Diese Suchfunktion durchforstet alle Meldungen, die auf der Startseite zu lesen waren. Die Reviews, der FAQ-Bereich und das Forum werden nicht tangiert.
- Um das Forum zu durchsuchen, bitte hier klicken. - Um die Downloads zu durchsuchen, bitte hier klicken.
Ergebisse: Seite 1 von 9
Nächste Seite: (1) 23456789
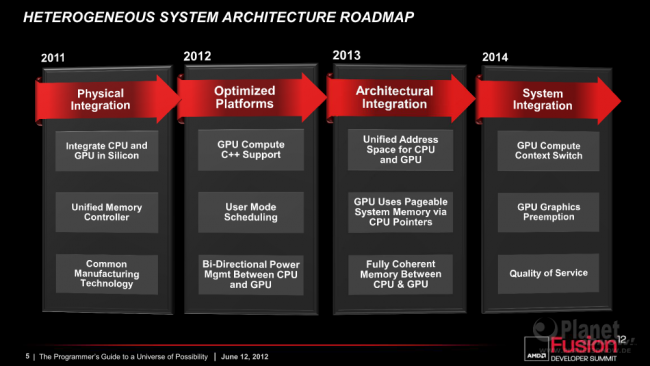
Zum Auftakt des AMD Fusion Developer Summit 2012 (AFDS) hat AMDs Corporate Fellow Phil Rogers die Gründung des Industriekonsortiums Heterogeneous System Architecture (HSA) Foundation bekannt gegeben. Zu den Gründungsmitgliedern gehören neben AMD und ARM, deren Beteiligung sich bereit im letzten Jahr abzeichnete, auch die SoC-Schwergewichte Imagination Technologies, MediaTek Inc. sowie Texas Instruments (TI). Ziele der HSA Foundation sind die Definition und Förderung eines offenen, auf Standards basierenden Ansatzes für das heterogene Computing, bei dem die Rechenlast möglichst optimal auf alle im System vorhandenen Prozessoren bzw. Recheneinheiten eines System-on-a-Chip (SoC) verteilt werden soll.
Hierzu definiert die Heterogeneous System Architecture unter anderem ein neues Speichermodell, bei dem sämtliche Recheneinheiten im selben Adressraum arbeiten, sodass das bisher kostspielige, aber notwendig Hin- und Herkopieren der Daten nicht länger notwendig ist. Zusammen mit dem neuen, vereinfachten Programmiermodell soll es Entwicklern ermöglicht werden, leichter die Fähigkeiten moderner CPUs, GPUs und SoCs, die unterschiedlichste Recheneinheiten auf einem Die vereinen, zu nutzen, was wiederum einer höheren Energieeffizienz zu Gute kommen soll. Mit den bereitgestellten Spezifikationen, Entwicklertools, SDKs, Bibliotheken, Dokumentationen, Trainingskursen, Support und vielem mehr will die HSA Foundation ein breites, unterstützendes Ökosystem erschaffen, welches die Implementierung innovativer Anwendungen vereinfacht und somit für das notwendige Interesse der Softwareentwickler und deren Unterstützung sorgen soll.
AMD gibt der HSA Foundation dazu den HSA Referenzprogrammierleitfaden sowie die erarbeiteten Spezifikationen für die HSA Hardware System Architecture und HSA Software System Architecture samt einer ersten Kapitalspritze an die Hand. Zudem will das Unternehmen die Standardbibliothek HSA Bolt library implementieren und zugleich der Open-Source-Bewegung die notwendigen Technologien zur Kompilierung und Ausführung bereitstellen.
Zitat: Phil Rogers, HSA Foundation President and AMD Corporate Fellow
"HSA moves the industry beyond the constraints of the legacy system architecture of the past 25-plus years that is now stifling software innovations. By aiming HSA squarely at the needs of the software developer, we have designed a common hardware platform for high performance, energy efficient solutions. HSA is unlocking a new realm of possibilities across PCs, smartphones, tablets and ultrathin notebooks, as well as the innovative supercomputers and cloud services that define the modern computing experience."
Als Initiator und treibende Kraft plant AMD alle notwendigen Optimierungen für HSA an der eigenen Hardware bis 2014 vorgenommen zu haben.
Die Komplexität der Programmierung heterogener Systeme verhinderte bisher einen breiten Einsatz, weshalb sich die Anzahl an GPU-beschleunigten Anwendungen nach wie vor in überschaubaren Grenzen hält. HSA zusammen mit den bereitgestellten Bibliotheken reduziert diese Komplexität jetzt stark, sodass nicht länger ausschließlich wenige Experten heterogene Systeme programmieren können. Zudem lässt sich durch die Verwendung der Bibliotheken die Entwicklungszeit reduzieren. Die Standardbibliothek HSA Bolt library stellt zum Beispiel optimierte Routinen für allerhand Standardanwendungsfälle bereit. Die HSA Bolt library ist dabei so angelegt, dass sie auf allen System genutzt werden kann, die zu HSA kompatibel sind. Allgemein wurde bei der Definition der einzelnen HSA-Komponenten großer Wert auf die Portabilität der Anwendungen gelegt, weshalb die Programmierung unabhängig von der Zielhardware erfolgen kann. Lediglich der HSA Finalizer und der HSA Kernel Driver sind herstellerspezifisch.
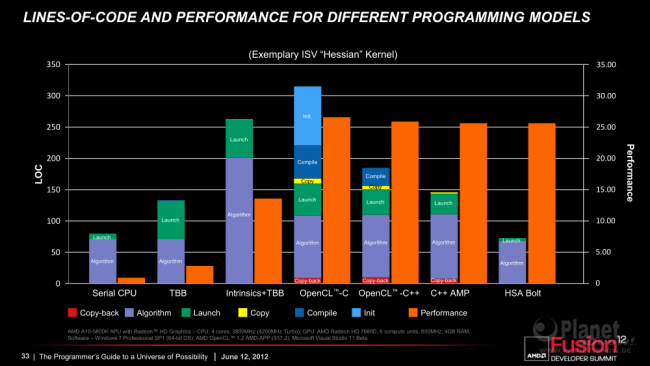
Am nachfolgenden Beispiel möchte AMD aufzeigen, dass durch HSA die Programmierung von heterogenen Systemen ähnlich einfach sein soll, wie für serielle Prozessoren heute. Dazu wird die notwendige Anzahl an Code-Zeilen für unterschiedliche Programmiermodelle verglichen und zusätzlich die erzielte Performance angegeben. Natürlich hängt auch weiterhin die erreichbare Performance davon ab, wie gut sich die Algorithmen parallelisieren lassen. Beim hier verwendeten Beispiel "Hessian"-Kernel ist dies ganz offenbar der Fall.
Abschließend wurden nochmals alle anderen Unternehmen der Industrie eingeladen, sich an der HSA Foundation zu beteiligen. Intel und NVIDIA steht die Tür also weiterhin offen. Sowohl Apple als auch Intel halten Anteile an Imagination Technologies und sind somit zumindest indirekt schon jetzt beteiligt. Ein industrieweiter Standard, der von allen Schwergewichten unterstützt wird, wäre in jedem Fall wünschenswert.
