonsten besitzt es die gleichen Merkmale wie die normalen A-Serien-APUs. Über einen möglichen Verkaufsstart ist nichts bekannt. Möglicherweise wird es die Modelle anfangs auch wieder nur für Großabnehmer geben. Quellen:
Link zum Thema: User News zu Llanos Athlon und Sempronmodellen>> Kommentare
Dienstag, 24. Juli 2012
15:54 - Autor: OpteronBisher wurden die Low-Power-Prozessoren sowohl bei Intel als auch bei AMD in den Befehlssätzen beschnitten. Es schien fast so, also ob sich beide Firmen stillschweigend geeinigt hätten, denn sowohl Ontario/Zacate mit Bobcat-Kernen als auch Intels Atom-Prozessoren unterstützten maximal SSSE3. Kein SSE4.1 oder 4.2, oder gar AVX. Dies ändert sich nun. AMDs kommender Mobilprozessor Kabini mit Jaguar-Kernen, der laut der aktuellen Roadmap für 2013 in 28 nm geplant ist, wird laut Aussage eines AMD-Compiler-Programmierer mit AVX-Unterstützung aufwarten können:
Zitat: | There are ISA changes as well like btver2 supports AVX, BMI. |
SSE4-Derivate werden nicht direkt erwähnt, allerdings ist auch von deren Support auszugehen, denn AVX ist eine Obermenge aller früheren Befehlssatzerweiterungen und stellt dadurch z.B. 3-Operand-Befehle aller vorherigen SSE-Befehle bereit, die nur für zwei Operanden ausgelegt waren. Deshalb ist die Funktionalität aller SSE-Befehle mit einer AVX-Unterstützung bereits gegeben und somit die Kompatibilität zu SSE denkbar einfach sicherzustellen. Aus diesem Grund wäre eine Nicht-Unterstützung der höheren SSE-Erweiterungen nach SSSE3, sehr verwunderlich. Des weiteren gibt es noch ein kleines Detail zur Hardwarekonfiguration. Die Entwickler änderten die Compiler-Optimierungs-Variable für den L2-Cache von 512 kB auf 2048 kB. Allerdings ist es höchst fragwürdig, ob die Jaguar-Kerne wirklich 2MB-L2-Cache pro Kern bekommen. Schließlich handelt es sich bei Jaguar um ein kostengünstiges Low-power-Design. 2 MB L2-Cache pro Kern würden selbst im platzsparenden 28nm-Prozess bei einem Quad-Core-Prozessor zuviel Fläche verbrauchen, wodurch die Produktion zu teuer werden würde. Worüber man spekulieren könnte, wäre vielmehr ein gemeinsamer, vereinigter L2-Cache für alle 4 Kerne einer Kabini-APU. Pro Kern bliebe es im Schnitt dann bei den schon bisher üblichen 512 kB. Dies wäre dann natürlich kein Höchstleistungs-Design, aber erstens ist die Bocat-Reihe eben keine Höchstleistungs-Architektur, zweitens läuft der L2-Cache der aktuellen Bobcats schon mit nur halbem Takt und drittens hätte man Vorteile in den immer noch verbreiteten Single-Thread-Last-Szenarien, da einem Thread die vollen 2 MB L2-Cache zur Verfügung stünden. Update 24.7.2012
Unser Forenmitglied tex_ hat sich den Code genau angesehen und festgestellt, dass dort in den Compiler-Änderungsbeschreibungen bereits eine komplette Befehlssatzübersicht zu finden ist (Link). Die Jaguar-Architektur unterstützt demnach alle Befehlssätze, die vor dem Erscheinen von AVX gebräuchlich waren, also SSE 4.1, SSE 4.2 und AES. Unsere obige Spekulation zu älteren Befehlssätzen war somit eigentlich unnötig, aber immerhin ist sie damit jetzt auch bestätigt. Was im Vergleich zu Bulldozer fehlt ist nur die FMAC-Fähigkeit der FPU. Diese ist aber für einen günstigen