AMD Phenom II X4 Deneb ŌĆö 45 nm f├╝r den Desktop
Der Deneb im Detail ŌĆö Der K10.5
Der AMD Phe┬Łnom II ŌĆ£DenebŌĆØ
So war der K10 sicher kein Pro┬Łdukt, an dem AMD ange┬Łsichts bei┬Łna┬Łher Per┬Łfek┬Łti┬Łon kei┬Łne Angriff┬Łpunk┬Łte gefun┬Łden h├żt┬Łte, um die Hebel der Wei┬Łter┬Łent┬Łwick┬Łlung anzusetzen.
Den sub┬Łop┬Łti┬Łma┬Łlen 65 nm Her┬Łstel┬Łlungs┬Łpro┬Łzess wird der Deneb ŌĆö in der Pres┬Łse oft scherz┬Łhaft ŌĆ£K10.5ŌĆØ genannt ŌĆö durch die Umstel┬Łlung auf 45 nm Struk┬Łtu┬Łren ŌĆ£auto┬Łma┬ŁtischŌĆØ los. Dabei han┬Łdelt es sich nicht um einen simp┬Łlen Shrink. AMD stell┬Łte zus├żtz┬Łlich zu den klei┬Łne┬Łren Struk┬Łtu┬Łren auf das soge┬Łnann┬Łte Immersi┬Łons-Litho┬Łgra┬Łphie-Ver┬Łfah┬Łren um. Damit soll es m├Čg┬Łlich sein, klei┬Łne Struk┬Łtu┬Łren wesent┬Łlich pr├ż┬Łzi┬Łser zu belich┬Łten. Zudem konn┬Łte laut AMD auch die Anzahl an Arbeits┬Łschrit┬Łten bis zum fer┬Łti┬Łgen Die redu┬Łziert wer┬Łden, was Kos┬Łten spart und die Pro┬Łduk┬Łti┬Łons┬Łzeit ver┬Łk├╝rzt. Ein highŌĆæk Dielek┬Łtri┬Łkum auf Metall-Basis wie es bei Intel schon seit den Pen┬Łryn-Pro┬Łzes┬Łso┬Łren ver┬Łwen┬Łdet wird, soll erst in einer sp├ż┬Łte┬Łren Aus┬Łbau┬Łstu┬Łfe Ver┬Łwen┬Łdung finden.
Aber auch ohne Metall-Gates ver┬Łspricht AMD einen erheb┬Łlich nied┬Łri┬Łge┬Łren Strom┬Łver┬Łbrauch. So soll ein 2,7 GHz Deneb gegen┬Ł├╝ber einem 2,3 GHz Age┬Łna trotz h├Čhe┬Łrer Takt┬Łfre┬Łquenz eine 35 Pro┬Łzent nied┬Łri┬Łge┬Łre Leis┬Łtungs┬Łauf┬Łnah┬Łme im Leer┬Łlauf haben und selbst unter Voll┬Łlast soll er immer noch 10 Pro┬Łzent spar┬Łsa┬Łmer sein ŌĆö bei 400 MHz mehr Takt┬Łfre┬Łquenz, mehr Cache und ent┬Łspre┬Łchend h├Čhe┬Łrer Leis┬Łtung. Aus┬Łge┬Łdr├╝ckt in CPU-Leis┬Łtung pro Watt ver┬Łspricht AMD gar eine 50-pro┬Łzen┬Łti┬Łge Ver┬Łbes┬Łse┬Łrung. Das sind gro┬Ł├¤e Wor┬Łte, denen Taten fol┬Łgen m├╝ssen.
H├Čhe┬Łre Taktfrequenz
W├żh┬Łrend beim 65 nm Phe┬Łnom mit Age┬Łna-Kern bei 2,6 GHz das Ende der Fah┬Łnen┬Łstan┬Łge erreicht war (Vor┬Łstel┬Łlung mit 2,3 GHz), kommt der 45 nm Phe┬Łnom II Deneb vom Start weg mit 3,0 GHz auf den Markt. Daher kom┬Łmen rech┬Łne┬Łrisch 15 Pro┬Łzent Mehr┬Łleis┬Łtung gegen┬Ł├╝ber dem bis┬Łhe┬Łri┬Łgen Top┬Łmo┬Łdell schon allei┬Łne von der h├Čhe┬Łren Takt┬Łfre┬Łquenz, die nun im Bereich der schnells┬Łten Intel-Pro┬Łzes┬Łso┬Łren liegt, die aktu┬Łell mit bis zu 3,2 GHz zu haben sind.