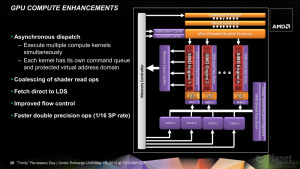
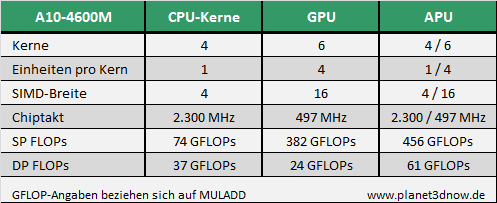
Zum Launch der ersten APUs von AMD wurde immer wieder hinterfragt, warum der GPU-Teil keine Unterstützung für Berechnungen mit doppelter Genauigkeit bietet. Schließlich preist das Unternehmen seine Accelerated Processing Units (APUs) damit an, dass der auf dem Die verbaute "Discrete Class" Grafikkern auch für andere Berechnungen (GPGPU-Computing) als das reine Redering von Computerspielen herangezogen werden kann. Während es im normalen Endkundenmarkt durchaus verschmerzbar ist, dass Berechnungen mit doppelter Genauigkeit nicht auf dem GPU-Teil der APU ausgeführt werden können, so ist es für wissenschaftliche Anwendungen fast schon Pflicht. Zwar existieren dort noch andere Anforderungen, die von den aktuellen APUs nicht erfüllt werden (z. B. ECC), allerdings wird beispielsweise bereits ein Supercomputer auf APU-Basis für Forschungszwecke auf dem Gebiet des "Heterogeneous Computing" genutzt. Zudem würden sich die Entwickler sicherlich freuen, wenn sie ihre Codes bereits auf ihrem Notebook oder Desktop-Rechner testen könnten und AMD allgemein beim Funktionsumfang eine konsistente Plattform bereitstellt. Dazu zählt eben auch, dass alle GPUs für Berechnungen mit doppelter Genauigkeit herangezogen werden können. Einen ersten Schritt dahingehend hat das Unternehmen mit der neuen GCN-Architektur getan, denn alle darauf basierenden GPUs unterstützen Double Precision (DP).
Entsprechend dieser Folien ist der Grafikteil von "Trinity" jetzt also auch dazu in der Lage, Berechnungen mit doppelter Genauigkeit auszuführen, wenn auch lediglich mit 1/16 der Rechenleistung, die für einfache Genauigkeit (Single Precision) erreicht wird. Damit liegt die theoretische DP-Peak-Leistung der GPU von 24 GFLOPs unterhalb der mit den FPUs der CPU-Kerne erreichbaren 37 GFLOPs. Damit ist die Auslagerung von DP-Berechnungen auf den Grafikkern der APU in den meisten Fällen wohl nicht sinnvoll. AnandTech konnte dies auch anhand der Ausgabe von clinfo bestätigen (siehe Artikel-Kommentare).
Nicht System on a Chip sondern Supercomputer on a Chip - so könnte Intel den neuen Prozessor betiteln, denn um nichts weniger handelt es sich bei dem, was Dr. Rajeeb Hazra (Intels General Manager für Technical Computing) in die Linse hält. Errinnert sich noch jemand an Larrabee? Ein ehrgeiziges Projekt, mit dem Intel in den Grafikmarkt gegen AMD und Nvidia in den Ring steigen wollte. Ende 2009 - Anfang 2010 sollte er kommen, basierend auf x86-Kernen statt Shadern. Diese Kerne, Nachfahren des als Pentium-S bekannten P54C, sollten zu Dutzenden die Aufgaben einer GPU übernehmen. Intel maßte sich gar an, das Ende der Rasterisation einzuläuten, eben der Technik, nach der alle Grafikkarten rechnen. Stattdessen wollte man Raytracing marktfähig machen. Ein großer Vorteil sollte zudem sein, dass man Larrabee neben Grafikaufgaben auch mit x86-Programmcode füttern könnte. Von alledem ist heute nichts zu sehen.
Intel musste schnell einsehen, dass ihr Ansatz nicht konkurrenzfähig war, zu langsam, zu stromhungrig war der Chip. In Folge dessen strich man das Projekt für den Endkundenmarkt und verteilte an einige Forschungseinrichtungen Testgeräte. Damit sollte die Softwareentwicklung vorangetrieben werden, bis Larrabee 2 marktreif ist. Intel sprach davon, dass man mindestens einen ausgereiften 32-nm-Prozess benötige, um ein ausgereiftes Produkt liefern zu können.
Knights Corner kommt nun in 22 nm und soll AMD und NVIDIA im Markt für High Performance Computing Anteile abschlagen. Hier werden in letzter Zeit immer öffter auch GPUs eingesetzt. Warum jetzt Supercomputer on a Chip? Knights Corner basiert wie Larrabee auf Pentium-P54C-Kernen - vermutlich 64 an der Zahl - zu Zeiten als dieser Kern noch als CPU käuflich zu erwerben war, führte die Top500-Liste der Supercomputer ein System namens ASCII Red von Intel an. Er erreichte eine Rechenleistung von 1 Teraflops DP (Double Precision), eben diese Marke hat Knights Corner auch erreicht. Selbstredend handelt es sich dabei nicht mehr um den Pentium S von damals, so wurde hier einiges überarbeitet. Der neue alte P54C-Kern im Knights Corner beherscht vierfach SMT, 512 bit breite Register und mit LNI (Larrabee New Instructions) auch FMA3.
1 Teraflop DP ist verglichen mit Larrabee, der die TFlop-Grenze nur mit Single Precision erreichte, ein gewaltiger Sprung. Damit erreicht das Konzept erstmals konkurrenzfähige Werte, denn zu Zeiten von Larrabee versägte AMDs Radeon HD 5870 mit 2,7 Teraflops SP den Intelspross, mit doppelter Genauigkeit hingegen erreicht AMD mit der Radeon 6970 "nur" 676 Gigaflops. Zudem soll Intels Lösung anders als normale GPUs relativ "unempfindlich" von der Blockgröße arbeiten. Je nach dem wie groß diese ausgelegt ist, rechnen die bisherigen GPUs mal schneller, mal langsamer. Nicht so Knights Corner, was Intel auf der Supercomputer-Konferenz bereits demonstrieren konnte. Bis zur Veröffentlichung des Chips im dritten Quartal kommenden Jahres können AMD und NVIDIA mit ihren neuen Architekturen noch nachlegen, dann wird es interessant.
Nachdem in der uns wohl bekannten x86-Welt seit AMDs x86-64-Erweiterung von 2002 das 64-Bit-Zeitalter angebrochen ist, schickt sich nun auch der vielleicht größte x86-Konkurrent ARM an, ebenfalls gleichzuziehen. Auf der zur Zeit stattfindenden ARM TechCon gab der Hersteller nun Details seiner neuen, zu x86-inkompatiblen ARMv8-Architektur preis. Ähnlich wie im x86-Ökosytem wird es auch bei ARM zwei kompatible Betriebsmodi für 32 und 64 Bit geben, AArch64 and AArch32.