Einstiegsprozessor - selbst im nächsten Jahr - sicherlich noch nicht nötig. Ansonsten würde auch die FPU und damit der gesamte Chip zu groß werden, was sich negativ bei die Fertigungskosten auswirken würde und damit dem Ziel, einen günstigen Prozessor anbieten zu können, entgegenwirken würde. Alleine durch die bloße Verwendung von AVX darf man allerdings keine dramatische Leistungserhöhung erwarten. Auch wenn der Befehlssatz 256 Bit vorsieht, böte das gegenüber alten 64-Bit-Instruktionen keinen Vorteil, wenn die Rechenwerke diese z.B. nur in vier Takten zu je 64 Bit abarbeiten können. Um einen der oft gescholtenen Auto-Vergleiche zu bemühen: Ohne größere Motorumbauten ist der Effekt eines besseren Treibstoffes (z.B. Super-Plus statt Normalbenzin) eher gering. In etwa den ähnlichen Effekt wird man von den restlichen AVX-Verbesserungen (3-Operanden-Format und leicht kürzere Befehle, dank VEX-Präfix) erwarten können - zumindest solange AMD nicht auch etwas am Motor, d.h. den Rechenwerken ändert und diese z.B. auf 128 Bit erweitert. Genauere Informationen werden im August erwartet, wenn AMD die Jaguar-Architektur auf der Hotchips-Konferenz präsentiert.
Links zum Thema:
Quellen:>> Kommentare
Samstag, 21. Juli 2012
14:15 - Autor: OpteronBisher wurden die Low-Power-Prozessoren sowohl bei Intel als auch bei AMD in den Befehlssätzen beschnitten. Es schien fast so, also ob sich beide Firmen stillschweigend geeinigt hätten, denn sowohl Ontario/Zacate mit Bobcat-Kernen als auch Intels Atom-Prozessoren unterstützten maximal SSSE3. Kein SSE4.1 oder 4.2, oder gar AVX. Dies ändert sich nun. AMDs kommender Mobilprozessor Kabini mit Jaguar-Kernen, der laut der aktuellen Roadmap für 2013 in 28 nm geplant ist, wird laut Aussage eines AMD-Compiler-Programmierer mit AVX-Unterstützung aufwarten können:
Zitat: | There are ISA changes as well like btver2 supports AVX, BMI. |
SSE4-Derivate werden nicht direkt erwähnt, allerdings ist auch von deren Support auszugehen, denn AVX ist eine Obermenge aller früheren Befehlssatzerweiterungen und stellt dadurch z.B. 3-Operand-Befehle aller vorherigen SSE-Befehle bereit, die nur für zwei Operanden ausgelegt waren. Deshalb ist die Funktionalität aller SSE-Befehle mit einer AVX-Unterstützung bereits gegeben und somit die Kompatibilität zu SSE denkbar einfach sicherzustellen. Aus diesem Grund wäre eine Nicht-Unterstützung der höheren SSE-Erweiterungen nach SSSE3, sehr verwunderlich. Des weiteren gibt es noch ein kleines Detail zur Hardwarekonfiguration. Die Entwickler änderten die Compiler-Optimierungs-Variable für den L2-Cache von 512 kB auf 2048 kB. Allerdings ist es höchst fragwürdig, ob die Jaguar-Kerne wirklich 2MB-L2-Cache pro Kern bekommen. Schließlich handelt es sich bei Jaguar um ein kostengünstiges Low-power-Design. 2 MB L2-Cache pro Kern würden selbst im platzsparenden 28nm-Prozess bei einem Quad-Core-Prozessor zuviel Fläche verbrauchen, wodurch die Produktion zu teuer werden würde. Worüber man spekulieren könnte, wäre vielmehr ein gemeinsamer, vereinigter L2-Cache für alle 4 Kerne einer Kabini-APU. Pro Kern bliebe es im Schnitt dann bei den schon bisher üblichen 512 kB. Dies wäre dann natürlich kein Höchstleistungs-Design, aber erstens ist die Bocat-Reihe eben keine Höchstleistungs-Architektur, zweitens läuft der L2-Cache der aktuellen Bobcats schon mit nur halbem Takt und drittens hätte man Vorteile in den immer noch verbreiteten Single-Thread-Last-Szenarien, da einem Thread die vollen 2 MB L2-Cache zur Verfügung stünden. Update 24.7.2012