Gr├Č┬Ł├¤e┬Łrer Last Level Cache
Durch die klei┬Łne┬Łren Struk┬Łtu┬Łren des 45 nm Pro┬Łzes┬Łses hat┬Łte AMD nun die M├Čg┬Łlich┬Łkeit, den umstrit┬Łte┬Łnen Level 3 Cache von 2 MB auf 6 MB zu ver┬Łgr├Č┬Ł├¤ern ohne dies mit ├╝ber┬Łdi┬Łmen┬Łsio┬Łna┬Łler Die-Gr├Č┬Ł├¤e bezah┬Łlen zu m├╝s┬Łsen. Damit ver┬Łschiebt sich das Gleich┬Łge┬Łwicht ŌĆ£Penal┬Łty durch die zus├żtz┬Łli┬Łche Cache┬Łstu┬ŁfeŌĆØ vs. ŌĆ£H├Čhe┬Łre Hitra┬Łte durch gr├Č┬Ł├¤e┬Łren CacheŌĆØ zu Guns┬Łten des letz┬Łte┬Łren. Zudem will AMD die Cache-Latenz des L3-Cache ver┬Łbes┬Łsert haben, die bis┬Łher ŌĆö gemes┬Łsen mit CPUŌĆæZ Laten┬Łcy ŌĆö allen┬Łfalls als mit┬Łtel┬Łm├ż┬Ł├¤ig zu bewer┬Łten war. Die Asso┬Łzia┬Łti┬Łvi┬Łt├żt des L3-Caches wur┬Łde von 32-fach auf 48-fach erh├Čht.
Intel┬Łli┬Łgen┬Łte┬Łrer Prefetch-Algorithmus
Wei┬Łte┬Łres Poten┬Łzi┬Łal ver┬Łspricht sich AMD durch einen ver┬Łbes┬Łser┬Łten Pre┬Łfetch-Algo┬Łrith┬Łmus, der Daten basie┬Łrend unter ande┬Łrem auf den Ergeb┬Łnis┬Łsen der Sprung┬Łvor┬Łher┬Łsa┬Łge auf Ver┬Łdacht in den Cache l├żdt. Ob AMD wirk┬Łlich einen intel┬Łli┬Łgen┬Łte┬Łren Algo┬Łrith┬Łmus ein┬Łsetzt oder ŌĆö mit dem 3 mal so gro┬Ł├¤en L3-Cache im R├╝cken ŌĆö nun ein┬Łfach exzes┬Łsi┬Łver Gebrauch von Pre┬Łfet┬Łching macht, sei mal dahin gestellt.
Core Pro┬Łbe Band┬Łwidth erh├Čht
Fer┬Łner ver┬Łspricht AMD durch ein Fea┬Łture namens ŌĆ£2x Core Pro┬Łbe Band┬ŁwidthŌĆØ eine schnel┬Łle┬Łre Her┬Łstel┬Łlung bzw. Wah┬Łrung der Cache-Koh├ż┬Łrenz, da das Inter┬Łvall, in dem Snoop-Signa┬Łle aus┬Łge┬Łsen┬Łdet wer┬Łden, hal┬Łbiert wor┬Łden sein soll. Vor┬Łwie┬Łgend kommt dies dem Ser┬Łver-Able┬Łger Shang┬Łhai in Mul┬Łti-Sockel-Sys┬Łte┬Łmen zu Gute, aber laut AMD sol┬Łlen auch die Sin┬Łgle-Sockel-Denebs davon pro┬Łfi┬Łtie┬Łren. Jeden drit┬Łten Takt soll der ŌĆ£K10.5ŌĆØ nun ein Pro┬Łbe-Signal aus┬Łsen┬Łden k├Čn┬Łnen gegen┬Ł├╝ber jedem sechs┬Łten beim urspr├╝ng┬Łli┬Łchen K10.
Rapid Vir┬Łtua┬Łliza┬Łti┬Łon Indexing
In Bezug auf Vir┬Łtua┬Łli┬Łsie┬Łrung, die im Ser┬Łver-Bereich immer mehr an Bedeu┬Łtung gewinnt, ver┬Łspricht AMD eben┬Łfalls eine h├Čhe┬Łre Leis┬Łtung dank Rapid Vir┬Łtua┬Łliza┬Łti┬Łon Index┬Łing und Tag┬Łged TLBs. Bei┬Łdes f├╝hrt dazu, dass der Pro┬Łzes┬Łsor schnel┬Łler zwi┬Łschen zwei VMs mit eige┬Łnen Spei┬Łcher┬Ładres┬Łsen umschal┬Łten kann. Im Desk┬Łtop-Markt sicher┬Łlich eine zu ver┬Łnach┬Łl├żs┬Łsi┬Łgen┬Łde Kunst, auf Ser┬Łvern mit vie┬Łlen vir┬Łtua┬Łli┬Łsier┬Łten Maschi┬Łnen jedoch ist das f├╝r den Zwil┬Łlings┬Łbru┬Łder Shang┬Łhai ein will┬Łkom┬Łme┬Łnes Feature.