Im Gegensatz zu AMD oder Intel stellt ARM keine Chips her, sondern definiert nur die Technologie, d.h. hauptsächlich den Befehlssatz, verkauft aber auch vorgefertigte Chipdesigns. Je nach gekaufter Lizenz werden die ready-to-use CPU-Designs einfach in einen kombinierten Handychip zusammen mit einem Grafik und I/O Teil des Lizenznehmers, z.B: Apple, integriert, oder auch komplett verändert. Hauptsache es wird der aktuelle ARM Befehlssatz verstanden und richtig verarbeitet, genauso wie auch im x86-Bereich der x86-Befehlssatz von allen x86-kompatiblen Prozessoren unterstützt werden muss.
In vielen Mobiltelefonen, wie z.B. in Apples iPhone oder auch den meisten Android-Handys verrichtet eine ARM-CPU den Dienst, d.h. in der Masse ist ARM bereits angekommen. Nun schickt man sich durch den 64-Bit-Mode aber an, neue Segmente, abseits des Mobilbereichs, zu erschließen. Bereits vor längerer Zeit wurden Rufe nach stromsparenden, kleinen Servern auf Intel-Atom- oder eben ARM-Basis laut. Dabei war ARMs fehlender 64-Bit-Modus allerdings ein Hemmschuh, da nur maximal 4 GB RAM adressiert werden können. Zwar gibt es im nun alten ARMv7 Standard auch einen 40-Bit-Adressmodus, dieser wurde von den Serverherstellern aber eher als Notlösung angesehen. Moderne Tablet-PCs haben auch bereits jetzt schon 1 GB Hauptspeicher, womit ein Reißen der 4 GB Hürde in nicht allzu langer Zeit abzusehen war. Der jetzt vollzogene Schritt ist damit nur logisch.
Man darf gespannt sein, wie sich das Marktgefüge in Zukunft verändert. Da ARM sowohl softwareseitig durch Microsofts Windows 8 ARM Unterstützung, als auch hardwareseitig durch NVIDIAs ARM-Kombichips mit CPU und GPU Teil (Tegra, ähnlich AMDs Fusion APU Konzepts) große Unterstützung durch Marktschwergewichte erfährt, stehen die Zeichen für ARMs Zukunft weiter auf Wachstumskurs. Sowohl AMD als auch Intel werden sich in Acht nehmen müssen, um keine Marktanteile zu verlieren.
Fertige Produkte wird man allerdings erst in ein paar Jahren sehen können. Produktankündigungen sind für 2012 geplant, Prototypen erst für 2014 vorgesehen.
Die Neuerungen und Features im Schnelldurchlauf:
31x 64-Bit-General-Purpose-Register für Skalar-INT
32x 128-Bit-Register für FPU, SIMD, Cryptography
Double Precision Support
Volle IEEE754-2008 Kompatibilität
Konstante Instruktionslänge von 32 Bit
Neue Instruktionen für Hardware Kryptographie (AES, SHA-1, SHA-256)
Graphisch und mit einem Rückblick auf die alten Standards, sieht das ganze dann so aus:
Im Juni zeichnete sich bereits ab, dass es mit einem Launch der AMD FX-Serie Prozessoren (Codename "Zambezi") im zweiten Quartal nichts werden würde, obwohl AMD dieses Zeitfenster vor Analysten auf seinem Financial Analyst Day im November 2010 nannte. Später sprach man lediglich von "early summer" für die Desktop-Versionen und "late summer" für die Serverversionen. Aber auch diesen Zeitplan konnte AMD nicht einhalten, was auf der Computex 2011 erneut zu einer Verschiebung des offiziellen Zeitfensters für einen Launch führte. Hier bestätigte das Unternehmen am 1. Juni erstmals die Verspätung. Als neuer Zeitplan wurde ausgegeben, dass die AM3+-Mainboards in 30 Tagen, also Anfang Juli, auf den Markt kommen sollten und die Verfügbarkeit der Boxed-Versionen (PIB) von den AMD FX-Serie Prozessoren wurde für "late summer" angekündigt. Dies präzisierte Rick Bergman noch auf 60 bis 90 Tage ausgehend vom 1. Juni, was einen Launch im August nahelegt. Heute wissen wir, dass AMD diesen Zeitplan auch nicht einhalten konnte.
X-bit labs und unsere Partnerseite HT4U wollen jetzt unabhängig voneinander in Erfahrung gebracht haben, dass AMD aktuell zwar noch einen (Paper-)Launch im September plant, mit einer Verfügbarkeit allerdings erst im Oktober zu rechnen sei. Ähnliche Gerüchte wollte zuvor auch schon Donanimhaber Ende Juli und die DIGITIMES Anfang August aus dem Kreise der Mainboardhersteller vernommen haben. Damit verfehlt AMD das ursprünglich genannte Launchfenster für den "Zambezi" nun bereits um zwei Quartale. Andererseits hat AMD mehrfach betont, die Serverversionen lägen im Zeitplan und würden auf jeden Fall noch im September gelauncht. Das legt die Vermutung nahe, dass die Desktop-Versionen offenbar verschoben werden mussten, um den vertraglichen Verpflichtungen im Servermarkt nachkommen zu können. Schließlich will beispielsweise Cray einige Supercomputer mit den AMD Opteron 6200 (Codename "Interlagos") ausstatten. Gerade der Großkunde Cray dürfte sich noch gut an die Komplikationen (TLB-Bug) beim "Barcelona"-Launch und die daraus resultierenden eigenen Schwierigkeiten erinnern. Auch die immer mal wieder auftauchenden Benchmarks aus mehr oder weniger vertrauenswürdigen Quellen zeigen nicht den von vielen erhofften großen Leistungssprung gegenüber den aktuellen Angeboten. Ob die eher enttäuschenden Messwerte auf Software- oder Hardwareprobleme zurück zu führen sind, bleibt bisher unklar. Hier werden die ersten unabhängigen Benchmarks (hoffentlich bald) Aufschluss geben können.
Der Nutzer Ronny145 aus dem Forum vom 3DCenter hat jetzt jedenfalls in der Kompatibilitätsliste von GIGABYTE für das Mainboard GA-990FXA-UD5 (rev. 1.0) die vermeintlich ersten Modelle der AMD FX-Serie Prozessoren entdeckt. Die genannten Modelle bestätigen im wesentlichen die Daten von Donanimhaber. Zusätzlich nennt GIGABYTE die Basistaktraten, verschweigt aber die maximalen Turbo-Frequenzen. Demnach soll das Topmodell mit vier "Bulldozer"-Modulen AMD FX-8150 bei einer TDP von 125 Watt einen Basistakt von 3.6 GHz besitzen. Alle Modelle sollen laut GIGABYTE zum Start auf dem B2-Stepping basieren und über einen auf 5200 MT/s beschleunigten HT-Link mit dem Chipsatz kommunizieren. Außerdem plant AMD offenbar nicht, die unterschiedlichen Cache-Stufen für die kleineren Modelle zu beschneiden. Allen AMD FX-Serie Prozessoren werden zum Start die vollen 8 MiB L3-Cache und 2 MiB L2-Cache pro Modul zur Verfügung stehen.
Offizielle Daten AMDs stehen noch aus, sodass die Angaben wie immer mit Vorsicht zu genießen sind.