Unser Forenmitglied tex_ hat sich den Code genau angesehen und festgestellt, dass dort in den Compiler-Änderungsbeschreibungen bereits eine komplette Befehlssatzübersicht zu finden ist (Link). Die Jaguar-Architektur unterstützt demnach alle Befehlssätze, die vor dem Erscheinen von AVX gebräuchlich waren, also SSE 4.1, SSE 4.2 und AES. Unsere obige Spekulation zu älteren Befehlssätzen war somit eigentlich unnötig, aber immerhin ist sie damit jetzt auch bestätigt. Was im Vergleich zu Bulldozer fehlt ist nur die FMAC-Fähigkeit der FPU. Diese ist aber für einen günstigen Einstiegsprozessor - selbst im nächsten Jahr - sicherlich noch nicht nötig. Ansonsten würde auch die FPU und damit der gesamte Chip zu groß werden, was sich negativ bei die Fertigungskosten auswirken würde und damit dem Ziel, einen günstigen Prozessor anbieten zu können, entgegenwirken würde. Alleine durch die bloße Verwendung von AVX darf man allerdings keine dramatische Leistungserhöhung erwarten. Auch wenn der Befehlssatz 256 Bit vorsieht, böte das gegenüber alten 64-Bit-Instruktionen keinen Vorteil, wenn die Rechenwerke diese z.B. nur in vier Takten zu je 64 Bit abarbeiten können. Um einen der oft gescholtenen Auto-Vergleiche zu bemühen: Ohne größere Motorumbauten ist der Effekt eines besseren Treibstoffes (z.B. Super-Plus statt Normalbenzin) eher gering. In etwa den ähnlichen Effekt wird man von den restlichen AVX-Verbesserungen (3-Operanden-Format und leicht kürzere Befehle, dank VEX-Präfix) erwarten können - zumindest solange AMD nicht auch etwas am Motor, d.h. den Rechenwerken ändert und diese z.B. auf 128 Bit erweitert. Genauere Informationen werden im August erwartet, wenn AMD die Jaguar-Architektur auf der Hotchips-Konferenz präsentiert.
Links zum Thema:
Quellen:
>> Kommentare
Freitag, 27. April 2012
21:20 - Autor: MaksoHeute haben wir wieder ein paar Artikel zu den Themen Mainboards, CPUs, Grafik und Chipsätze für Euch zusammengetragen.
Mainboards
Mobile Prozessoren, Notebooks, Subnotebooks, Netbooks und Tablets
AMDIntelNetbooks und Nettops
Server, Prozessoren, Chipsätze, Speicher und Festplatten
Grafik
Sonstige News zu AMD, Intel, Chipbranche und Software
» Kommentare
Dienstag, 3. April 2012
23:21 - Autor: heikoschDie Zahl von Endgeräten, die durch ARM-Prozessoren beschleunigt werden, nimmt stetig zu. Während man hier nun vermuten könnte, dass dem Hersteller vor allem die Sicherheit bei Verbindungen unter den Tablets und Smartphones wichtig ist, gehen die Ideen weiter. Im multimedialen Wohnzimmer sind alle Geräte vernetzt. Auf der letztjährigen IFA zeigten die Hersteller von TV-Geräten, wie man Tablets und sogenannte Smart-TVs miteinander verbindet. Hinzu kommen Spielekonsolen. Bis jetzt muss man sich auf die Sicherheitsprotokolle des heimischen Netzwerks verlassen. Im Geschäftsumfeld ist das Thema Sicherheit aber noch entscheidender.