Smart Fetch
Den Ener┬Łgie┬Łbe┬Łdarf noch zus├żtz┬Łlich zu sen┬Łken ist die Auf┬Łga┬Łbe einer Smart Fetch genann┬Łten Funk┬Łti┬Łon. Die┬Łse kopiert den Inhalt des L1- und L2-Caches eines schla┬Łfen┬Łden Kerns in den von allen Ker┬Łnen direkt adres┬Łsier┬Łba┬Łren L3-Cache, so dass dar┬Łauf zuge┬Łgrif┬Łfen wer┬Łden kann ohne den betref┬Łfen┬Łden Kern zu wecken und ihn in einen nied┬Łri┬Łge┬Łren PŌĆæState zu ver┬Łset┬Łzen. Im End┬Łef┬Łfekt spart dies Ener┬Łgie und redu┬Łziert die Abw├żrme.
Bugs besei┬Łtigt
Neben dem ber├╝ch┬Łtig┬Łten Erra┬Łtum 298 ali┬Łas TLB-Bug besa┬Ł├¤en die 65 nm Phe┬Łnoms noch eine Rei┬Łhe wei┬Łte┬Łrer ŌĆ£Unp├żss┬Łlich┬Łkei┬ŁtenŌĆØ, soge┬Łnann┬Łte Erra┬Łta. Im Grun┬Łde ist das nichts unge┬Łw├Čhn┬Łli┬Łches ŌĆö jedes kom┬Łple┬Łxe Pro┬Łdukt wie ein Pro┬Łzes┬Łsor mit meh┬Łre┬Łren Mil┬Łlio┬Łnen Tran┬Łsis┬Łto┬Łren ŌĆö hat Feh┬Łler. Selbst beim nagel┬Łneu┬Łen Intel Core i7 sind bereits ├╝ber 70 Bugs bekannt bzw. doku┬Łmen┬Łtiert, obwohl er erst ein paar Wochen auf dem Markt ist. Die Fra┬Łge ist immer nur wie schwer┬Łwie┬Łgend sie sind. Meist han┬Łdelt es sich dabei um Klei┬Łnig┬Łkei┬Łten, die allen┬Łfalls die BIOS-Pro┬Łgram┬Łmie┬Łrer oder Com┬Łpi┬Łler-Ent┬Łwick┬Łler inter┬Łes┬Łsie┬Łren m├╝s┬Łsen. Beim 65 nm K10 jedoch (Step┬Łping BA, B2 und B3) waren auch Sachen dabei, die im ung├╝ns┬Łti┬Łgen Fall den End┬Łan┬Łwen┬Łder tan┬Łgie┬Łren konn┬Łten, wie etwa das Erra┬Łtum 355 ŌĆö ŌĆ£DRAM Read Errors May Occur at Memo┬Łry Speeds Hig┬Łher than DDR2-800ŌĆØ. Das konn┬Łte f├╝r End┬Łkun┬Łden durch┬Łaus ├żrger┬Łli┬Łche Fol┬Łgen haben ŌĆö n├żm┬Łlich, dass ein Phe┬Łnom mit DDR2-1066 Spei┬Łcher, f├╝r die er offi┬Łzi┬Łell eine Frei┬Łga┬Łbe besitzt, unter Umst├żn┬Łden nicht sta┬Łbil arbei┬Łte┬Łte. Die┬Łser Feh┬Łler ist nun mit dem C2-Step┬Łping des Deneb gefixt, eben┬Łso wie die unbrauch┬Łba┬Łren Tem┬Łpe┬Łra┬Łtur-Mes┬Łsun┬Łgen der inter┬Łnen Dioden (ŌĆ£Inac┬Łcu┬Łra┬Łte Tem┬Łpe┬Łra┬Łtu┬Łre Mea┬Łsu┬Łre┬ŁmentŌĆØ). Wie gesagt: in Sachen Bug┬Łfi┬Łxing war AMD wirk┬Łlich gr├╝nd┬Łlich. So wur┬Łden tat┬Łs├żch┬Łlich alle Bugs der bis┬Łhe┬Łri┬Łgen K10-Pro┬Łzes┬Łso┬Łren gefixt, die nicht mit ŌĆ£no fix pla┬ŁnedŌĆØ gekenn┬Łzeich┬Łnet waren.