Die Auswertung des zweiten Quartals liegt vor und überrascht so einige Analysten. Nachdem das Vorjahresquartal noch ein Defizit aufwies, kann AMD nun ein Plus von 61 Millionen US-Dollar vorweisen. Dafür muss man aber auch sehen, dass der schwächelnde Markt mit niedrigeren Absatzzahlen und harten Preiskämpfen für einen leichten Rückgang des Umsatzes von 5% auf 1,6 Milliarden US-Dollar verantwortlich ist. Für das nun laufende dritte Quartal erwartet der kleine x86-Riese aber deutlich bessere Zahlen. Vor allem die nun angelaufene Fusion-Plattform Llano (A-Serie) dürfte dabei eine größere Rolle spielen. Große Bestellungen von APUs der Z-Serie für Tablets dürften auch ihren Teil beitragen haben.
Während das CPU-/APU-Segment mit einem operativen Gewinn von 142 Millionen US-Dollar stärker gegenüber den vorangegangen Quartalen auftritt (Q1/2011 100 Mio. US-Dollar, Q2/2010 128 Mio. US-Dollar), muss AMD im Grafik-Segment einen Verlust ausweisen. 7 Mio. US-Dollar Verlust werden mit einem um 11 Prozent gefallenen Erlös verbunden (Q1/2011 +19 Mio. US-Dollar, Q2/2010 +33 Mio. US-Dollar). Der Deal mit Nintendo über die Lieferung der Grafikeinheit der Wii U wird aber als markanter Punkt des zweiten Quartals ausgewiesen. Erfreulich ist außerdem, dass AMD in der TOP-500-Liste der Supercomputer mit den 8- und 12-Kern-Prozessoren wieder besser vertreten ist.
Im dritten Quartal erwartet AMD um 10 Prozent steigende Erlöse mit möglichen Schwankungen von +/- 2%.
Die AMD-Aktie reagierte auf den positiven Bericht über schwarze Zahlen mit einem Anstieg von 4,54 Euro auf 4,78 Euro (22. Juli 10:30).
Nachdem wir vor kurzem den Start von Llano für den mobilen Markt beobachten konnten, wollen wir zum Launch der neuen Desktopplattform für den Mainstream selber Hand anlegen. Natürlich ist uns bewusst, dass die APU für die Spieler unter Euch nicht sonderlich interessant ist, aber für alle diejenigen, die einen günstigen und sparsamen Rechner für Office, Internet oder als HTPC suchen, könnte dieser Chip eine hervorragende Möglichkeit darstellen. Abgesehen von der Spieleleistung ist natürlich auch das Thema DirectCompute und OpenCL interessant, verspricht AMD doch, in diesem kleinen Chip die Leistung eines Supercomputer zu vereinen. Tatsächlich ist die theoretische Rechenleistung der bis zu 400 Compute Shader gigantisch im Vergleich zu den maximal vier x86-Kernen. Für genauere architektonische Details sei hier auf den Artikel zu AMDs Sabine-Plattform verwiesen.
Der Artikel wird versuchen, Euch die Leistungsfähigkeit des Desktoppendants näher zu bringen. Wir wünschen viel Spaß beim Lesen.
Update: In der Zwischenzeit haben wir einige Nachtests angestellt um noch einige Fragen, wie USB-3.0-Performance, Flash-Beschleunigung und den kleinen Bruder A6-3650 zu testen. Den Artikel findet ihr unter folgendem Link: http://www.planet3dnow.de/vbulletin/showthread.php?t=397166
Ja klar, der diesjährige Aprilscherz war sofort als solcher zu erkennen, hat aber hoffentlich Spaß gemacht. Es war natürlich die Geschichte mit dem Ökostrom aus dem e-Bike; ausschließlich übrigens.
Wie Planet 3DNow! Stammleser wissen, haben die hiesigen Aprilscherze eine seltsame Tendenz dazu, einige Zeit später auf irgendeine Art und Weise Realität zu werden. Beispiele? Nun, da wäre der 2001er Aprilscherz, der Sockel-A-zu-Sockel-7 Adapter, später als AM2-Card für ASRock 939Dual-SATA2 Realität geworden. Oder der 2003er, die Fusion zwischen AMD und NVIDIA; hier hatten wir uns nur in der Firma geirrt, denn es war dann ja bekanntlich ATI, nicht NVIDIA. Dann der 2004er Ultron64 Dual-Core, später als Athlon 64 X2 millionenfach verkauft, sowie der 2007er Barcelona mit integrierter GPU, inzwischen als Fusion-APU auf dem Markt. Auch beim 2008er Many-Core auf Basis eines 90er Jahre Simple-Chips sah es gut aus, ehe Intel das Projekt Larrabee kurzerhand eingestampft hat. Ja und selbst der fiktive Core-Fusion Chipsatz als leistungsstarker Grafik-Chipsatz für Intels Atom Plattform wurde nur wenig später als ION Realität; allerdings lagen wir auch hier wieder mit der Firma daneben. Dieses Mal war es NVIDIA nicht ATI. Wie allerdings der 2011er Aprilscherz in dieser Form Realität werden soll, ist momentan noch nicht abzusehen. Aber vielleicht meldet sich ja morgen ein e-Bike Hersteller bei uns, wohin er denn nun die Ware liefern soll...
Der Vollständigkeit halber auf einen Blick die Planet 3DNow! Aprilscherze der letzten 10 Jahre:
AMD hat heute mit der AMD Opteron 4000 Plattform San Marino für 1P und 2P Systeme, die auf Prozessoren mit 4 und 6 Kernen der AMD Opteron 4100 Serie Lisbon und ein Chipset der AMD SR5600 Serie setzt, den zweiten Teil der neu ausgerichteten Serverplattform vorgestellt. Bereits am 29. März hatte man die neuen Lösungen basierend auf der AMD Opteron 6000 Plattform Maranello für 2P und 4P Systeme, die auf Prozessoren mit 8 und 12 Kernen der AMD Opteron 6100 Serie Magny-Cours und ein Chipset der AMD SR5600 Serie setzt, vorgestellt.
Die neue kostenoptimierte AMD Opteron 4000 Plattform zielt vor allem auf SMBs (small and medium-sized businesses) sowie Cloud Computing und andere Anwendungen, bei denen eine besonders hohe Packungsdichte erforderlich ist. Außerdem konnte man die Leistungsaufnahme der Plattform deutlich senken, was im anvisierten Markt eine größere Bedeutung hat als die absolute Performance. Dafür wurden neue Feature wie C1e Power State (nur die Six-Cores), AMD Cool Speed technology, APML (Advanced Platform Management Link) und DDR3 implementiert. Mit den Sechskern-Prozessoren AMD Opteron 4162 EE und 4164 EE reklamiert AMD für sich, die Server-Prozessoren mit der geringsten Leistungsaufnahme pro Kern im Angebot zu haben. Dabei bezieht man sich auf die TDP der EE Modelle von nur 35 Watt.