Das Joint Venture von ARM (40 % Anteil), Gemalto (30 %) und Giesecke & Devrient (30 %) nimmt neben den Privat- auch Geschäftskunden ins Auge. Die Sicherheitstechniken für die verbundenen Geräte basieren dabei auf bestehenden Technologien der einzelnen Parteien und soll weiter verfeinert werden.ARM selbst möchte seine ARM-TrustZone-Sicherheitstechnologie, die bereits in die Prozessoren der Cortex-A-Serie integriert ist, als Basis zur Entwicklung einer Trusted Execution Environment, kurz TEE, nutzen. Dahinter versteckt sich eine sichere Arbeitsumgebung zur Ausführung von Software, die die erweiterte Hardware-Sicherheit mit Software-Schnittstellen nach Industrie-Standard verbinden wird. Der Schritt ARMs erinnert doch recht stark an das, was Intel derzeit zu bieten hat. Nach dem Kauf McAfees zu einem Preis von knapp 7,7 Mrd. US-Dollar stellte man die DeepSAFE-Technik vor. Diese agiert zwischen dem Betriebssystem und nahe der Hardware. In diesem Zusammenhang sei auch die in die Prozessoren integrierte Anti-Theft-Technologie noch einmal erwähnt. Durch ein Abo bei einem Sicherheitsanbieter lässt sich diese Funktion der Prozessoren nutzen. Im Falle eines Diebstahls kann das Gerät durch ein Kill-Kommando des Sicherheitsanbieters unbrauchbar gemacht werden. Verschlüsselte Festplatten sind trotzdem unabdingbar in dieser Situation. Die beiden weiteren Parteien des Joint Venture arbeiten schon längere Zeit mit ARM zusammen. Sie bieten Sicherheitslösungen für Regierungen, die Finanz- und Mobilindustrie an. Das sind schon einmal gute Voraussetzungen. Die drei Firmen bringen neben den finanziellen Mitteln auch Patente, Software und Arbeitskräfte in das Projekt ein. Ob man von den Entwicklungen dieses Joint Ventures viel zu sehen bekommen wird, ist fraglich. Bereits in einem letzten Interview fielen die Worte, dass sehr viele Leute ARM-Technik nutzen, es nur niemand wirklich wahrnimmt. Auffällig unauffällig könnte man die Arbeit ARMs bezeichnen. Durch die Kompatibilität zum kommenden Microsoft Windows 8 wird sich in diesem Zusammenhang aber womöglich einiges ändern. Quelle: Computerworld - ARM sets up joint venture for common security standard for connected devices Links zum Thema:
>> Kommentare
Donnerstag, 1. März 2012
14:38 - Autor: heikoschBis jetzt hält sich Microsoft zu Details bezüglich Windows On ARM noch etwas zurück. Während der Consumer Electronics Show 2012 (CES 2012) konnte man das laufende System während einer Präsentation zwar in Aktion sehen, aber noch nicht ausprobieren. Auf dem derzeit stattfindenden Mobile World Congress 2012 (MWC) spricht man hingegen bereits von Entwicklerplattformen. Nach der etwas mageren Vorstellung auf der CES gibt Lance Howarth, ARM-Marketing-Vizepräsident, Rückendeckung. Das Potenzial des Betriebssystems sei groß und stelle eine große Chance für ARM dar.