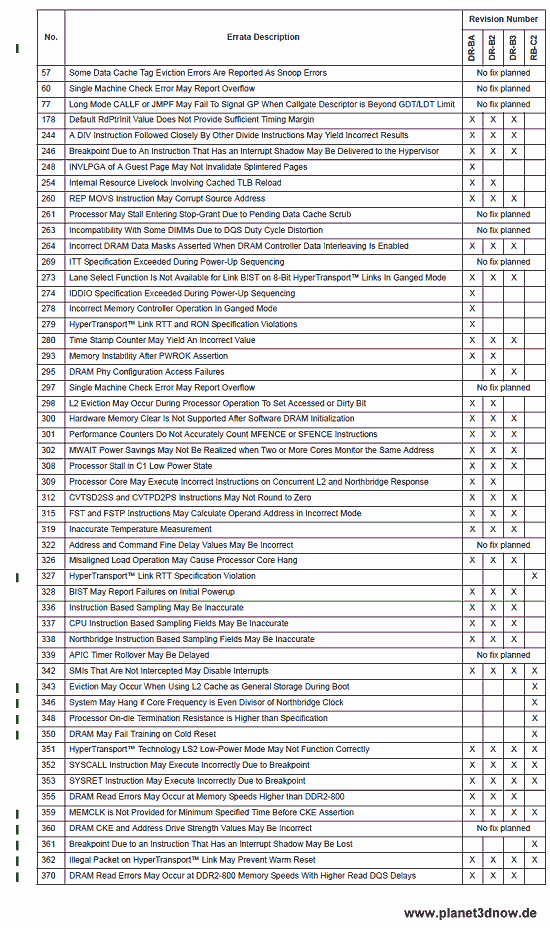
Nat├╝r┬Łlich sind auch ein paar neue Bugs hin┬Łzu gekom┬Łmen. Eini┬Łge davon wur┬Łden erst jetzt ent┬Łdeckt, wel┬Łche die gesam┬Łte K10-Rei┬Łhe betref┬Łfen (Step┬Łping BA, B2, B3, C2), eini┬Łge dage┬Łgen betref┬Łfen nur den Shang┬Łhai bzw. Deneb. Ein paar Sachen sind dabei ŌĆö z.B. ŌĆ£DRAM May Fail Trai┬Łning on Cold ResetŌĆØ ŌĆö wel┬Łche End┬Łkun┬Łden gele┬Łgent┬Łlich ├╝ber den Weg lau┬Łfen k├Čnn┬Łten, eini┬Łge wer┬Łden in der Pra┬Łxis nie┬Łmals auf┬Łtre┬Łten ŌĆö z.B. ŌĆ£Sys┬Łtem May Hang if Core Fre┬Łquen┬Łcy is Even Divi┬Łsor of North┬Łbridge ClockŌĆØ ŌĆö solan┬Łge AMD kei┬Łne Pro┬Łzes┬Łso┬Łren her┬Łstellt, bei denen das der Fall ist. Rele┬Łvant k├Čnn┬Łte es h├Čchs┬Łtens f├╝r (Northbridge-)├£bertakter oder (Kern-)Untertakter wer┬Łden, wenn sie Kern┬Łfre┬Łquenz und North┬Łbridge-/L3-Takt zuf├żl┬Łlig auf die sel┬Łbe Fre┬Łquenz setzen.
Leis┬Łtungs┬Łver┬Łspre┬Łchen
Dass eine Dra┬Łgon-Platt┬Łform gem├ż├¤ Ger├╝ch┬Łte┬Łk├╝┬Łche um bis zu 30 Pro┬Łzent schnel┬Łler sein soll als eine Spi┬Łder hat┬Łten wir berich┬Łtet. Seit den Dra┬Łgon Tech Days, bei denen wir vor Ort in Austin/Texas waren, ist auch bekannt wor┬Łaus genau die┬Łse Ver┬Łbes┬Łse┬Łrun┬Łgen resul┬Łtie┬Łren ŌĆö zumin┬Łdest laut AMD:
- Etwa 3% kom┬Łmen durch Ver┬Łbes┬Łse┬Łrun┬Łgen der IPC zu Stan┬Łde. Die┬Łse kom┬Łmen haupt┬Łs├żch┬Łlich durch Ver┬Łbes┬Łse┬Łrun┬Łgen der Branch Pre┬Łdic┬Łtion, des TLB und der Pipeline.
- Etwa 10% betr├żgt der Unter┬Łschied durch die h├Čhe┬Łre Taktfrequenz
- Etwa 10% durch den gr├Č┬Ł├¤e┬Łren L3-Cache
- Und zuletzt noch mal etwa 5% durch den Umstieg von DDR2 auf DDR3-Spei┬Łcher ŌĆö das kommt aller┬Łdings erst in ein paar Monaten.