Der unter dem Codenamen "Lisbon" (Revision HY-D1) entwickelte Prozessor ist bereits im Tandem als MCM-Design (multi chip module) des Magny-Cours Prozessors zu finden. An der Cache-Architektur wurde nichts gegenüber dem Istanbul (Revision HY-D0) verändert (Laut "Revision Guide for AMD Family 10h Processors" werden auch "Istanbul"-Dies als AMD Opteron 4100 verkauft ). Jedem Kern stehen auch weiterhin ein 128 KiB L1 Cache (64 KiB für Daten und 64 KiB für Befehle) sowie ein 512 KiB großer L2-Cache zur Seite. Außerdem verfügt jeder Prozessor über einen 6 MiB großen L3-Cache, den sich alle Kerne teilen. Der 346 mm² große Die bringt 904 Millionen Transistoren auf die Waage. Als Fertigungstechnologie kommt weiterhin der bekannte 45nm SOI Prozess beim Fertigungspartner GlobalFoundries zum Einsatz. Die Opteron 4100 Prozessoren finden im Sockel C32 mit 1207 Pins (LGA) Platz, der praktische eine für DDR3 SDRAM sowie höhere Taktraten der HT-Links optimierte Version des altbekannten Sockel F ist. Für Verbindung zur Außenwelt sorgen die zwei 16-bit HT3-Links und die zwei 72-bit Speicherkanäle. Die HT3-Links arbeiten mit einer Übertragungsgeschwindigkeit von bis zu 6,4 GT/s (3,2 GHz). Über den integrierten DDR3 Speicher-Controller (IMC), der natürlich auch den für DDR3 zu bevorzugenden Unganged-Modus beherrscht, können bis zu drei DIMMs pro Kanal mit einer effektiven Taktfrequenz von bis zu 1333 MHz angebunden werden, was eine maximale Bandbreite von 21,3 GB/s pro CPU ergibt. Zudem unterstützt der IMC ebenfalls LV-DDR3-1066 DIMMs, die mit 1,35 statt 1,5 V Betriebsspannung arbeiten. Allerdings gilt das nur für die AMD Opteron 4100 mit sechs Kernen!
Zum Start erstreckt sich die Produktpalette über neun Modelle, die in die drei ACP-Klassen 32, 50 und 75 Watt (entspricht 35, 65 und 95 Watt TDP) eingruppiert sind. Die Taktraten reichen von 1,7 GHz bis rauf auf 2,8 GHz, wobei bis auf die beiden EE Modelle die Northbridge mit einem Takt von 2,2 GHz arbeitet. Interessanterweise ist nicht das schnellste Modell, der AMD Opteron 4184, sondern das am höchsten getaktete EE Modell, für das 698 US-Dollar veranschlagt werden, am teuersten. Mit dem Quad-Core AMD Opteron 4122 durchbricht zum ersten Mal ein Serverprozessor die 100-Dollar-Marke nach unten. Allerdings basiert dieses und das zweite Quad-Core-Modell AMD Opteron 4130 noch auf dem Istanbul Die (Revision HY-D0) und verfügt, wie oben bereits beschrieben, nicht über den vollen Funktionsumfang der Six-Cores. (siehe hier)
Bisher konnte man die großen OEMs wohl noch nicht so recht von der neuen Serverstrategie überzeugen. Lediglich Dell entwickelt eine eigene Cloud Computing Lösung und Acer will unter der Marke Gateway SMB-Lösungen auf den Markt bringen. AMD selbst sieht den größten Markt in kundenspezifischen Lösungen die auf den Komponenten der Channel-Partner basieren.
AMD will die Entwicklung beider Plattformen bereits voll auf die kommenden Prozessoren ausgerichtet haben, die auf der neuen Bulldozer-Architektur basieren. Dadurch soll ein problemloses Drop-In Upgrade auf den Valencia Prozessor mit 6 und 8 Kernen (Opteron 4200, Sockel C32, 3 und 4 Bulldozer-Module) bzw. Interlagos Prozessor mit 12 und 16 Kernen (Opteron 6200, Sockel G34, MCM mit zweimal 3 und 4 Bulldozer-Module) möglich sein. Bisher spricht AMD lediglich von 2011, realistisch kann wohl mit einem Erscheinen dieser Prozessoren irgendwann im zweiten oder dritten Quartal gerechnet werden.
Mit der AMD Opteron 6100 Serie für den Sockel G34 bringt AMD heute den ersten x86 Prozessor mit 12 Kernen auf den Markt. Die AMD Opteron 6100 Serie bildet zusammen mit einem Chipset aus der AMD SR5600 Serie die "Maranello" Plattform. Bereits nächstes Jahr wird die "Maranello" Plattform ein Update erfahren. Denn dann sollen die "Interlagos" mit 12 und 16 Kernen auf Basis der neuen "Bulldozer-Architektur" bereitstehen.
Mit der Einführung der "Maranello" Plattform ändert AMD seine Strategie im Servermarkt. Durch den Wechsel vom alten, fast vier Jahre alten, Sockel F auf zwei neue will man die einzelnen Marktsegmente besser adressieren und so die Kosten optimieren. Als wichtigste Kenngröße wird Preis pro Leistung und Watt definiert. Die "Maranello" Plattform deckt den 2P und den 4P Markt ab. Die AMD Opteron 6100 Serie soll die beste Performace pro Watt bieten und sich durch ihre gute Skalierbarkeit besonders eignen, wenn viele Kerne und maximaler Speicherausbau gefragt sind. Die zweite neue Plattform für den 1P und 2P Markt baut auf den neuen Sockel C32 auf. Zur "San Marino" Plattform gehört die AMD Opteron 4100 Serie, Codename "Lisbon", und ebenfalls ein Chipset der AMD SR5600 Serie. Die "San Marino" Plattform ist auf eine besonders hohe Energieeffizienz ausgelegt. Durch die Überschneidung im 2P Mainstream Markt will man gerade hier wachsen, da mit den neuen Plattformen vom High-End bis runter zum Low-End der 2P Mark zu extrem konkurrenzfähigen Preisen bedient werden kann, ohne künstlich das Feature Set der Prozessoren zu beschneiden. Für beide Plattformen werden die gleichen Chipsets, das gleiche BIOS und die gleichen Treiber verwendet. Zusammen mit dem gleichen Feature Set der Prozessoren aus der AMD Opteron 6100 und der AMD Opteron 4100 Serie soll dies zu möglichst geringem Aufwand bei Qualifizierung und Management für die Kunden führen. Weitere Kosteneinsparungen ergeben sich daraus, dass der Sockel C32 praktisch nur ein für DDR3 optimierter Sockel F ist.
Der unter dem Codenamen "Magny-Cours" entwickelte Prozessor ist ein MCM Design (multi chip module), das aus zwei "Lisbon" Dies besteht, die direkt miteinander via HyperTransport 3.0 verbunden sind. Für die Kommunikation zwischen den beiden Dies werden ein 16-bit und ein 8-bit HT3 Link verwendet. An der Cache-Architektur wurde nichts gegenüber dem Istanbul verändert. Jedem Kern stehen auch weiterhin ein 128 KiB L1-Cache (64 KiB für Daten und 64 KiB für Befehle) sowie ein 512 KiB großer L2-Cache zur Seite. Außerdem besitzt jeder der beiden Dies einen 6 MiB L3-Cache, von dem 1 MiB für HT Assist (Probe Filter) genutzt werden kann. Jeder der beiden 346 mm² großen Dies bringt 904 Millionen Transistoren auf die Waage. Als Fertigungstechnologie kommt weiterhin der bekannte 45nm SOI Prozess beim Fertigungspartner GlobalFoundries zum Einsatz. Die Opteron 6100 Prozessoren finden im Sockel G34 mit 1944 Pins (LGA) Platz. Diese große Anzahl Kontakte wird auch benötigt, denn der Sockel G34 führt vier 16-bit HT3-Links und vier 72-bit Speicherkanäle nach außen, was von AMD auch gern als "Direct Connect Architecture 2.0" bezeichnet wird. Die HT3-Links arbeiten mit einer Übertragungsgeschwindigkeit von bis zu 6,4 GT/s (3,2 GHz). Die beiden integrierten DDR3 Speicher-Controller (IMC) unterstützen bis zu DDR3-1333, was zu einer maximalen Bandbreite von 42,7 GB/s pro CPU führt. Bis zu 2 DIMMs pro Kanal können mit der vollen Geschwindigkeit angesprochen werden, wird ein 3. (Vollbestückung) hinzu gesteckt, reduziert sich der maximal mögliche Takt auf 1066 MT/s (667 MHz). Die IMC unterstützen ebenfalls LV-DDR3-1066, der mit 1,35 statt 1,5 V Betriebsspannung arbeitet.