Bis jetzt machte Microsoft zwar immer mal wieder einen kleinen Ausritt abseits der bekannten x86/x64-Plattform, stellte die Bemühungen aber immer wieder ein, wenn es um ein Desktop-Betriebssystem ging. Durch rapide steigende Verkaufszahlen im Bereich Tablets und Smartphones, wird diesem Markt aber eine große Zukunft vorausgesagt. Die Resonanz überrascht dabei nicht nur die Endkunden, sondern auch ARM selbst, die die Referenzdesigns für Kunden wie NVIDIA, Apple oder Qualcomm bereitstellen.Laut Howarth breche Windows On ARM, kurz WOA, die Wintel-Architektur. Damit ist die vorangegangene enge Zusammenarbeit Microsofts und Intels gemeint. Bereits im letzten Jahr kristallisierte sich heraus, dass dort nicht mehr alles rund läuft. Entwicklerkonferenzen wurden zeitgleich abgehalten, von Koordination und Teamwork wenig zu sehen. Nach Aussage Howarths steht auch eine auf die ARM-Architektur optimierte Office-Version an. Die Bedienung soll sowohl über Metro, als auch mit dem Desktop-Modus möglich sein. Bereits Anfang Februar stellte Microsofts Leiter der Abteilung Windows in einem Blog-Eintrag klar, dass man WOA auf vielen Geräten sehen wird - Tablets, Laptops, Ultrabooks und Desktops. Bis auf Entwicklerplattformen ist von Desktopsystemen aber noch nicht viel zu sehen. Ebenso ist eine Version für ARM-basierte Geräte (noch) nicht verfügbar. Der Download der Consumer Preview ist für Produkte auf Basis der x86/x64-Architektur gedacht. Nach Angaben ARMs habe man bereits 270 Partner, die das Referenzdesign verwenden. Acht Millionen Chips sollen im letzten Jahr in die Gehäuse von Geräten gewandert sein, ein Drittel davon in Telefone. Zu den Kunden zählen auch Größen wie Apple und Google. Die Bewahrung von Geheimnissen eines jeden Kunden steht im Vordergrund. ARM-Marketing-Chef Howarth betitelt seine Firma als Schweiz der Halbleiterwelt. Die Partnerschaften basieren auf Vertrauen.
Obwohl Intel mit seiner neuen Generation von Atom-Chips mit dem Codenamen Medfield aktuell wieder auf den Markt drängt, sei man ungefähr zwei Generationen hinter ARM, was die Energie-Effizienz angeht. ARM beschäftigt weltweit rund 2.000 Mitarbeiter. Dabei sollen zeitweise sechs davon zur direkten Zusammenarbeit mit Microsoft in Seattle gewesen sein. Dabei stand die Entwicklung von Windows Mobile und anderen Betriebssystemen im Vordergrund. Schlussendlich konstatiert Howarth, dass ARM trotz seiner hohen Verbreitungsrate immer noch eine relativ unbekannte Größe beim Endkunden ist - "We're everywhere, but nobody knows it.". Quelle: Computerworld - Windows on ARM will be 'huge,' exec says Links zum Thema:
>> Kommentare
Dienstag, 28. Februar 2012
17:51 - Autor: Dr@Bereits gestern haben wir über Preisanpassungen für die CPUs AMD FX-6100 und FX-8120 berichtet. Heute hat uns AMD darüber informiert, dass die FX-Prozessoren weitere Verstärkung Anfang März erhalten sollen. Konkret handelt es sich dabei um den Sechskerner AMD FX-6200 (drei Module mit sechs Interger-Kernen) und den Quad-Core AMD FX-4170 (zwei Module mit vier Integer-Kernen) mit einen Basis Takt von 3,8 bzw. 4,2 GHz, die beide in die 125-Watt-TDP-Klasse eingruppiert wurden. Beide CPUs verfügen zudem über Turbo CORE, was eine automatische Übertaktung einzelner Kerne erlaubt, wenn ein entsprechender TDP-Spielraum vorhanden ist. Der FX-6200 kann dabei seine Kerne maximal auf 4,1 GHz und der FX-4170 auf maximal 4,3 GHz beschleunigen. Alle weiteren technischen Daten entsprechen den anderen Modellen der FX-Serie, sodass jedem Modul ein 2 MiB großer L2-Cache zur Verfügung steht. Zudem können alle Module auf den 8 MiB großen L3-Cache zugreifen.Zu den angepeilten Preisen schweigt sich AMD noch aus. | Modell | CPU Base | CPU Turbo
CORE | CPU Max
Turbo | TDP | Cores | L2-Cache | Price USA | Price GER |
|---|
| FX-8150 | 3,6 GHz | 3,9 GHz | 4,2 GHz | 125 W | 8 | 8 MiB | $245 | 242,16 | | FX-8120 | 3,1 GHz | 3,4 GHz | 4,0 GHz | 125 W | 8 | 8 MiB | $185 | 162,47 | | FX-6200 | 3,8 GHz | 3,8 GHz | 4,1 GHz | 125 W | 6 | 6 MiB | ? | 152,90 | | FX-6100 | 3,3 GHz | 3,6 GHz | 3,9 GHz | 95 W | 6 | 6 MiB | $145 | 120,44 | | FX-4170 | 4,2 GHz | 4,2 GHz | 4,3 GHz | 125 W | 4 | 4 MiB | ? | 122,44 | | FX-4100 | 3,6 GHz | 3,7 GHz | 3,8 GHz | 95 W | 4 | 4 MiB | $115 | 94,85 |
Deutsche Preise laut geizhals.at: Jeweils günstigster Preis lieferbarer BOXED-Versionen eines vertrauenswürdigen ShopsQuelle: AMD Links zum Thema:
>> Kommentare
Donnerstag, 12. Januar 2012
22:17 - Autor: MaksoHeute haben wir wieder ein paar Artikel zu den Themen Mainboards, CPUs, Grafik und Chipsätze für Euch zusammengetragen.
Mainboards
Mobile Prozessoren, Notebooks, Subnotebooks, Netbooks und Tablets
Server, Prozessoren, Chipsätze, Speicher und Festplatten
Grafik
Sonstige News zu AMD, Intel, Chipbranche und Software
» Kommentare
Dienstag, 10. Januar 2012
18:10 - Autor: Sefegiru[3DCenter] 
[Au-Ja!]
[ComputerBase]
[HardTecs4U]
[Hardwareluxx]
[PC Games Hardware]
[Shareware4U]
>> Kommentare
Dienstag, 20. Dezember 2011
15:02 - Autor: Dr@Als "vorgezogenes Weihnachtsgeschenk" hat AMD heute seine Produktpalette an A-Serie-APUs (Accelerated Processing Unit) einer Runderneuerung unterzogen. Unter den neuen Desktop-Modellen befinden sich die ersten beiden APUs mit offenem Multiplikator, was dem geneigten Kunden das Übertakten der x86-Kerne und auch der GPU erleichtern soll. Allerdings segeln diese Modelle nicht mehr unter der Bezeichnung Black Edition, wie sie von den Athlons und Phenoms bekannt war, stattdessen sind sie anhand eines "K"s am Ende der Modellnummer erkennbar. Mit der derzeit schnellsten APU AMD A8-3870K wird die garantierte Taktfrequenz der vier x86-Kerne auf die psychologisch wichtige Marke von 3,0 GHz erhöht, die integrierte Grafikeinheit Radeon HD 6550D bleibt hingegen unangetastet. Die 400 Stream-Prozessoren werden weiterhin mit 600 MHz betrieben. Bei der zweiten APU mit offenem Multiplikator der AMD A6-3670K takten die vier CPU-Kerne mit 2,7 GHz und die 320 Stream-Prozessoren der integrierten Radeon HD 6530D nach wie vor mit 444 MHz. Laut AMD sollen sich die CPU-Kerne der beiden K-Modelle, die der 100-Watt-TDP-Klasse zugeordnet wurden, um bis zu 500 MHz und der Grafikkern um bis zu 200 MHz übertakten lassen. Wie viel sich aus den K-Modellen herauskitzeln lässt, werden wir in Kürze selber überprüfen können.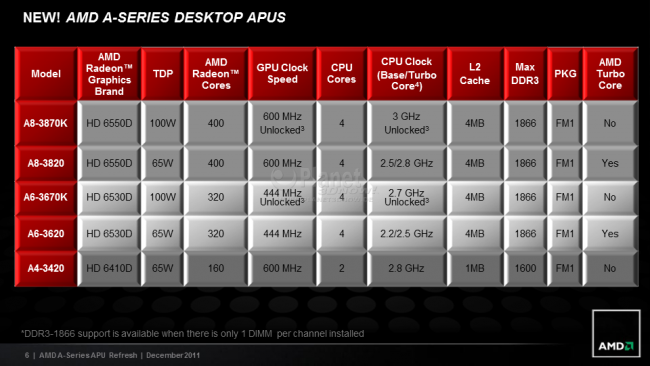 Bild anklicken um zu den anderen Folien zu gelangen Auch bei den 65-Watt-Modellen gibt es ein Takt-Update zu vermelden. Die beiden Quad-Core-Modelle AMD A8-3820 und A6-3620 besitzen gegenüber ihren Vorgängern einen um 100 MHz erhöhten Grund- und Turbotakt. Auch hier hat sich bei den verbauten integrierten Radeon-Grafikeinheiten nichts verändert. Abschließend führt AMD mit der A4-3420 APU ein weiteres Dual-Core-Modell mit einer TDP von 65 Watt ein. Neue Features bringt das Refresh keine auf den Tisch. Auch die neuen Modelle lassen sich per AMD Dual Graphics mit einer diskreten Radeon-Grafikkarte zusammenschalten, um so eine höhere Grafikleistung zu erzielen. Zudem können die APUs der A-Serie neben den bekannten Einstellungen zur Video-Nachbearbeitung im VECC (VISION Engine Control Center, ehemals Catalyst Control Center) auch die AMD Steady Video Technologie nutzen, um verwackelte Videoaufnahmen zu stabilisieren. 