Die vier HT3-Links der "Direct Connect Architecture 2.0" ermöglichen es erstmals, in 4P Systemen alle CPUs direkt miteinander zu verbinden. Somit sind die Daten höchstens einen Hop weit entfernt. Zusätzlich reduziert HT Assist die Latenzzeiten und die höheren Taktfrequenzen der HT-Links führen zu einer 33% schnelleren Kommunikation zwischen den CPUs. Jeder der vier Speicherkanäle kann 3 DIMMs ansteuern. Damit stehen jeder CPU mit maximal 12 DIMMs 50% mehr Speichermodule als bei der alten Plattform zur Verfügung. Gegenüber der Konkurenz kann man so im 2P Markt 33% mehr DIMMs und die höhere Speicherbandbreite bieten. Außerdem verspricht man sich einen Kostenvorteil gegenüber der Konkurrenz, da man bei besonders großem Speicherausbau bei den günstigeren 4 GiB DDR3 DIMMs bleiben kann, während die Konkurrenz bereits die wesentlich teureren 8 GiB DDR3 DIMMs nutzen muss.
Gegenüber den "Istanbul" verspricht man im SPECint_rate2006 eine Steigerung um 88% und im SPECfp_rate2006 sogar eine Steigerung um 119%. Sowohl im 2P als auch im 4P Mark will man die gleiche Leistung bei geringeren Gesamtkosten und geringerem Stromverbrauch der Plattform bieten. Hierzu soll vor allem der neue C1e Power State, die "AMD Cool Speed technology", der "Advanced Platform Management Link" (APML) und die Unterstützung von Low Voltage DDR-3 DIMMs beitragen.
Gemäß dem eigenen Motto "more cores and more memory for less money" bietet AMD zum Start 10 Modelle der neuen AMD Opteron 6100 Serie in drei verschiedenen ACP-Klassen an. Darunter befinden sich fünf Modelle mit 12 Kernen, die mit Taktraten von 1,7 bis 2,3 GHz betrieben werden sowie fünf Modelle mit 8 Kernen, deren Taktraten von 1,8 bis 2,4 GHz reichen. Das Topmodell ist der AMD Opteron 6176 SE mit 12 Kernen, die mit einer Taktfrequenz von 2,3 GHz arbeiten und dabei eine Verlustleistung von 105 Watt (ACP) erzeugen. Bei der Abnahme von 1000 Stück kostet ein AMD Opteron 6176 SE 1386 US-Dollar. Hinzu kommen 3 Zwölfkerner mit einer ACP von 80 Watt (standard power) und ein HE Modell (low-power) mit einer ACP von 65 Watt. Der Einstieg in die Zwölfkernklasse beginnt bei 744 US-Dollar für den AMD Opteron 6168 mit 1,9 GHz oder den AMD Opteron 6164 HE mit 1,7 GHz. Die Achtkerner werden nur mit 80 Watt ACP (3 Modelle) oder 65 Watt ACP (2 Modelle) angeboten, wobei die Preise von 455 bis 744 US-Dollar reichen. Bei allen "Magny-Cours" taktet die North Bridge (Uncore-Bereich), mit 1,8 GHz - also 400 MHz langsamer als noch bei den "Istanbul". Mit diesem Takt laufen der IMC, der L3-Cache und die Crossbar. Laut John Fruehe, Director of Product Marketing for Server/Workstation products at AMD, entsprechen 65, 80 und 105 Watt ACP den TDP Werten 85, 115 und 140 Watt. Diese Angaben werden durch die mittlerweile aktualisierte technische Dokumentation "AMD Family 10h Server and Workstation Processor Power and Thermal Data Sheet" bestätigt.
Zum Start werden 25 Plattformen von den OEM Partnern angeboten. HP stellt beispielsweise die neue HP ProLiant G7 Server vor.
Als AMD die erfolgreiche Übernahme von ATI im Oktober 2006 bekanntgab, rechtfertigte man die immensen Kosten unter anderem damit, dass man zukünftig vollständige Plattformen anbieten wolle. Der zweite wichtige Punkt der aus Sicht von AMD für die Übernahme des Grafikkartenspezialisten ATI sprach, war die Vision zukünftig CPUs und GPUs zusammenwachsen zu lassen. Die als Accelerated Processing Unit (APU) bezeichneten Prozessoren sollten von den Stärken beider Technologie profitieren. Auf der einen Seite also die hohe Performance hochgetakteter CPUs in singlethreaded und wenig parallelisierbaren Problemen und auf der anderen Seite die explodierende Leistung von GPUs bei massiv parallelen Problemstellungen. Dieser Ansatz zum Heterogenen Computing firmierte von da an unter dem Oberbegriff Fusion. Erste Produkte wurde bereits für Ende 2008 bzw. Anfang 2009 angekündigt. Wie wir alle wissen, ist es aber nicht so gekommen. Als Reaktion darauf machten Gerüchte die Runde, wonach Intel und Nvidia an einem ähnlichen Konkurrenzprodukt arbeiten würden. Auch sonst wurde viel über die Neuen Produkte spekuliert, denn harte Fakten gab es nur sehr wenige. Auf dem Analyst Day 2007 bekam dann das erste Fusion-Produkt einen Namen. Die auf den Namen Swift getaufte APU sollte als Teil der Shrike Plattform aus einem Stars Core, auch Greyhound oder K10 genannt, und einer GPU der HD 3000 Serie aufgebaut sein. Der Marktstart war für das zweite Halbjahr 2009 geplant. Auch daraus wurde nichts. AMD hielt sich zu den genaueren Details weiter bedeckt, so dass weiterhin wilde Gerüchte die Runde machten.
Als AMD eine Website unter der URL fusion.amd.com anlegte, spekulierten viele über eine Umbenennung der ersten APU in den mittlerweile viel bekannteren Namen Fusion. Am 18. September stellt sich dann schließlich heraus, dass AMD die Bedeutung von Fusion weiter aufweitete und zum Motto für das gesamte Unternehmen machte. Damit löste Future is Fusion den langjährigen Claim Smarter Choice ab. Da man immer noch kein APU-Produkt vorweisen konnte, stellte man zunächst ein paar mehr oder weniger nützliche Tools vor, die im Namen das neue Motto Fusion trugen. Konkrete technische Daten oder Markteinführungsdaten blieb man der interessierten Öffentlichkeit hingegen weiter schuldig. Stattdessen wiederholte man erneut die Grundzüge der Vision hinter Fusion.