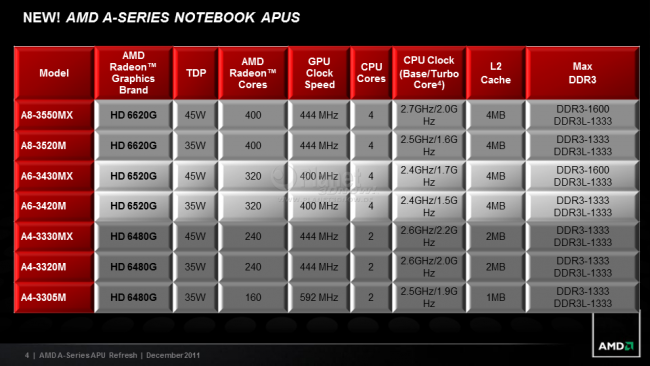 Auch bei den mobilen Versionen hat AMD etwas an der Taktschraube gedreht, was ebenfalls in 100 MHz mehr Standard- und Turbotakt bei den CPU-Kernen resultiert.Die neuen APUs selbst und Produkte, die auf ihnen basieren, sollen in den kommenden Wochen verfügbar werden. Quelle: Pressemitteilung Links zum Thema:
>> Kommentare
Donnerstag, 15. Dezember 2011
23:51 - Autor: Nero24Am heutigen Tage hat Microsoft für das Betriebssystem Windows 7 einen Hotfix veröffentlicht, der die Probleme beheben soll, die sein jüngstes OS in Kombination mit einem AMD FX-Prozessor hat, die Lasten optimal auf die in Modulbauweise gefertigten Kerne zu verteilen, sodass am Ende die optimale Leistung dabei herauskommt. Bereits im Vorfeld der AMD FX "Bulldozer" Präsentation hatte AMD darauf hingewiesen, dass der Scheduler von Windows 7, der die Prozesse bzw. die Threads auf die vorhandenen Kerne verteilt, suboptimal arbeitet für den Bulldozer. Wie man sieht ist Windows 7 die Modulbauweise und das CMT-Multithreading des Bulldozers nicht bekannt, verteilt die Threads wahllos wie bei einem herkömmlichen Multi-Core Prozessor. Als Folge davon kann der Turbo-Modus nie einzelne Kerne optimal beschleunigen und die Stromsparfeatures nie ganze Teilsegmente zweck niedrigerem Stromverbrauch stilllegen. Der Scheduler von Windows 8 dagegen soll das bereits berücksichtigen. Einige Publikationen haben das bereits nachgewiesen, wir selber hatten in unserem Review noch keine Gelegenheit, Tests auf Windows 8 durchzuführen. Der heute von Microsoft veröffentlichte Hotfix für den Scheduler soll das Zuordnungsproblem der Threads nun dahingehend lösen, dass der Bulldozer nicht mehr als Prozessor mit 8 gleichberechtigten Kernen verwaltet wird, sondern als Quad-Core Prozessor mit Simultaneous Multi-Threading "SMT", so wie die Intel Core i7 Prozessoren zum Beispiel. Leider ist unser regulärer AMD FX gerade zu Grafiktests in Deutschland unterwegs, sodass uns unsere Referenzplattform für einen Test nicht zur Verfügung steht. Daher muss hier ein privater AMD FX-6100, ein 6-Kerner (3-Moduler) mit 3,3 GHz Basis- und 3,9 GHz Turbo-Takt, als Versuchskaninchen herhalten. Auf die Schnelle daher ein paar Benchmarks, wo wir der Meinung waren, dass eventuelle Verbesserungen