In der Zwischenzeit kam ein neuer Hype-Begriff in der IT-Industrie auf. Alles sprach auf einmal vom Cloud Computing. Kurz gesagt, handelt es sich dabei um einen Ansatz, bei dem die Anwendungen auf zentralen Servern laufen und das Interface auf das jeweilige Endgerät gestreamt wird. Dadurch sinken die Anforderungen an die Endgeräte, so dass sich beispielsweise auf Handys HD-Inhalte darstellen lassen. Auch AMD stellte eigen Lösung in Zusammenarbeit mit seinen Partnern vor. Am 8. Januar 2009 kündigte man dann auf der CES die Entwicklung eines Supercomputers für HD Cloud Computing an. Mit diesem AMD Fusion Render Cloud (FRC) getauften Supercomputer sollte die Bereitstellung von HD-Inhalten revolutioniert werden. Der Supercomputer sollte eine Millionen Threads parallel bearbeiten können und eine geplante Rechenleistung von einem Petaflop erreichen. Dies sollte durch die Fusion von Opteron CPUs mit mehr als 1000 GPUs erreicht werden. Damit liegt man laut TOP500 auf dem Niveau der aktuell schnellsten Supercomputer der Welt.
Der 45 nm Prozessor Swift wurde in der Zwischenzeit von den Roadmaps gestrichen. Stattdessen erschien eine APU namens Llano, die im 32 nm SOI Prozess gefertigt werden soll und vier K10 Kerne, sowie eine GPU der Evergreen-Familie auf einem Die vereint. Llano wird als erste Fusion-CPU mit der Lynx (Desktop) bzw. Sabine (Notebook) Plattform im Jahr 2011 auf den Markt kommen. Erste wirkliche Details gab man auf der ISSCC bekannt allerdings nur zum CPU-Teil. Gleichzeitig wurde der Fusion-Blog ins Leben gerufen, in dem bis zum Erscheinen weitere Einzelheiten zum Llano und anderen APUs zukünftig diskutiert werden sollen. Nach all den Verzögerungen wird AMD allerdings nicht der erste Anbieter einer CPU mit ins Package integrierter GPU sein. Intel bietet mit den Westmere-Prozessoren eine Solche CPU bereits seit Januar 2010 an.
Gestern hat AMD mit seinen Partnern OTOY und Super Micro die Verfügbarkeit der Fusion Render Cloud für das zweite Quartal 2010 angekündigt. Dabei stellt AMD natürlich die CPUs und GPUs. Super Micro hat die Serverplattform entwickelt und wird sie innerhalb der eigenen Produktlinie anbieten. OTOY zeichnen sich für die Software verantwortlich, mit deren Hilfe Cloud-Software entwickelt werden kann. Außerdem steuert man die Streaming-Plattform bei.
Spezifikationen der FRC Hardware:
125 1U rackmount servers - available pre-racked in Super Rack configuration
500 ATI Radeon HD 5970 graphics cards - each with 2.7 TeraFLOPS of processing power
250 AMD Opteron 6100 series processors
<100 Kw, 40 sqft of space per 1 PetaFLOPS of computing power
FRC technische Spezifikationen:
Up to 3,000 concurrent HD streams (720p/1080p or higher @ 60hz) for streaming AAA video games, high end CAD programs and full virtual desktops for all major Operating Systems
Up to 12,000 concurrent SD streams @ 120 hz
Ultra fast HD encoding < 1ms per megapixel
Token based metering system built into driver stack for easy cost analysis and resource provisioning
Die Formel 1 2010 steht unmittelbar vor dem Start. Am kommenden Wochenende beginnt die Saison mit dem Großen Preis von Bahrain in Manama. Doch während alle Welt auf das Comeback von Michael Schumacher, das Duell zweier englischer Weltmeister im McLaren-Mercedes gegen zwei Deutsche im Werks-Mercedes, Fernando Alonso und Rückkehrer Felipe Massa im Ferrari, sowie Sebastian Vettel im Redbull blickt, hat ein kleines, neues Team namens Virgin eine Revolution im Grand-Prix Sport eingeläutet.
Der Chef-Designer des Virgin Racing Teams, das 2010 als Neueinsteiger in der Formel 1 mit den Fahrern Timo Glock (GER) und Lucas di Grassi (BRA) an den Start geht, setzt auf ein völlig anderes Design-Konzept, als die etablierten Gegner. Formel 1 Rennwagen sind stark und leicht. Aufgrund dieses guten Leistungsgewichts sind sie in der Lage sehr schnell zu beschleunigen. Gute Rundenzeiten jedoch verdanken sie ihrer ausgefeilten Aerodynamik, die sie regelrecht auf der Strecke festsaugt. Während normale Straßen- oder Tourenwagen bei 1G Querbeschleunigung an ihre Grenzen stoßen, können Formel 1 Rennwagen mit bis zu 4G um die Kurven räubern. Der Anpressdruck über die Flügel und den Unterboden ist so groß, dass sie ab ca. 200 km/h an der Decke eines Tunnels fahren könnten ohne herunter zu fallen.
Um die aerodynamische Effizienz - also das Verhältnis von möglichst geringem Luftwiderstand zu möglichst großem Anpressdruck im Rahmen der vom Reglement vorgegebenen Eckdaten - zu optimieren, setzen die Teams seit jeher auf Windkanäle, je nach Team und Geldbeutel auch auf mehrere, betrieben von hunderten von Aerodynamik-Ingenieuren rund um die Uhr. Die Simulation per Computer hatte bereits in den letzten Jahren Einzug erhalten, allerdings vorwiegend als Grob-Filter, um gewissen Ansätze bereits im Vorfeld als tauglich oder untauglich aussortieren zu können. Für höhere Aufgaben war dieses CFD (Computational Fluid Dynamics) bisher nicht geeignet, auch deswegen, da die Aerodynamik ein Forschungsfeld ist, das sich aufgrund ihrer Komplexität mit am schwierigsten in klare 0/1 Regeln übertragen lässt.
Ab dem 14. März 2010 jedoch wird Virgin Racing in der Formel 1 mitmischen. Das Team verfügt weder um besonders populäre Fahrer, noch über irgendwelche anderen polarisierenden Faktoren; mit Ausnahme vielleicht des Team-Besitzers, Sir Richard Charles Nicholas Branson, seines Zeichens Milliardär und Idealist, der Dinge gerne etwas anders angeht als andere. Da kam ihm der Chef-Ingenieur Nick Wirth gerade recht, der eben diesen CFD-Ansatz schon in anderen Rennserien erfolgreich angewendet hatte und damit ein enormes Einspar-Potenzial bewies. Er verzichtet völlig auf einen klassischen, Energie- und Personal-intensiven Windkanal und setzt zu 100 Prozent auf CFD-Simulation.
Auf welche Computer-Technologie er setzt, mochte er in einem Interview nicht verraten. Außer dass es sich um einen massiv parallellen Rechner handelt, was ohnehin von vorne herein klar war, dass die Prozessoren des Clusters wassergekühlt seien und dass der gesamte "virtuelle Windkanal" begehbar sei.
Die CFD-Idee als Design-Grundlage für einen Formel 1 Wagen war auf Basis des ursprünglichen Ansatzes des Automobil Weltverbandes FIA entstanden, der vorsah, dass Formel 1 Teams künftig nicht mehr als 45 Mio. US-Dollar an Budget zur Verfügung haben dürften. Da schien CFD als kostengünstige Lösung gerade recht. Da die FIA dann aber doch der Mut verließ und das Budget-Limit wieder verworfen wurde, sieht sich Virgin Racing in diesem Jahr einer Konkurrenz gegenüber, die mit einem oder mehreren Windkanälen und teils mehr als 100 Ingenieuren nur in diesem Bereich in praktischen Experimenten versuchen werden, die Physik und das engmaschige Reglement zu überlisten. Der Saisonverlauf wird zeigen, wer am Ende den effektiveren Weg eingeschlagen hat.
Der derzeit schnellste Supercomputer der Welt rechnet mit AMDs Opteron, so sagt es die neue Liste vom 13. November 2009, in der die 500 schnellsten Großrechner der Welt gelistet sind. Mit 1,759 PFlops im Linpack-Benchmark übertrumpft "Jaguar", der von Cray für das National Center for Computational Science in Oak Ridge (ORNL) errichtet wurde, den bisherigen Spitzenreiter "Roadrunner" (rund 1,04 PFlops) sehr deutlich.
Möglich wurde der massive Performancezuwachs durch die Aufrüstung auf AMD "Istanbul"-Opterons mit insgesamt 224.162 Kernen, welche jeweils mit maximal 2,6 GHz getaktet sind.
Neben "Jaguar" und "Roadrunner" (Mischbestückung aus IBM Cell und AMD Dual-Core Opterons) auf Platz Eins und Zwei kann AMD auch den dritten Rang belegen. "Kraken", an der University of Tennessee, der mit immerhin 16.488 Sechskern-Opterons ausgestattet ist, kann mit immerhin 831,7 TFlops (0,832 PFlops) aufwarten. Platz Vier der Top-Liste kommt übrigens aus Deutschland: "JUGENE" des Forschungszentrums Jülich. "JUGENE" ist ein Supercomputer aus IBMs BlueGene Reihe und kann aus 294.912 Kernen von PowerPC 450 Prozessoren mit jeweils 850MHz eine Leistung von 0,823PFlops mobilisieren. Und mit Tianhe-1 auf Platz Fünf ist erstmal ein chinesischer Supercomputer an der Spitze vertreten. Neben Intel Xeon Prozessoren steuern hier auch ATI Radeon 4870 Grafikkarten ihre Leistung bei.
Insgesamt ist AMD mit 42 Supercomputern in der Top500 vertreten. IBM konnte sich 52 Plätze Sichern, während der große Rest von Intel-Systemen beherrscht wird. Ob und wie sich das Bild mit dem erscheinen der 12-Kern CPUs "Magny Cours" ändern wird, wird die Zeit zeigen.
In den letzten Tagen machten Gerüchte im Internet die Runde, dass NVIDIA mit ehemaligen Transmeta-Entwicklern an x86-CPUs arbeiten würde. Dem hat nun NVIDIA-CEO Jen-Hsun Huang eine klare Absage erteilt.
Statt sich in den Markt für CPUs zu drängen, wo neben Intel und AMD wohl eh wenig Platz sein dürfte, will NVIDIA die Rolle der GPU weiter stärken und profilieren. Laut Jen-Hsun Huang sollen die Grafikkarten demnächst in nahezu allen Server-Bereichen vertreten sein. Neben dem klassischen Parallelrechner, für den GPUs von jeher prädestiniert waren, fasst man nun auch die Bereiche der Hochleistungsrechner (Supercomputer) und des Cloud Computing ins Auge.
Nachdem AMD bereits einmal eine "x86 Everywhere" Strategie propagiert hatte, will NVIDIA vielmehr mit den eigenen Grafikprodukten wie dem Tegra auch in den Low-Power-Bereich vordringen.
Der am National Institute for Computational Sciences der Universität von Tennessee installierte Supercomputer "Kraken" besitzt nun Dank einer Umrüstung auf Sechskern-Opterons ("Istanbul") eine Peak Perfomance von 1,03 Petaflops.
Nach der am 5. Oktober abgeschlossenen Umrüstung auf 16.000 "Istanbul"-Prozessoren mit jeweils sechs Kernen und einem Takt von 2,6 GHz würde der "Kraken" im Top500-Ranking der Supercomputer vom sechsten auf den dritten Platz vorrücken, allerdings werden bis zum Erscheinen der neuen Liste im November wohl noch zahlreiche andere Systeme ebenfalls einem Upgrade unterzogen. Die Leistung von einem Petaflop dürfte jedenfalls in naher Zukunft nicht mehr als etwas Außergewöhnliches wahrgenommen werden.
Wie angekündigt hat NVIDIA gestern (bzw. heute Nacht MESZ) auf der GPU Technology Conference in San Jose, Kalifornien, seine neue Fermi-Architektur alias GT300 gezeigt, eine GPU die laut NVIDIA ein Supercomputer in eine GPU gepackt darstellen soll.
Die GPU namens GT300 wird in 40 nm bei TSMC gefertigt. Der Chip besitzt nicht weniger als 3 Milliarden Transistoren. 16 Shader-Cluster kümmern sich um die Berechnungen, wobei jeder Shader-Cluster aus je 32 Kernen besteht, die NVIDIA nun CUDA-Cores nennt. Der Chip ist auf 6-Channel GDDR5-Speicher ausgelegt, was unter dem Strich eine 384-Bit Anbindung ergibt. Bis zu 6 GB VRAM sollen den Karten zur Verfügung stehen. Zusätzlich können die Kerne auf insgesamt 1 MB L1-Cache (in 16 KB Häppchen unterteilt) und 768 KB L2-Cache (unified) zurückgreifen. Die Double Precision Leistung soll sich verachtfacht haben. Zudem soll Fermi nativ unterstützen: C [CUDA], C++, DirectCompute, DirectX 11, Fortran, OpenCL, OpenGL 3.1 und OpenGL 3.2. ECC für die Caches und Context Switching zwischen GPU Applications sind ebenfalls an Bord. Damit erhält der Fermi viele Features, die bisher eher in CPU denn in GPUs zu finden waren mit dem Ziel, den prinzipbedingt enormen Durchsatz einer GPU mit der Flexibilität und dem universellen Funktionsumfang einer CPU zu kombinieren. NVIDIA geht damit den ungekehrten Weg Intels, die mit dem Larrabee bekanntlich klassische CPU-Kerne GPU-fähig bekommen wollen.
Das mächtige Die einer Fermi GPU
Die zahlreichen Kerne sind in Cluster zusammen gefasst um Lokalitäten von Speicherzugriffen besser nutzen zu können.
Bildquellen: LegitReviews / NVIDIA
Nur wann der GT300 nun letztendlich wirklich auf den Markt kommen wird, war noch nicht zu erfahren.



























Diesen Artikel bookmarken oder senden an ...