am deutlichsten sichtbar sein könnten:  Die Werte sind alarmierend! Auf Basis dieses Ergebnisses können wir zum aktuellen Zeitpunkt nur eindringlich davor warnen, den Hotfix KB2592546 zu installieren. Die Leistung steigt weder bei Single-, noch bei Multithreading-Anwendungen. Teilweise fallen die Resultate sogar erheblich schlechter aus! Bei kurzem logischen Nachdenken wird auch klar wieso. Der Versuch, mehr Leistung aus dem Bulldozer zu holen, indem man ihn wie einen Prozessor mit SMT alias HyperThreading behandelt, muss scheitern. Bei einem HyperThreading-Prozessor teilen sich zwei logische Kerne einen physischen. Das heißt, der Scheduler versucht zu vermeiden, dass Threads auf zwei logischen Kernen eines echten Kerns laufen und verteilt sie falls möglich lieber auf zwei echte Kerne. Beim Bulldozer jedoch - siehe AMDs Grafik oben - wäre es ausdrücklich erwünscht, dass die Threads innerhalb eines Moduls laufen, damit der Turbo aktiviert wird, die Threads den shared L2-Cache nutzen können und der Rest schlafen gelegt werden kann. Der Patch geht also genau in die falsche Richtung. So bleibt aktuell nur zu sagen: Ziel verfehlt, Patch bitte umgehend wieder zurückziehen und die Sache nochmal durchdenken! Update 1
Auf Leserwunsch wurde noch ein Benchmark gefahren mit extrem FPU-lastiger Auslegung in Kombination mit wenig Threads. Windows 7 SP1 Original:
 Windows 7 SP1 Bulldozer-Scheduler-Hotfix:
 Der Turbo-Modus war in beiden Fällen an und es wurde davon abgesehen, Threads auf irgendwelchen Kernen oder Modulen festzupinnen, da dies auch der normale User nie tun wird. Hier - da extrem SIMD/FPU-lastig - bringt der Scheduler-Patch in der Tat etwas. Aber lohnt es sich, hier auf der FPU/SIMD-Seite 4000 statt 3900 Kiloknoten/s mitzunehmen, wenn auf der anderen Seite (INT/ALU) 2200 statt 3300 KB/s zu Buche stehen?! Links zum Thema: -> Kommentare
Donnerstag, 17. November 2011
21:04 - Autor: MaksoHeute haben wir wieder ein paar Artikel zu den Themen Mainboards, CPUs, Grafik und Chipsätze für Euch zusammengetragen.
Mainboards
Mobile Prozessoren, Notebooks, Subnotebooks, Netbooks und Tablets
IntelNetbooks und Nettops
Server, Prozessoren, Chipsätze, Speicher und Festplatten
Grafik
Sonstige News zu AMD, Intel, Chipbranche und Software
AMDIntelChipbranche allgemeinSoftware
» Kommentare
Ergebisse: Seite 2 von 25
Nächste Seite: 1 (2) 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
|
|
|
Nach oben
|
|









Diesen Artikel bookmarken oder senden an ...